
![[LuisaP💖] ANOTHER WAY TO MAKE LORAS 😡😡😡😖 Change-mind way to train LORA.](https://image.civitai.com/xG1nkqKTMzGDvpLrqFT7WA/3f57bd1a-fd3c-40ca-ba94-b7397520ac87/width=1320/3f57bd1a-fd3c-40ca-ba94-b7397520ac87.jpeg)
Give a credit of this article if you are making video/another article about this, i will love 💖.
Me(Luisa Caotica), Camenduru & kohya for the google colab, and artificialguybr for supporting me for giving time to help and making batch tests.
Some images don't have Metadata because i've used Fooocus MRE.
The first programmer in the world is a woman, this why programming is hard to understand💖.

Okay, okay... there isn't exactly the right way to do Loras.
but what I'm going to try to teach you might change your perspective on things, what i'm trying to say is... The Cake is a Lie.
Making Lora is not like baking cake, but a cupcake, you i'll get it.
[-First of all-] ❇️
I need to show you, my Loras, to give you a brief of what is going on,and show you what you can do.
yeah, hatkid.

are you asking for vanellope?
this is avaliable on civit right now:
https://civitai.com/models/152269/luisapsdxl-vanellope-20mb

this is what happens when i try another model, like copax timeless

i trained a "epinoiselike" lora using 2 darken images, with noise, this is the result.


works as well with artstyles.


this is a mix both loras.

i trained this on a foggy image, cool right?

yeah, the guy of my thumbnail, uganda knuckles.

works with any meme, and no, this is not a midjourney generation.

Nami, Emily Rudd.


Ayrton Senna.

sorry for that image, this is just funny for me.

you can train your friends and theirs cool different hairs.

this was trained on semkavkvadrate portraits



also, a random person shot by semkavkvadrate, well, i got some, 4 images, so.

Don't worry about the outfit, it's versatile.

valorant and arcane working as well.


idk why the 4th image fails, but i think that this is foocus issue.

do you know what they all have in common? 🤓
here's a list.
the dataset varies from 1 to 5 images.
they took less than 20 minutes to train.
they were trained with
1 dim, and 1 alpha4 dim, and 1 alpha.the file weighs no less than 20 fucking MB.
No one fucking believe that this can be real, you can be mocked by a youtuber idk 🥴
[-ABOUT THE 1DAI (1DIM 1ALPHA 1IMAGE)-] ❇️
this is actually a real thing, but only for styles.

but this test i made with a old setting using adaw with cosine.
also, constant with warmup can get rid of the likeness to make your output more versatile, change the warmup value closer to final steps if you want to sacrifice the likeness for originality/consistency.


you can play with concepts too ( i did a bad copy paste in the eyes in this one, so the ai learn this too, lmao)

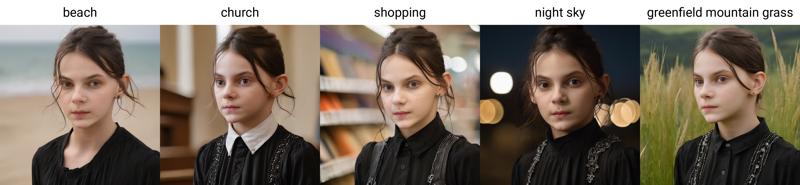
For people, obvious don't will work with 1 image, but still working with 1dim,1alpha. ( this dataset contain 4 images )
Fun fact: when you increase the strength to 2 with a Lora that has trained with only 1 image, the original image that is used for training will be showed, kinda cursed.

Original image:

Also, i have SDXL Loras that already is using 1dim,1alpha,1image, you can check here:
https://civitai.com/models/132610/luisapsdxl-disco-diffusion-5mb
https://civitai.com/models/133007/luisapsdxl-braces-inpainting-5mb
https://civitai.com/models/133010/luisapsdxl-eyes-inpainting-5mb
https://civitai.com/models/133012/luisapsdxl-freckles-inpainting-5mb
[-ABOUT THE P1S (PRODIGY 1 IMAGE-STYLE)-] ❇️
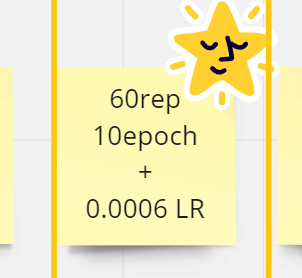
🌟🌟🌟When I was writing this, I remembered that I should test with Prodigy too, so I did the test, but with 4 dim, 1 alpha, 1 image, and the settings were, 60 repeats,10 epochs, cosine,1.6 dcoef ( I always reduce my dcoef to lower than 2 when I go to train style, because it can toast your lora )🌟🌟🌟
So i used this Nijijourney generated image, that is also edited in photoshop, i trained without caption.
Original image:

and the result is, well, it's really look like the style, but also, repetitive (the framing is perfect,cool).

Take a remind that i'm using 60 repeats.

Now i reduce the repeat to 40.

This is grabbing the Nijijourney-like style, and also reducing the repetitiveness, but losing the Likeness & Composition.

Now repeat to 50, as we can see, framing is back.

But at the end, this will grab more the style than the "visual concept effect" i want.
the training time is too short (10-20 min), this may help you make versions of 40,50,60 repeats, to see what is good for you.

So in this very specific case, as I want to train framing and effects, I would have to train using at least 4 different images, using another specific configuration for this, which I'll talk about below.
If you are training a STYLE, without any concepts, so that is already perfect for you, this can be advantageous if you only have 1 image from 1 existing artist.
ALSO, you can use this technique as a MEDIUM, to generate more dataset and train again with cherrypicked outputs.
By the way, i already have a custom dataset that i created with nijijourney.

[-NOW THIS IS GONNA BE VEEEERY WILD-] ❇️
So, the P1S method is bad for concept??
Well, YES, and NO....
Let's take an example, i generated this bunny with lightsaber, using Würstchen v2.

kinda cute huh? :3 , and i will train only this image, and with caption.
The problem is, i used 50 repeats for this, and the effect is so strong, that is needed to reduce the strength to 0.5.

For this, is 30 repeats, no need for strength reduction.

Now a test with same seed, fantasy style.
30 repeats / 1 strength.

50 repeats / 0.5 strength.

I find out that SDXL can't make flying bunnies, will generate something like this.

So i generated one in Würstchen v2 , and trained this image.

This is result generated by SDXL, after training.

You can also reuse the same Lora aesthetic concept for another subject.

Be careful, this method is very hard to MIX with another concept [ the light-saber strength is reduced by 0.2 and the flying 0.7 ]

As you can see above, some subjects is easy to train because don't require much details, because stable diffusion already KNOW what is the subject, is nothing new, is just a "FINE-TUNING" with only 1 Image.
So let think about things that stable diffusion already know...Sonic, if you try to generate Sonic on SDXL, you will see, well, Sonic... but, kinda distorted one.

Maybe Würstchen v2 can solve my problem??

Well, DALLE-3??

AAAAAAAAAAAAALRIGHT, Let's back to SDXL.
I will use only this render to train, and nothing more, NOTHING MORE (same config as the 🌟🌟🌟 above)!

Also, i'm using 0,6 strength in this case because the repeat is kinda strong, if i try the 1 strength, will force Sonic to original image pose, like this.
This is literally a exact copy without the ring lmao.

lowering the dcoef to 1.2 or something don't will solve too.
also, this make me think..... why low dcoef makes the pose more stronger??

nah, is just my mind thing, high dcoef like 2.5 do same thing and even worse, because makes more distortions.

Also, i'm not into less repeat like 30 because this make my image look less like the original image and also weird.

40 Repeat also is Meh, even less epoch can't help.

So, let see now, the result. 0,6 strength [ 60 rep, 1.6 dcoef, 10 epoch, 1 image ] Wow, sexy hehe....

Also there a problem, is hard to put stuff into sonic, like glasses.

Why he is so tinny here? 😭

Some tests with 0.5 strength [ 60 rep, 1.2 dcoef, 10 epoch, 1 image ]


The default pose is here guys


At least, it's working right? but i need to tell you something,IF YOU HAVE A OPPORTUNITY, to find 4,5 images, train with that number, will be a way BETTER than 1.
You don't even need to crop.



MY FAVORITE?: So for faces and things at general, 4 dim 1 alpha, with only 4 images, also, no reg(piercings and tattoo still producing weird artifacts.)
Ps: My face. [Mod Note: Removed for Real-person Likeness]

That's why i start gnashing my teeth in anger when i see a 100,200 mbs lora. 😤
[-I'M TALKING SERIOUS!!!!-] 😡😡😡❇️
loras bigger than 100 mb don't even make sense for me.
+100MBtrainer: but i need the sharp skin details eyes everything.
LuisaPinguin: Let me talk about one real thing, this is my Ayrton Senna Lora, and we can see a real problem here, the soft skin.

feel like plastic, and is very noisy.

+100MBtrainer: AHA!, gotten!!, real shit.
LuisaPinguin: And this is because i'm using Euler A, but what happens when i use 2m sde exponential or 3m sde exponential?


+100MBtrainer: Oh the misery, everybody wants to be my enemy
LuisaPinguin: If you still seeing noises, you can still free to adjust the dim for 6,8, idk, will still under 100mb.
LuisaPinguin: also, LOOK AT MY TREX LORA THAT IS 4 DIM 1 ALPHA 20 MB RAWWWWW :3



+100MBtrainer: Please end my suffering :(

also, sorry if u got offended uwu......
[-This don't comes from NOTHING!-]❇️
The idea of using Loras with 1,4 dim has been in my head since stable 1.5 (you can see my 1MB Loras for 1.5 in my profile), and I was trying to adapt this thing for SDXL, but it was very challenging. There were hundreds of trials and errors, numerous files on my PC, and a lot of false positives.
What's even worse is that I don't have a good GPU (GTX 750 Ti 2GB), so I'm using Google Colab all day and modifying the Colab code to bypass Google's block.
I spent months and weeks trying to bring back the "perfect" configuration, and finally, it's time.
In October, I found that Civit has training for supporter members. I tried it, but they don't have some configurations that I need for my "setup," and I'll talk about that now.
you can train with more images, but balance that with your repeat to not make things stronger.
some of the most know problems is that this training has high fidelity with the style of the original image.
for example, the most recent character, Astarion from baldurs gate 3.

when you try to render at full Weight, this will give you a 3D looking character, because, originally, is a 3D character.

so you need to reduce the Weight ,this will prioritize the realism, but at same time, will lose some minors characteristic .
[-THE DATASET REALLY MATTERS-]❇️
Things can get really messy here because we're currently training with a very short dataset.
Please pay attention to these details:
If you're training a model on a specific person or subject, the background can be easily learned, so it's highly recommended to remove it.
this is how i make my dataset (closeup, some chest shot, and a slight dark image). 🎃🎃
Too many close-ups can be problematic. If you only have close-up shots in your dataset, you can try outpainting or roop to make the face appear more distant from the camera to make your dataset versatile. Having one or two non-close-up images can be helpful.
even with background removed, you can see that my face is getting too close to camera
If your dataset contains only bright images, it can result in uncreative outputs. Having at least one dark or slightly darkened image can improve the diversity of your dataset. If you only have bright images, you can reduce the image exposure by 20-50%, and this may work.
This is a test that I conducted. Don't worry too much about the quality of the Civit upload. Just take a look at the image's brightness. The prompt was about a "woman in a dark forest" and well, where is the darkness when I increase the Lora strength?
now, this is trained with dataset whit 3 bright images, and 1 dark image.
This is using the dataset above that i tagged with. 🎃🎃.
[-2024, is near end of 2024 and i remembered that this article exists, so i will post here, but i don't remember my configs, sorry i will try to find. -]❇️
I'm working on this article since 2023 sept, and, well, this is a long time since now, people change, tries new things, and, evolve.
Consider donating to my ko-fi to see more advancements and stuff like this.