

Abstract
***This research is a work in progress, and my conclusions are subjective observations about the observable effects of training parameters on image outputs, the next phase of research will test each parameter individually***
The intent of generating images for my purposes is always central to creating a feeling; however, using machine learning to create images presents the problem of control. Image outputs can be random, incoherent, and difficult to fine-tune for small textural renditions. Feeling and aesthetics are related; to be able to create a feeling with intent, the aesthetic has to be controllable. There are ways to control aesthetics with prompting, custom nodes, and sampling settings, but the most effective approach starts near the beginning of the model pipeline—with custom-trained LoRAs. When training a LoRA, I encounter a long list of complex ML terminology that only registers as abstract concepts within my camera-based foundational understanding of image creation. This research is conducted to help myself and the open-source community define and visualize the effects these parameters have on imagery.
1. Introduction
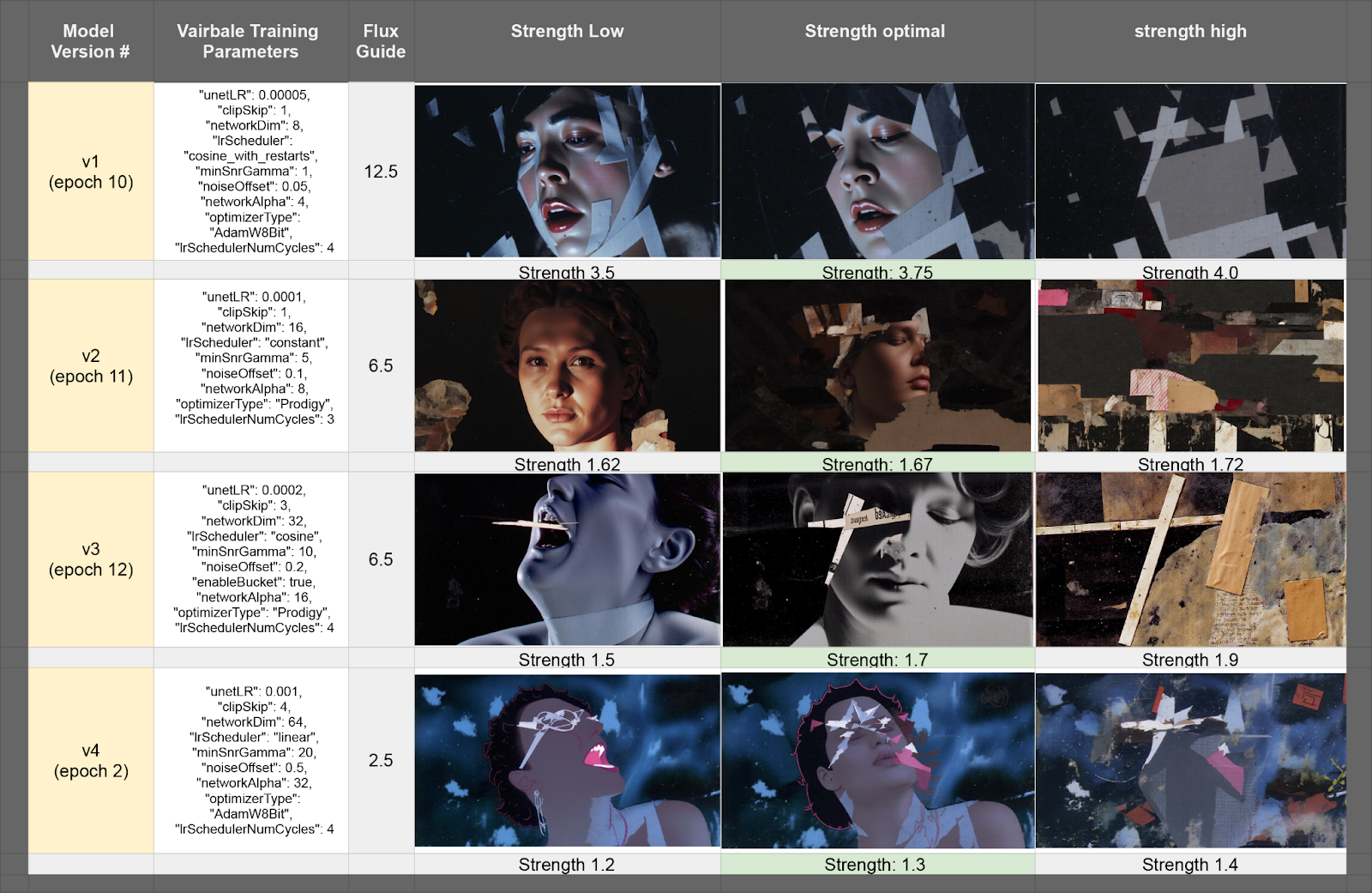
I created a dataset of 30 images generated by Kurt Schwitters, an early 1900s Dadaism artist, intending to synthesize his noninformative collage style into controlled imagery with formative subject matter. I trained four different LoRAs, each with a different combination of parameters at extreme variations, to compare the results. Because the training data is all abstract collage and I want to merge the style with defined forms, I labeled all of the training data with false captions, covering a range of scene descriptions. The training data is available here.
1.1 Parameters tested
Unet Learning Rate
Clip Skip
Network Dimension
Learning Rate Scheduler
Min SNR Gamma
Noise Offset
Optimizer
Network Alpha
Learning Rate Scheduler Number Cycle
2. Experimental Setup
Dataset: 30 images, each trained under four LoRA versions with variations in key parameters.
Evaluation Criteria:
Text/Prompt Integrity (how well text is preserved in output)
Overall LoRA Strength (extent of stylization and fidelity changes)
Artifact Frequency (presence of visual noise, distortions)
Realism vs. Cartoon Aesthetic (balance of photorealism and abstraction)
Seed Consistency (output stability across multiple various seeds *sample images below all have the same seed)
3. Results
3.1 Results with trained Loras
3.2 Results with no Loras (base model only)

4 Findings & Parameter Effects
4.1 Unet Learning Rate
Higher Unet LR values (0.0002–0.001) significantly increase stylization, often leading to texture destruction and less controlled details. Lower Unet LR values (0.00005–0.0001) keep outputs more subtle, maintaining finer details but requiring higher LoRA strength to have a noticeable impact.
4.2 Clip Skip
Higher Clip Skip values (3–4) remove the influence of text guidance almost entirely, instead prioritizing textures, color balance, and stylization. Lower values (1–2) preserve typography and finer print details, making them more effective for text-heavy generations.
4.3 Network Dimension
Lower Network Dimension values (8–16) make LoRAs effective only at high strengths, requiring exaggerated weight application to be noticeable. Higher Network Dimension values (32–64) produce more aggressive LoRA effects, often necessitating lower strengths to avoid excessive influence over outputs.
4.4 Learning Rate Schedulers
"Cosine with restarts" introduces drastic jumps in effect at strength thresholds, making it useful for controlled variability. "Constant" keeps training stable but with limited flexibility in adaptation. "Cosine" tends to enhance 3D-like structures but results in unstable outputs across different seeds. "Linear" smooths out color transitions but can overly flatten contrast-heavy images.
4.5 Min SNR Gamma
Higher Min SNR Gamma values (10–20) enhance contrast and sharpness but tend to flatten color depth, reducing natural shading. Lower values (5) retain softer gradients and allow for more depth in complex lighting conditions.
4.6 Noise Offset
Higher Noise Offset values (0.3–0.5) introduce grain and chaos, mimicking VHS/Polaroid textures and adding analog-style imperfections. Lower values (0.05–0.1) preserve clarity and retain finer textures without unwanted distortions.
4.7 Network Alpha
Higher Network Alpha values (16–32) amplify LoRA influence even at low strengths, often overpowering realism with more aggressive stylistic imprints. Lower values (4–8) require higher LoRA strengths to manifest noticeable effects but maintain a more subtle impact on realism.
4.8 Optimizers
AdamW8Bit provides predictable, controlled results, making it ideal for structured LoRA applications. Prodigy forces stronger stylization effects, leading to more chaotic analog textures and unpredictable outputs.
4.9 Learning Rate Scheduler Number Cycles
Higher LR Scheduler cycles introduce extreme variation between epochs, allowing for more diverse stylistic shifts throughout training. Lower cycle values maintain a more consistent stylization across training steps.
5. Practical Applications of Parameters
5.1 Artifacts & Clarity
Higher Noise Offset values increase grain, texture, and chaotic variation. Min SNR Gamma improves clarity and sharpness in outputs. Higher Clip Skip values can reduce artifacts but may also lower overall clarity.
5.2 Realism vs. Cartoon Spectrum Shift
Higher Clip Skip values push results toward photorealism, while lower values make images more stylized and painterly. Higher Unet LR values soften outputs with artistic distortions. Lower Noise Offset values produce cleaner images, while higher values introduce a gritty, film-like look.
5.3 Seed Consistency & Unpredictability
"Cosine with restarts" LR Scheduler creates controlled unpredictability across generations. The Prodigy optimizer decreases consistency, increasing variation in outputs. Higher Unet LR values decrease seed consistency, leading to less predictable outputs. Lower Network Alpha values stabilize seed predictability by reducing LoRA dominance.
5.4 Overfitting vs. Generalization
Higher Network Dimension values encourage overfitting, reducing flexibility in LoRA adaptation. Higher Unet LR values can cause over-memorization, leading to less variability. Higher Clip Skip values can improve generalization, allowing models to extract broader stylistic features rather than overfitting to specifics.
5.5 Parameter Sensitivity (How Small Changes Impact Outputs)
Higher Network Alpha values result in small adjustments causing large output shifts. Higher Min SNR Gamma stabilizes changes, making variations less extreme. Higher Noise Offset values increase chaotic elements, making outputs more sensitive to small adjustments.
5.6 Fine Detail Retention
Higher Min SNR Gamma values improve fine detail preservation. Excessively high Network Dimension values can cause loss of finer details. Lower Unet LR values help maintain sharpness and structural integrity.
5.7 Contrast & Tonal Shifts
Higher Noise Offset values wash out tonal depth and flatten colors. Higher Min SNR Gamma values create stronger contrast, deepening shadows and enhancing highlights. The Prodigy optimizer produces harsher, more exaggerated contrast shifts.
5.8 Stylization vs. Photorealism
Higher Clip Skip values push toward photorealism, while lower values lean into stylization. Higher Network Dimension values increase stylistic influence and exaggeration. Higher Unet LR values soften images, creating a more dreamlike, impressionistic aesthetic.
6. Conclusion
Fine-tuning individual values such as Clip Skip, Unet LR, and Noise Offset enables targeted control over stylization, realism, and text fidelity. Future studies will expand on testing parameters individually, multi-LoRA blending, and dataset balancing.