
Introduction
This workflow is tested on my potato notebook (i5-9300H, GTX1050, 3Gb Vram, 16Gb Ram) but your potato PC really needs at least 16Gb Ram for this to work (in my case, the utilization of Ram was up to 98%.)
The first question you might ask is why bother with SD 3.5? The answer is that it is good at setting up a complex scene composition which SDXL isn't particularly good at. My primary tool is still SDXL but I use SD 3.5 Large for this purpose. Although I played with SD 3.5 Large, I didn't try 3.5M. And it turned out to be a surprisingly capable model worth building a workflow around.

One good thing about modular workflows is that it is much easier to add additional modules to the workflow. I am building this from the previous post (https://civitai.com/articles/10101/modular-sdxl-controlnet-workflow-for-a-potato-pc). Once again, the workflow should be fairly straightforward to understand.
Adding SD3.5M Modules

I just added three new modules for 3.5M. Then the Get nodes connected to the sampler changed to the appropriate inputs. I also added the seed node since I need to use the same seed for both 3.5M and SDXL second pass. The models I am using are SD3.5M Turbo Q4_K_M and T5 Q4 Text Encoder. I used the Turbo model to speed up the process since you just need 10 steps instead of the standard 20 or 30 steps. You can find the models at:
SD3.5M Turbo: https://huggingface.co/tensorart/stable-diffusion-3.5-medium-turbo/tree/main
T5 GGUF Model: https://huggingface.co/city96/t5-v1_1-xxl-encoder-gguf/tree/main
SDXL Second Pass

I am using the same modules from the previous post. The only difference is the addition of the VAE Encode node. This is necessary because SD3.5 uses a 16-channel VAE whereas SDXL uses a 4-channel VAE. As a result, the latent from SD3.5 can't be directly connected to the sampler using SDXL VAE.
Another thing you may notice is that I have been using ControlNet for up to 50% of the denoising process. One of the key findings in NVidia's Ediff-I research is that the cross-attention dominates the first part of the denoising process but the self-attention takes over and dominates the latter part of the denoising process. Since ControlNet goes into the Cross Attention Channel, the first 50% should be enough to do the job so that the model can fill in the rest of the details.
If you find yourself fighting with your model to enforce your ControlNet by cranking up to 100%, then your model doesn't know the concept, pose, or camera angle you are forcing upon it. In such a case, even if you force it, the outcome will be less than optimal. You have to either change the model, finetune it, or use a Lora to make sure it understands what it is looking at.
Wrapping it up
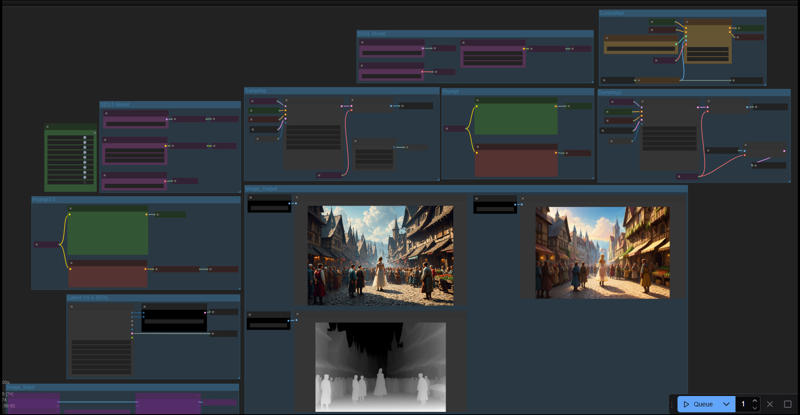
In general, I would just run the SD3.5 workflow until I find a composition I like. Then I will save the image and load it to the SDXL workflow separately for the second pass. But in this case, I decided to run the whole thing to see if the entire workflow would work on my potato notebook.
With a modular workflow, you can simply turn on and turn off the modules for the same effect. Of course, you will need to change a couple of get-node input names to the appropriate input source.