
In continuation of my experiments with text encoders, I applied SDXL fine-tuned Clip-L text encoders to Flux. And in the process, I discovered some interesting findings.
1) Prompt matters
With long natural language-based prompts, the difference from the Clip_L text encoders didn't seem to be significant as can be seen below:

Then I moved more toward SD1.5/SDXL type prompting (tag-based prompting), and the differences began to emerge as can be seen below:

The interesting thing was that as I added SD1.5/SDXL type tags such as masterpiece, best quality, and absurdres, Flux started to generate more anime/cartoon style images without having any reference to anything anime/cartoon related words in the prompt. I am fairly certain that both T5 and Clip don't identify the word 'masterpiece' with anime/cartoon (more on that later) hinting that Flux was trained on a large anime/cartoon database.

So, Flux can generate anime images but, with natural language prompts, T5 dominates and seems to steer the generation away from going there. So, it seems that Flux will generate more anime/cartoon-style images with SD1.5/SDXL style prompts.


2) That FLux Chin!
Interestingly enough, when I did primarily an SD1.5/SDXL-based prompting, the chin issue wasn't as pronounced in the base Clip-L but it became more pronounced when SDXL fine-tuned Clip_L text encoders are used.


3) Base T5 and Clip_L do not know what 'Cowboy Shot' is
Base T5 or CLip isn't 'weeb' or 'furry' friendly. As a result, there are some tags that they don't recognize whereas SD1.5/SDXL fine-tuned Clips do. Below is an example of a 'cowboy shot' not recognized by the base text encoders.
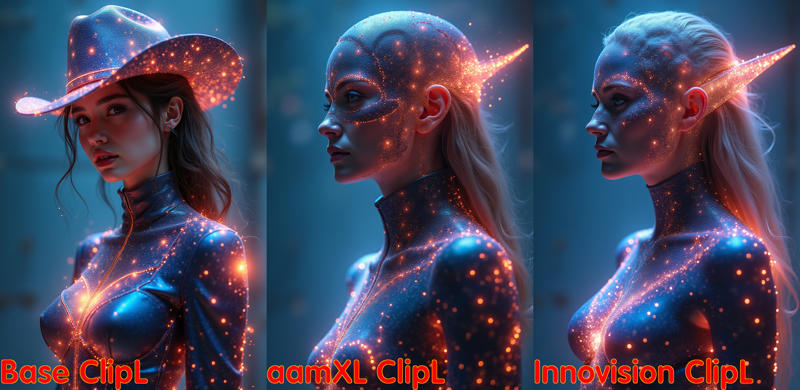
SDXL fine-tuned Clip-Ls know that 'cowboy shot' isn't really about cowboys. But T5 seems to be uncooperative. I have a few other cases but I will refrain from showing them here (for public safety concerns, cough cough!)
4) All men are created equal
The differences in Clip_L encoders are more noticeable in female figures than male ones probably because either the Flux Unet is more heavily populated with women, or SDXL fine-tuned Clip encoders are undertrained on men. Or it could be both.

5) Epilogue

I don't generally use Flux so this was the largest number of Flux image generation I did so far. However, I began to see some potential use cases for it combining with SDXL Clip-Ls. While I was doing this, it occurred to me to apply SD1.5 Clip-Ls (so that Alphonse Mucha, Greg Rutkowski, and others can be called upon.)
My next stop is to apply SDXL Clip-G and Clip-L to SD 3.5. Cheers!