


Style IPAdapter Finetune for NoobAI-XL
This is a personal experiment to finetune the NoobAI's IP-Adapter to transfer drawing style, instead of subjects and compositions, from the reference image.
It doesn't always work as well as expected, and I don't know how to further improve it besides gathering more data. (Also, one-image lora is quite viable nowadays). So I decided to release it as a toy model for style exploration.
The adapter is finetuned from NoobAI's IP-Adapter Mark 1 on base model NoobAI-XL EPS V11.
3/11/2025 Extension Update: Add support for Forge.
2/12/2025 Extension Fix: Someone reported a bug about the extension only working in ReForge's dev branch. If you have problem with the extension on ReForge's main branch, please either update the extension or switch to dev branch.
How To Use
Note: To capture finer details, the adapter is finetuned with a patched version of CLIP-ViT-bigG, using 448x448 input size instead of the original 224x224. Hence, you will need my custom extension to run it properly. The extension reuses the official CLIP-ViT-bigG (the one NoobAI's ip-adapter uses) and apply the patch at run time, so you don't have to download an additional model if you already have it.
Forge/ReForge WebUI
Download the ip-adapter safetensor and put it under
<ReForge_Install_Path>\models\ControlNetInstall this extension for CLIP-ViT-bigG-448 and restart UI.
Under ControlNet panel, choose
CLIP-ViT-bigG-448 (IPAdapter)from the Preprocessor list and choose the style adapter from the model list.Upload reference image and optionally enable perfect pixel for large ref images.
Prompt and generate!

ComfyUI
Download the ip-adapter safetensor and put it under
<ComfyUI_Install_Path>\ComfyUI\models\controlnet. (If you also have ReForge, you can just put it in Reforge's controlnet folder and link ComfyUI to it.)Install this extension and restart UI.
Use
Extend Clip Vision Input Sizenode andIPAdapter Advanced (Clip Size Aware)node: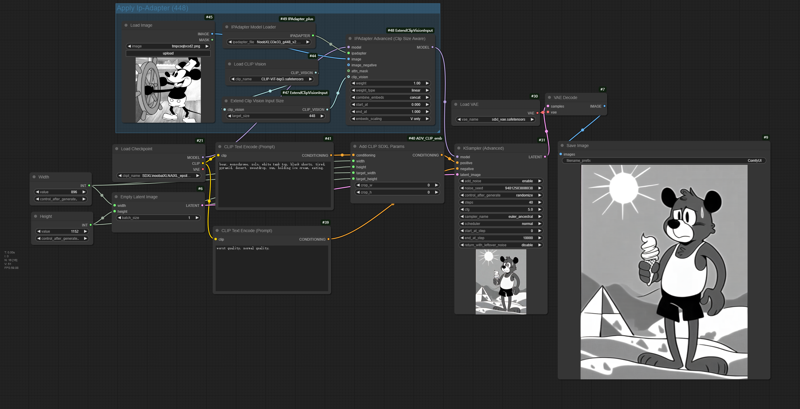
Comparison

Tips
Prompt normally first. Then use tags related to the target style to enhance or mix.
Crop and resize the ref image on another software first, especially when the subject is not at the center or is relatively small. The rule of thumb is to make the style still clearly perceptible after resizing the ref image to a 448x square. For a vertical full-body image, I suggest crop it to a half-length/bust portrait.
Quality tags might influence the style for better or worse, depending on whether the target style is clean.
If there are composition leaks, it should be easier for this adapter to overwrite/remove the composition with positive/negative prompt than the original one.
Though some artists' style has certain composition bias, for example chibi. This adapter doesn't necessarily capture those as a part of the style. Please use related tags like
chibi,cuteif needed. The same goes for things likedot eyes.Advanced use: Combine it with the original adapter, artist tags, prompt edit and/or apply the adapter only for a part of the sampling schedule.
You can generate some random images with empty positive first to see what the adapter captures from ref image.
Limitation
only imitate general executional styles like lines and shading techniques, not facial/body anatomy.
doesn't capture well for:
styles based on compositions/materials, for example a photo of sculpture would give you smooth semi-realism shading instead of an actual sculpture. (use
sculpture \(artwork)and remove color related tags might help)highly detailed style like hyper realism.
abstract style with abnormal anatomy/ambiguous shapes.
hallucinate certain style element combinations. For example, mistake some smooth shading 2d arts as 3d arts.
also transfers jpeg grains, blurriness, noise pattern.
The training dataset is furry dominant, not sure how it impacts the anime side variety.