
Following the success of my first article analyzing community-generated data on CivitAI, I am excited to continue this series with a deeper look into my personal remixing habits. In this second article, I dive into a dataset of 485K records representing the images I have remixed and explored. While the previous article focused on broader community trends, this analysis offers a unique perspective on my own workflow, preferences, and patterns when recreating and tweaking community images. From parsing community data to adjusting prompts and running models, this article provides an in-depth view of how I approach AI image generation. Through this analysis, I hope to uncover insights into my creative process and highlight the differences between personal and community-driven trends.
Dataset Analysis:
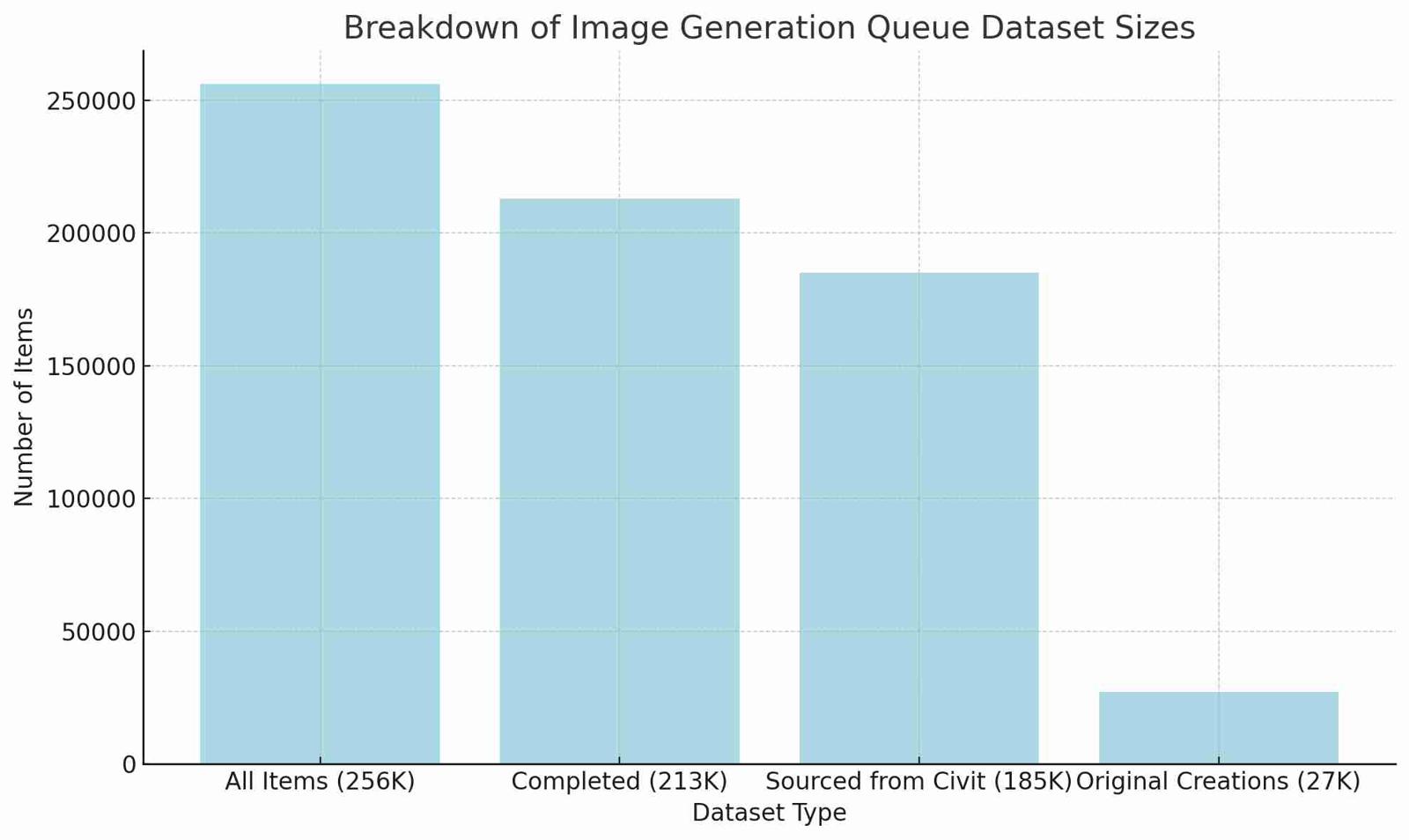
In total, there are 256K items in the image generation queue, representing both pending and completed items. Among these, 213K items have been completed, which includes both sourced content and original creations. Of the completed items, 185K are sourced from CivitAI, while 27K represent original creations generated directly within the system. This shows that about 87% of the completed items are externally sourced, while the remaining 13% are original creations. The overall ratio of generated images to sourced items stands at approximately 2:1, which gives a clear picture of my remixing habits and system behavior.
In this article, we'll be exploring the 256K dataset. While the 485K dataset size reflects the total number of images generated, this includes cases where multiple images were produced from the same base generation due to batch processing. To maintain clarity, we're focusing on the 256K dataset size, as counting each batch individually would overrepresent the underlying generative items.
In reviewing both the original and sourced content, we see that the most frequently used model across the sourced content datasets is ponyDiffusionV6XL, which stands well above the rest in terms of popularity. This makes sense given its versatility and high-quality outputs as well as it's prominence in the community. However, what’s particularly interesting is how many of the models I use frequently for local creations are not available for use online.
Of the models from the top 10 lists, only five are accessible online: aaaautismPonyFinetune, autismmixSDXL_autismmixPony, everclearPNYByZovya_v2VAE, ponyDiffusionV6XL, and tPonynai3_v41OptimizedFromV4. In total, only 5 models from both my top 10 lists can be used online. From the original content, there are 3 models available online, while 4 models from the sourced content list are also available for public use.
It's also worth noting the prominence of sorkhPony_v20, which stands out as the second most used model across both original and sourced creations. This highlights my strong affinity for the unique style and images it generates, showing how it rivals even ponyV6 in my personal workflow for AI-generated image creation.
 CFG Scale & Steps Analysis:
CFG Scale & Steps Analysis:
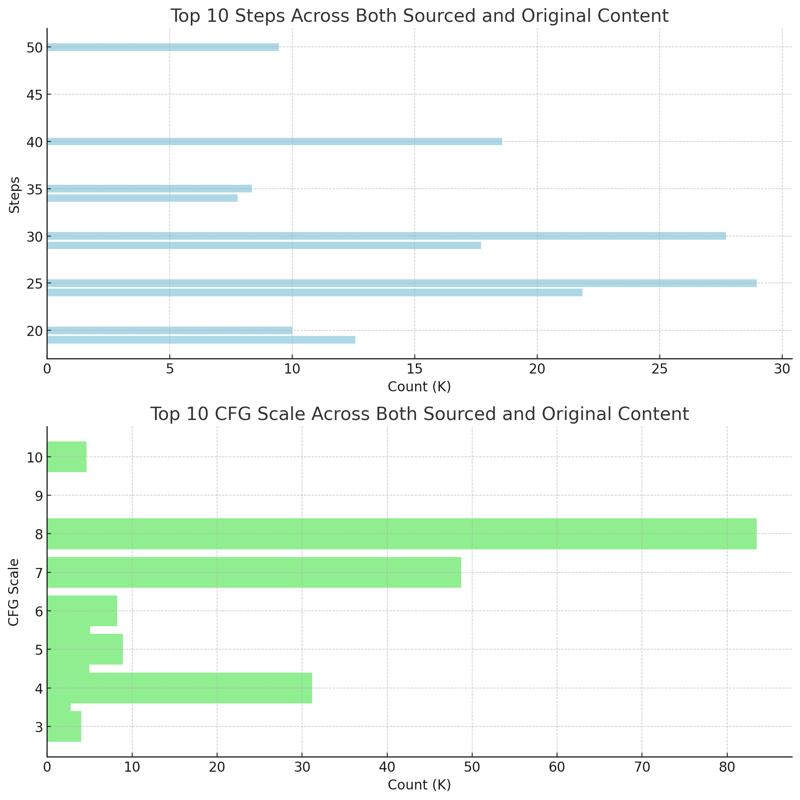
Whereas the first article focused on raw community data, this dataset reflects a more controlled process, where defaults come into play when certain parameters are missing or unavailable. For instance, if the cfg_scale isn't extracted from the sourced content, I default it to 8.0, which explains why it leads the chart by a significant margin. Similarly, the 25 steps setting is a fallback when the step count is unknown in sourced creations, contributing to its high usage.
Interestingly, although my local interface doesn't have stepped sliders for input, the majority of my remixes are sourced from CivitAI content, where steps are often designed to be in multiples of 5. This design tendency clearly carries over, as we see steps like 25, 30, 20, and 50 dominating the chart. These patterns reflect a user interface decision on CivitAI's part that encourages round numbers, influencing the original creations I work with.
Finally, it's notable how 50 steps remains popular, indicating that creators often see it as the ideal upper threshold for generating high-quality images. Meanwhile, 24 and 30 steps stand out as median values that balance image generation speed with quality, effectively doubling when users aim for higher refinement in their creations. This suggests that creators tend to double their steps to achieve finer image results, with 50 steps being a common choice for enhanced outputs.
 Samplers Analysis:
Samplers Analysis:
- Euler Ancestral Usage:
- In my personal generations, Euler Ancestral accounts for approximately 86.47% of all generations, highlighting a strong reliance on this sampler.
- For the community, Euler Ancestral is used about 58.04% of the time, still dominant but with significantly more variety compared to my personal workflow.
- DPM++ 2M Usage:
- In my dataset, DPM++ 2M represents only 5.17% of the total sampler usage, making it a much less frequent choice.
- In contrast, the community uses DPM++ 2M about 28.15% of the time, showing a greater balance between Euler Ancestral and DPM++ 2M compared to my usage.
- Deviation in Sampler Preference:
- The order of popularity for samplers between my local generations and the community is nearly identical for the top four spots. However, the key deviation happens at 5th place:
- The community prefers DDIM, while in my local generations, DPM++ 2M SDE GPU takes the 5th spot. This shows a shift in experimentation beyond the top choices, with the community leaning more toward DDIM and my workflow favoring GPU-accelerated samplers like DPM++ 2M SDE GPU.
This comparison highlights how both I and the community strongly favor Euler Ancestral, but with differing levels of reliance on other samplers like DPM++ 2M and DDIM.
Prevalent Use of Euler_Ancestral
The difference between DPM and Euler samplers plays a significant role in the way details are rendered in generated images. DPM samplers, known for producing sharp and high-quality details, excel at handling specific areas like eyes and faces. However, they can also introduce unwanted artifacts, such as green splotches, especially in scenarios where certain step sizes and multiple Loras are involved. This artifacting issue arises because DPM samplers tend to push for extreme detail, which, when combined with more complex setups, can lead to inconsistencies. On the other hand, Euler samplers take a more balanced approach, delivering consistent, middle-ground quality without overemphasizing key details, making them less prone to such artifacting. Because of this, I’ve developed a process where, if certain DPM samplers are detected, I automatically switch to Euler Ancestral to avoid the artifacting issues. This decision reflects my preference for a more stable and predictable output, minimizing the risk of unwanted elements in the image, and explains why my personal images lean so heavily on Euler Ancestral.
Here is the chart displaying the top 10 most popular models used for both Loras and Embeddings in my generations, with the counts represented in "K" format and the file extensions removed for clarity.
Analysis of Number of Loras and Embeddings Used:
In terms of Loras, it is clear that using 3 to 5 models is the most common practice in my image generation process, with the most popular number of Loras being 4. There is a sharp drop-off beyond 5 Loras, and using 6 or more is far less common. This reflects a tendency to balance complexity and efficiency in your workflow, where around 3 to 5 Loras models are likely optimal for producing quality results without over-complicating the generation.
For Embeddings, it's interesting to note that having just 1 embedding is extremely rare. This can likely be attributed to the CivitAI source data, where enabling the mature filter automatically includes 2 embeddings (one positive and one negative). Therefore, the most common configurations involve 0, 2, or 3 embeddings. While 3 embeddings are slightly more prevalent, it's a relatively even split between 0, 2, and 3 embeddings, suggesting that when the filter is enabled, users often add an extra embedding to fine-tune their generations.
 Loras & Embedding Models Analysis:
Loras & Embedding Models Analysis:
When comparing the models used in my personal image generations with those most frequently used by the community, there are some striking similarities as well as notable differences. Here’s a breakdown of the findings:
Oddball Models:
- Loras:
- In my dataset, the model Lilandava_PDXL made it into the top 10, whereas it doesn’t appear in the community’s top 10.
- In the community’s dataset, PerfectEyesXL is present, but it does not make an appearance in my top 10.
- Embeddings:
- In my dataset, SimpleNegativeV3 and zPDXLrl appear, both of which are missing from the community’s top 10.
- In the community’s dataset, fcNeg-neg appears, which doesn’t show up in my top 10 embeddings.
These “oddball” models reflect some divergence between my workflow and the community’s preferences, with Lilandava_PDXL and SimpleNegativeV3 being personalized additions to my generation process. The community’s reliance on models like PerfectEyesXL and fcNeg-neg suggests a broader variety of artistic styles or goals that differ from mine.
Order of Popularity & Deviations:
- Loras:
- The top four Loras models—**Expressive_H-000001**, g0th1cPXL, incase_style_v3-1_ponyxl_ilff, and princess_xl_v2—are identical in both datasets in terms of popularity. This highlights how much my preferences align with the community, particularly for pony or stylistic generations.
- The first deviation occurs in 5th place: for me, add-detail-xl is slightly less popular than in the community dataset, where it ranks 2nd.
- Further down the list, Concept Art Twilight Style SDXL ranks similarly across both datasets, but models like Lilandava_PDXL (mine) and PerfectEyesXL (community) highlight the divergence at the lower end of the list.
- Embeddings:
- The top three embeddings—**safe_neg**, safe_pos, and easynegative—are the same in both my and the community’s dataset, with a similar ranking order.
- The deviation begins after the third spot, where civit_nsfw is more popular for the community, but slightly less prevalent in my dataset.
- zPDXL2, FastNegativeV2, and negative_hand-neg are common between both datasets, but the presence of zPDXLrl and SimpleNegativeV3 in my dataset reveals that I manually add some embeddings to my pipeline, which explains their prominence. These embeddings aren’t as frequently used in the community, indicating my customized approach to image generation.
Manual Embedding Additions:
Many of the embeddings like zPDXLrl and zPDXL2 that show up in my top 10 are manually added to my image generation pipeline. This explains why they are present in my dataset but not in the community’s top 10. These models, manually curated and tweaked, reflect a more personalized approach in my workflow, where I aim for specific outcomes based on the needs of the generation. This manual addition of certain embeddings likely accounts for the deviation in popularity rankings after the top three.
This comparison highlights both my alignment with the community on certain models and tools while also reflecting the personalized modifications I’ve made to optimize my image generation process.
 Average Prompt Length
Average Prompt Length
When comparing my prompt lengths to those of the broader community, a clear trend emerges. While the community's lower percentile sits at 48 words, mine is notably higher at 55 words. This shows a tendency for me to craft longer prompts, or for the prompts to be automatically recrafted into longer prompts, even at the lower end of the spectrum. My middle percentile also follows this trend, with 61 words, just above the community's 60 words. This tight alignment with the community's mid-tier prompts indicates that my prompts are often more detailed or expanded, even in cases where the community might favor shorter descriptions.
The most interesting deviation comes at the higher percentile. My top prompts average 85 words, which is 7 words longer than the community's 78 words in the upper percentile. This suggests that I tend to push for more detailed or nuanced prompt lengths when compared to the broader CivitAI community, especially at the higher end of the spectrum, where I favor adding more complexity or specificity in my descriptions. This difference further highlights my tendency to modify and extend prompts beyond what is typically seen in the community.
 Most Popular Positive Prompt Words Analysis:
Most Popular Positive Prompt Words Analysis:
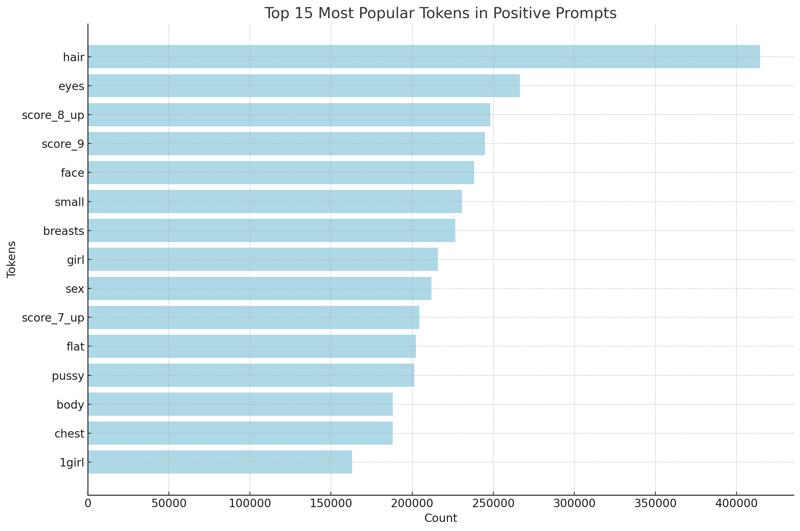
The chart above highlights the top 15 most frequently used tokens in my positive prompts. It shows a clear pattern in the types of descriptions and elements that tend to appear in my image generations. The most popular tokens like hair, eyes, and face indicate a strong focus on defining specific facial and body features in the images, pointing to a high level of detail in character design.
Tokens such as small, breasts, and flat suggest a recurring theme related to body proportions, while girl and 1girl point toward generating images featuring single female characters. The presence of sex in the list aligns with other body-focused tokens, reflecting a mature theme in many generations.
What's particularly interesting are the score_ tags, such as score_8_up and score_9, which are unique to pony-based models. These tags are used to define the aesthetic quality of an image, with 9 being the highest and 7 typically marking the lowest positive rating. The frequent appearance of these tags shows a tendency to aim for higher aesthetic scores, striving for visually pleasing outcomes with a detailed focus on quality and composition.
Overall, this analysis reveals a consistent pattern in my generation prompts, where detailed facial and body features, coupled with a high focus on aesthetic quality, are the core themes driving my creative output.
Most Popular Parameters:
- Checkpoint:
- 1st: ponyDiffusionV6XL_v6StartWithThisOne
- 2nd: sorkhPony_v20
- Steps:
- 1st: 25 steps
- 2nd: 30 steps
- CFG Scale:
- 1st: 8.0
- 2nd: 7.0
- Sampler:
- 1st: Euler Ancestral
- 2nd: DPM++ 2M
- Loras:
- 1st: Expressive_H-000001
- 2nd: g0th1cPXL
- Embeddings:
- 1st: safe_neg
- 2nd: safe_pos
- Prompt Lengths:
- 1st (Lower Percentile): 55 words
- 2nd (Mid Percentile): 61 words
- Positive Prompt Tokens:
- 1st: hair
- 2nd: eyes
Conclusion:
This second article in my data analysis series has provided valuable insights into my personal remixing habits, showcasing how my workflow, preferences, and generation tendencies align and deviate from broader community trends. While ponyDiffusionV6XL remains a dominant model for both my creations and the community's, my heavier reliance on Euler Ancestral and slightly more detailed prompts highlight a more personalized approach in my image generation process. The frequent appearance of specific tokens like hair, eyes, and score_ tags indicates a focus on detailed facial and body features, with a strong emphasis on high aesthetic quality. This analysis has shed light on how my workflow leverages community models while still making personalized adjustments to achieve the desired creative outcomes. As I continue exploring AI-generated imagery, these findings will help refine my approach to better balance efficiency, quality, and creativity.