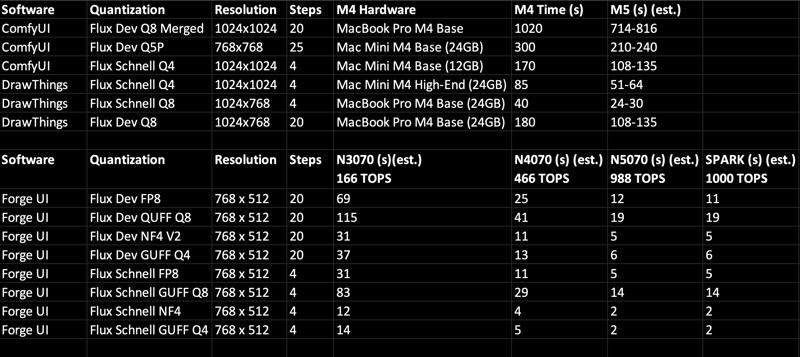
From the prediction data, we can see that Apple's M5, M6, and even M7 series computers over the next 3–4 years will not be productive tools for Flux image generation, especially when using merged Flux dev models from Civitai. Additionally, this speed assessment does not account for OpenPose and other extensions. Furthermore, due to their compact design and poor ventilation, overheating from image generation will accelerate the degradation of Apple chips. Fingers crossed that Apple realises this and designs true AI-dedicated and affordable hardware and even their own software similar to Logic and Final Cut.
Speed comparison
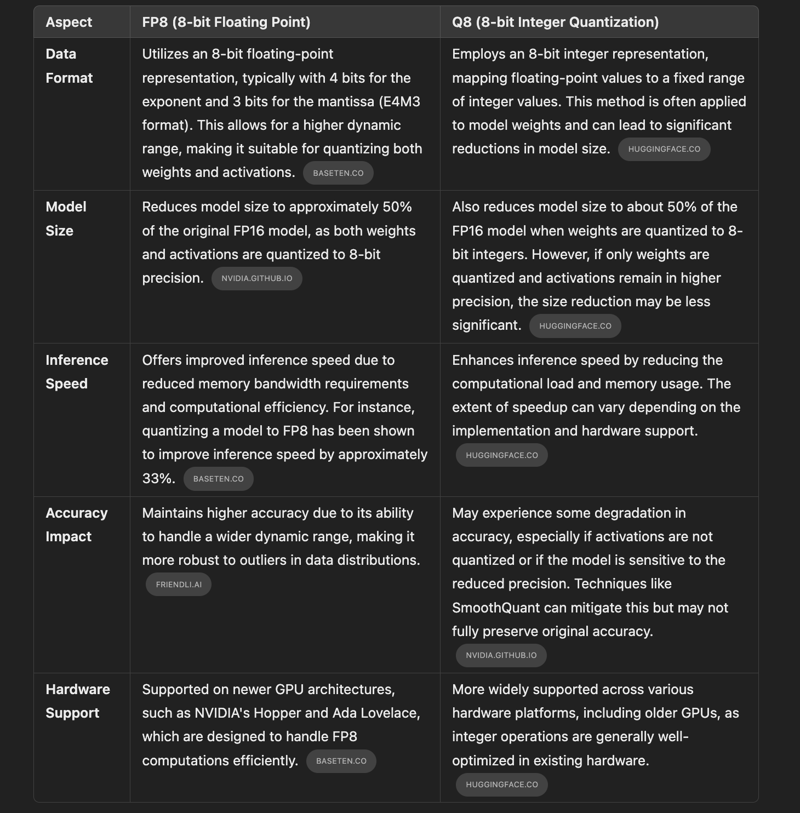
This refers to the FLUX schnell / dev model quantized to 8-bit precision. In this context, "8-bit" typically means that the model's parameters are stored using 8 bits per value, reducing memory usage and potentially increasing inference speed.
The 8-bit quantization can be implemented in various ways, with two common formats being FP8 and Q8.
Flux original.
https://civitai.com/models/618692?modelVersionId=691639
Flux dev 8 bits.
https://huggingface.co/Kijai/flux-fp8
Flux schnell 8 bits.
https://huggingface.co/PrunaAI/FLUX.1-schnell-8bit
https://civitai.com/models/895985?modelVersionId=1003372
QUFF refers to another quantization format.
https://huggingface.co/city96/FLUX.1-dev-gguf
https://civitai.com/models/648580/flux1-schnell-gguf-q2k-q3ks-q4q41q4ks-q5q51-q5ks-q6k-q8
NF4 refers to quantization technique introduced in the QLoRA paper. It's designed to represent model weights with 4 bits, approximating a normal distribution.
https://civitai.com/models/638187?modelVersionId=819165
https://huggingface.co/lllyasviel/flux1-dev-bnb-nf4
Source