


Comparative adjectives on
Photo Realistic Sci-Fi LORA's
THE MODEL
FLUX.DEV is very strong in generating photo realistic images and it appeals most of us to give it a futuristic twist like creating cyberpunk concept art or never seen before science fiction movie scenes. I will base this article on using this model as it is overal most used for Flux.
LORA's
There are many trained models to be found on CIVITAI and most of them are trained with high detailed images making the LORA vary between 18MB to 1.5 GB in size.
In the end all LORA's are mostly just modifications on block weights giving differential on outputs. Resulting in completely new results on the generation of images.
In my understanding for LORA's that are highly trained on images will contain modified block weights to favor the output (that will look like or have a simular style as the images it was trained on). However once you tinker to much on settings, or replace the base model with something completely diffrent. It might not always give the same expected results.
FLUX however has so many variables and blocks that this does not matter too much in the end, as it will still give you acceptable results or even supprisingly beter results. This makes FLUX a stunning and fun model to work with.
But why use LORA's for Sci-Fi? And what does it add? Flux already provides stunning results prompting without using any LORA's.
This article will try to find an answer to this question.
Most of us that visit CIVITAI are already familiar with all these basics above.
But it still takes practice and alot of trail and error to learn how to generate the best results especially when using the on site image generator.
with SDXL it takes alot of trigger words to finally generate appealing results.
FLUX is far more forgiving and requires far less guidance and also works well with very short text prompts. Still using specific lora's might spice up results some more.
And below you find out how and why!
LORA STRENGTH
Often it is just to strenghen a style, concept or force resemblance on objects and characters we want to see when we use specific text prompts or triggers. But every alteration slightly changes the output on other things aswell. Like training a specific robot, can also effect how the model outputs metals, plastics, joints and sometimes other futuristic output like environments and changing the clothing style overal because of the change on specific blocks other prompt texts also make use of. When the LORA is overtrained it will even put changes in the images that have nothing to do with the concept at all and the images will start generate graphical glitches or artifacts. This can however be fixed by lowering the stength of the LORA when used.
NOTE: for comparing I lowered strength on all LORA's by using 0.8 what is usually the best default on most trained LORA's. The CIVITAI online generator might sometimes suggest a default of 1.0, but still it's better to lower this strength a bit more.
COMPARING WORKFLOW
For comparing the Sci-Fi LORA's below; I will use prompts that are as short as possible and have no negative prompt and all other settings are the same. So you can decide witch sci-fi style you like best.
Note: all images are generated on a fixed SEED: 0 variable (for sake of compairing, but seems to mostly create black armor and clothing), most LORA's will generate an overal simular style when correcly trained. (No extra trigger words are used, this might not work for LORA's that are trained to generate specific character models).
ComfyUI workflow:
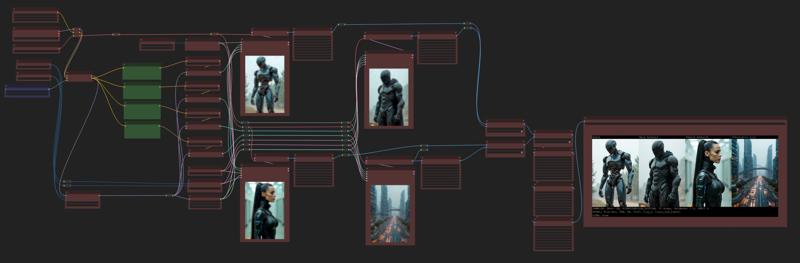
Image Prompts used:
"Robot"
"Male Android"
"Female Android"
"Futuristic city"
FLUX.DEV
No LORA

LORA: Sci-Fi Concepts by ChronoKnight

LORA: Dark Scifi by Cosmic

LORA: Flux Scifi Robot

LORA: 2020s Sci-Fi Movie (SD1, SDXL, Pony, Flux)

LORA: Autonomous AI World 2075|FuturEvoLab

LORA: Marvin - The Hitchhiker's Guide to the Galaxy [FLUX]

LORA: UNI_SCI-FI

LORA: Interstellar space

LORA: Cyberpunk_Citizen:Love and the Final Rebellion

LORA: Cyberpunk Style Enhancer [Flux]

LORA: Neurocore Sci-Fi Cyborg Portraits by ChronoKnight - [FLUX]

LORA: Cyborg & Robot
