


How to Extract LoRA from FLUX Fine Tuning / DreamBooth Training Full Tutorial and Comparison Between Fine Tuning vs Extraction vs LoRA Training
Details
As you know I have finalized and perfected my FLUX Fine Tuning workflow until something new arrives
It is exactly same as training LoRA just you load config into the DreamBooth tab instead of LoRA tab
Configs and necessary explanation are shared here : https://www.patreon.com/posts/kohya-flux-fine-112099700
Currently we have 16GB, 24GB and 48GB FLUX Fine-Tuning / DreamBooth full check point training configs but all yields same quality and just the training duration changes
Kohya today announced that the lower VRAM configs will get like 30% speed up with Block Swapping technique algorithm improvements, hopefully
It has been commonly asked of me how to extract LoRA from full Fine-Tuned / DreamBooth trained checkpoints of FLUX
So here a tutorial for it with comparison of different settings
In this post, Image 1–5 are links to full images so click them to see / download
How To Extract LoRA
We are going to use Kohya GUI
How to install it and use and train full tutorial here : https://youtu.be/nySGu12Y05k
Full tutorial for Cloud services here : https://youtu.be/-uhL2nW7Ddw
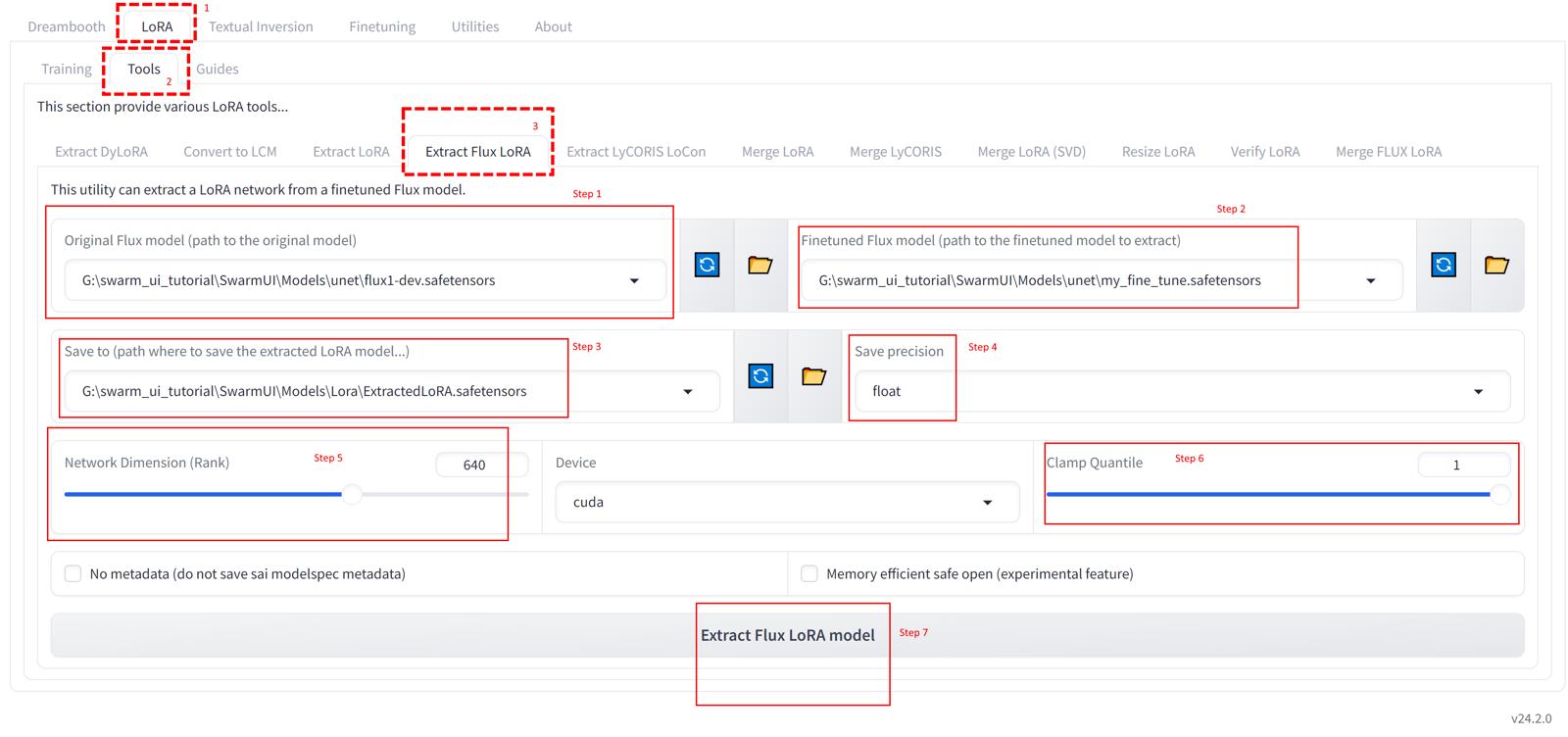
The default settings it has is not working good
Thus look at the first image shared in the gallery and set as it is to extract your FLUX LoRAs from Fine Tuned / DreamBooth trained checkpoints
Follow the steps in as in the Image 1
So you what can change?
You can change save precision to FP16 or BF16, both will halve the size of the saved LoRA into disk
Are there any quality difference?
You can see comparison in the Image 2 and I didn’t notice any meaningful quality difference
I think FP16 is more close to FP32 saving
Another thing you can change is setting Network Dimension (Rank)
It works as much as up to 640 and above gives error
The more the Rank you save, it is more closer to the original Fine Tuned model, but it will take more space
You can see Network Dimension (Rank) comparison in the Image 3
How To Use Extracted LoRA
I find that giving 1.1 strength to extracted LoRA makes it more resembling to the original Fine Tuned / DreamBooth trained full checkpoint when Network Dimension (Rank) is set to 640
You can see full LoRA strengths comparison in Image 4
If you use lower Network Dimension (Rank), you may be need to use higher LoRA strength
I use FLUX in SwarmUI and here full tutorial for SwarmUI
Main tutorial : https://youtu.be/HKX8_F1Er_w
FLUX tutorial : https://youtu.be/bupRePUOA18
Conclusions
With same training dataset (15 images used), same number of steps (all compared trainings are 150 epoch thus 2250 steps), almost same training duration, Fine Tuning / DreamBooth training of FLUX yields the very best results
So yes Fine Tuning is the much better than LoRA training itself
Amazing resemblance, quality with least amount of overfitting issue
Moreover, extracting a LoRA from Fine Tuned full checkpoint, yields way better results from LoRA training itself
Extracting LoRA from full trained checkpoints were yielding way better results in SD 1.5 and SDXL as well
Comparison of these 3 is made in Image 5 (check very top of the images to see)
640 Network Dimension (Rank) FP16 LoRA takes 6.1 GB disk space
You can also try 128 Network Dimension (Rank) FP16 and different LoRA strengths during inference to make it closer to Fine Tuned model
Moreover, you can try Resize LoRA feature of Kohya GUI but hopefully it will be my another research and article later
Image Raw Links
Image 1 : https://huggingface.co/MonsterMMORPG/FLUX-Fine-Tuning-Grid-Tests/resolve/main/Image_1.png
Image 2 : https://huggingface.co/MonsterMMORPG/FLUX-Fine-Tuning-Grid-Tests/resolve/main/Image_2.jfif
Image 3 : https://huggingface.co/MonsterMMORPG/FLUX-Fine-Tuning-Grid-Tests/resolve/main/Image_3.jfif
Image 4 : https://huggingface.co/MonsterMMORPG/FLUX-Fine-Tuning-Grid-Tests/resolve/main/Image_4.jfif
Image 5 : https://huggingface.co/MonsterMMORPG/FLUX-Fine-Tuning-Grid-Tests/resolve/main/Image_5.jpg



