[Tips]The impact of prompt order on result generation. 关于提示顺序对结果生成的影响. Promptの順番によって生成した画像に与える影響について
364
601
12
Updated: Oct 5, 2024
exampleDownload
1 variant available
fp16 SafeTensor
zeroTwo02DarlingInThe_v10.safetensors
Half precision, best balance • 144.11 MB
Verified: 3 years ago

30
364

Attention!!! PLEASE READ TEXT BELOW!!!
中文版往下翻
日本語のバージョンは下へどうぞ
the lora model upload here is not created by me, but by jappww (https://civitai.com/user/jappww).
the reason I upload here just for example cuz I found this impact when I was trying to use his zero two 02 model.
The following content may already be known to many of you, but I would like to briefly introduce the impact of prompt order on results to many people who are still unaware of this information.
The conclusion is that the arrangement order of prompts has a significant impact on the image output results (especially in Hires.Fix mode).
Then I will provide some example to explain what I'm saying.
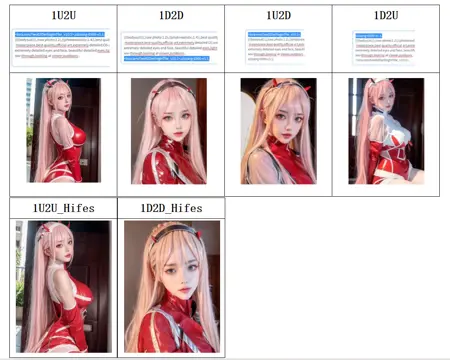
All the pictures will be shown below are generated by same parameters and same seeds except prompt order.
It can be seen that when the appearance-related prompts are placed at the bottom (1D2D), the image generated by Hires.Fix is very different from the original image, while placing the appearance-related prompts at the top (1U2U) retains a relatively high correlation between the generated image and the original image.
It is evident that in picture generation(especially in Hires.Fix mode), the order of prompts has a remarkable impact on the output results. When appearance-related prompts are placed at the beginning, the generated image has a high relevance to the model. However, when they are placed at the end, Hires.Fix will refine based on the initial 8K and 4K keywords, resulting in a significantly different appearance from the original image before processing.
This leads to the conclusion that when using a LoRa model related to appearance, especially in Hires.Fix mode, it is best to place all LoRa models related to appearance at the beginning. Personally, I suggest the following order:
The LoRa model of a specific character, such as the Zero Two LoRa model in this example.
Overall optimization models, such as the famous ulzzang-6500 (https://civitai.com/models/8109/ulzzang-6500-korean-doll-aesthetic), xxdoll, etc.
The rest of the models sorted by importance.
I hope this tutorial will be helpful to you~ go create your own arts~
===========
2023/3/11
After being reminded by kmlau (https://civitai.com/user/kmlau), I found that the placement of the <Lora> model does not affect the image generation results. That is, when stable diffusion reads the prompt, it will treat the six characters "<", "l", "o", ..., ">" as blank spaces. However, it is important to note that any other symbol, such as "<lora>,"(the comma) will affect the generation of results.
For example,
<lora>prompt_A, prompt_B, prompt_C,
and
prompt_A, prompt_B, prompt_C, <lora>
and
prompt_A<lora>, prompt_B, prompt_C,
and even
prompt_A, prom<lora>pt_B, prompt_C,
will all produce exactly the same results.
However,
<lora>prompt_A, prompt_B, prompt_C,
and
<lora>, prompt_A, prompt_B, prompt_C,
are different. The reason for the problem in the previous example(days ago) is that the comma in the prompt affects the final result generation, which is also why the change occurred in the previous example images.
Other than <Lora>, no significant problems were found with the other summaries, if there are other mistakes I found, I will continuedly edit it.
===========
==============================================
注意!!!请仔细阅读以下内容!!!
在这里上传的LoRa模型并不是我自己创建的,而是由jappww (https://civitai.com/user/jappww) 创建的。我在尝试使用他的Zero Two 02模型时发现了这种影响,因此在此仅作为示例上传。
太长不看版:
画图的时候把最重要的提示词放最前面(在本例中,是02的lora模型)。具体区别可以看图。
详细版:
下面的内容可能已经为你所知,但我想简要介绍一下提示词顺序对结果的影响,以便许多仍未意识到此信息的人了解。
结论是,提示词的排布顺序对图像输出结果有巨大影响(尤其是在Hires.Fix模式下)。
接下来我将提供一些示例来说明。
下面显示的所有图片都是使用相同参数和相同随机种子生成的,唯一不同的是提示词的排布顺序。
可以看到,在将人物外貌提示词放在最下面(即1D2D)的情况下,Hires.Fix生成的图片与原始图片差异很大,而将外貌提示词放在最上面(1U2U)时,生成的图片保留了相当高的相关性。
可以明显看出,在图像生成(尤其是在Hires.Fix模式下),提示词的顺序对输出结果具有显著影响。当与外貌相关的提示词被放在最前面时,生成的图像与模型相关度非常高。然而,当它们放在最后时,Hires.Fix将会基于最初的8K和4K关键词进行细化,导致最终生成的图像外貌与处理前的原始图像存在显著差异。
这导致结论是,在使用与外貌相关的LoRa模型时,特别是在Hires.Fix模式下,最好将所有与外貌相关的LoRa模型放在最前面。我个人建议按照以下顺序:
某个具体角色的LoRa模型,例如本例中的Zero Two LoRa模型。
整体优化模型,例如著名的ulzzang-6500 (https://civitai.com/models/8109/ulzzang-6500-korean-doll-aesthetic)、xxxdoll等。
其余的模型按重要性排序。
希望这篇教程对你有帮助~
===========
2023/3/11
经过kmlau(https://civitai.com/user/kmlau )的提醒,我发现<Lora>模型放在哪里并不会影响图片生成结果,即,stable diffuion在读prompt的时候会将"<lora>"这六个字符("<","l","o",...,">")视为空白,但是注意,一旦带了任何其他符号,比如"<lora>,",都会影响结果的生成。举个例子,
<lora>prompt_A,prompt_B,prompt_C,
与
prompt_A,prompt_B,prompt_C,<lora>
与
prompt_A<lora>,prompt_B,prompt_C,
甚至
prompt_A,prom<lora>pt_B,prompt_C, 这四种产生的结果都是完全一样的。
但是
<lora>prompt_A,prompt_B,prompt_C,
与
<lora>,prompt_A,prompt_B,prompt_C,
这二者是不同的。之前的示例中出现问题的原因是,这也是之前示例图片中变化出现的原因。即,这个逗号影响了结果的最终生成。 而除了<Lora>以外,其他的总结并未发现明显问题,如果回头发现其他问题,我将再次进行修改。
===========
==============================================
日本語バージョン
以下の内容をよくお読みください!!!
ここでアップロードされたLoRaモデルは私が作成したものではなく、jappwwさん(https://civitai.com/user/jappww)が作成したものです。私は彼のZero Two 02モデルを使用しようとしたところ、このような影響を発見したため、ここでは単に例としてアップロードしています。
一言バージョン:
画像を作成するときに、最も重要なキーワードを最前面に配置してください(この例では、02のloraモデルです)。
具体的な違いは画像で説明します。
詳細:
以下の内容は既にご存知の方もいるかもしれませんが、キーワード(Prompt)の順序が結果に与える影響について簡単に紹介したいと思います。まだこの情報に気づいていない方が理解できるように説明します。
結論として、キーワードの配置順序が画像の出力結果に巨大な影響を与えることです(特にHires.Fixモードの場合)。
以下にいくつかの例を示します。
本記事で添付した画像は、すべて同じパラメータと同じランダムシードを使用して生成されたもので、違いはキーワードの配置順序だけです。
人物の外見に関するキーワードを一番最後/下(つまり、1D2D)に置いた場合、Hires.Fixが生成する画像は元の画像と大きく異なります。その一方で、外見に関するキーワードを最上部/最初のところ(1U2U)に置いた場合、生成される画像はかなりの相関性を持っていることがわかります。
画像生成(特にHires.Fixモードの場合)において、キーワードの順序が出力結果に対して明らかな影響を与えることが明らかになりました。外見に関連するキーワードが最初に配置された場合、生成された画像はモデルと非常に関連しています。しかし、それらが最後に配置された場合、Hires.Fixは最初の8Kと4Kのキーワードを基に微調整を行い、最終的に生成された画像の外観は元の元の画像と明らかに異なります。
結論として、外見に関連するLoRaモデルを使用する場合、特にHires.Fixモードの場合ですと、すべての外見に関連するLoRaモデルを最初のところに配置することが最善です。以下の順序は個人のおすすめ:
特定のキャラクターのLoRaモデル、例えばこの例であればZero Two LoRaモデル。
全体的に最適化されたモデル、例えば有名なulzzang-6500(https://civitai.com/models/8109/ulzzang-6500-korean-doll-aesthetic)、xxxdollなど。
その他のモデルを重要度の順に並べます。
このチュートリアルが役に立つことを願っています~
本記事は主にCHATGPTで翻訳して、変なとことは自分で添削したので、もしまたどこか変なところがあれば、遠慮せずにお声掛けください!(日本語で論文などを書きすぎで丁寧すぎるところがいっぱいあるかもしれませんので、ご容赦を・・・)
===========
2023/3/11
kmlauさん(https://civitai.com/user/kmlau )の提案を受けて、私は<Lora>モデルの配置が画像生成結果に影響を与えないことを気づきました。つまり、stable diffusionがpromptを読む際、"<lora>"この6つの文字("<"、"l"、"o"、...、">")を空白として扱うことがわかりました。ただし、"<lora>,"(一つのカンマが入れた)のように他の記号を含めると、結果の生成に影響を与えることに注意してください。
例えば、
<lora>prompt_A,prompt_B,prompt_C,
と、
prompt_A,prompt_B,prompt_C,<lora>
そして、
prompt_A<lora>,prompt_B,prompt_C,
さらには、
prompt_A,prom<lora>pt_B,prompt_C,
これら4つのものは完全に同じ結果を生成します。
しかし、
<lora>prompt_A,prompt_B,prompt_C,
と、
<lora>,prompt_A,prompt_B,prompt_C,
は異なります。前の例で問題が発生した理由は、カンマが結果の最終生成に影響を与えたためであり、前回の画像で変化が発生した理由でもあります。
<Lora>以外に明らかな問題は見つかりませんでしたが、もし他の問題が発見した場合に、改めて修正いたします。
===========