

train style embeddings for only 225 steps in Automatic1111
you can use pictures without captions
For train you need to use basic model v1-5-pruned-emaonly.ckpt
8-12 token weight for new created embedding
in TRAIN tab next key options
weights:
0.008:25,
0.001:50,
0.008:75,
0.001:100,
0.008:125,
0.001:159,
0.008:175,
0.001:200,
0.008:225,subject_style.txt file for training
style elements and details, lightings and environment by [name]
visual effects, line and color palette by [name]time for "catch style" just for 3-5 minutes.
example dataset for style catching.
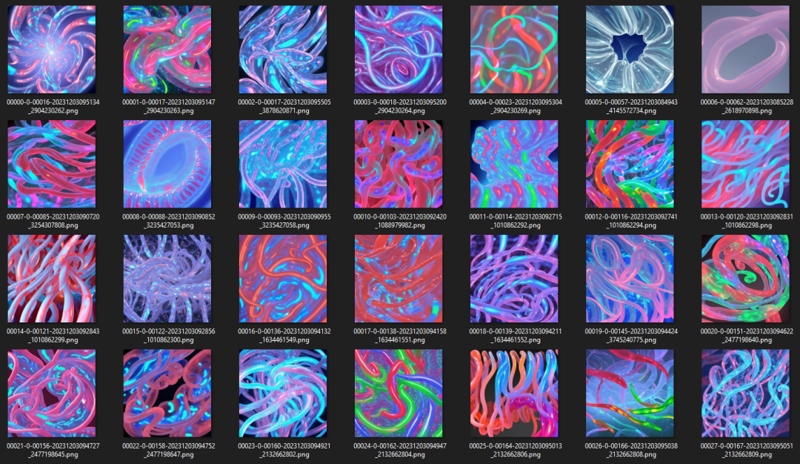
example of results (LCM model, simple prompt without improvments by neg and pos prompts )
Tiakilnora in (styled by EMBEDDING: weights from -2 to 2 ) standings on the street