
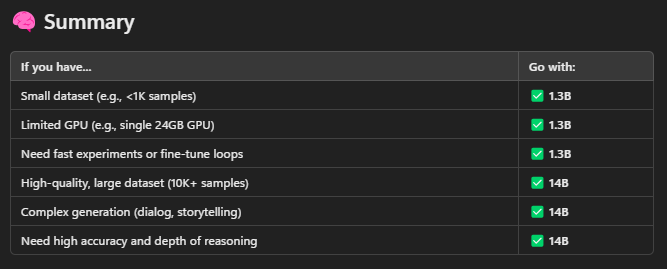
TLDR : If you have a single 24 GB Vram, use 1.3B T2V for training. Use 1,000 epochs and look for lr loss around 0.02.
Read down below only when you want to know more and details.
Wan1.3B T2V 🧠 can be trained on consumer-grade GPUs 💻. A 24GB VRAM GPU is more than sufficient and performs well—in my tests, it didn’t even use half of the available memory 🚀.
Wan14B T2V 🧠⚡ training on a 24GB VRAM GPU is possible using RAM block swapping 🧊💾 with around 36 blocks. However, this method is painfully slow 🐌—expect training times to be 5 to 10 times longer. Training just 16 images 🖼️ for 100 epochs ⏳ can take days 📆.
Wan14B must be trained using dtype = float16 🧮, even if the model supports FP8 training (e.g., from Kijai). Only the transformer type can be set to float8 🔧, and the diffusion-pipe code maps it accordingly 🧩.
Both 1.3B and 14B models require very careful configuration ⚠️ in the TOML file. If not set correctly, nan values ❌ can appear as early as step 2, meaning the model isn’t learning at all 🤯. After starting training, keep an eye 👁️ on the loss value in the terminal—if you see nan, stop training 🛑 and adjust your settings 🛠️.
Below is the TOML configuration I found to be fairly optimized and stable ✅ for training. That said, training Wan14B is still very time-consuming, and producing a good LoRA likely requires more than a consumer-grade GPU ⚙️🔥.
# Output path for training runs. Each training run makes a new directory in here.
output_dir = 'data/output/wan2.1/Lora14b'
# Dataset config file.
dataset = 'examples/dataset.toml'
# training settings
epochs = 18
micro_batch_size_per_gpu = 1
pipeline_stages = 1
gradient_accumulation_steps = 1
gradient_clipping = 1.0
warmup_steps = 100
blocks_to_swap = 36
# eval settings
eval_every_n_epochs = 9
eval_before_first_step = true
eval_micro_batch_size_per_gpu = 1
eval_gradient_accumulation_steps = 1
# misc settings
save_every_n_epochs = 9
checkpoint_every_n_epochs = 6
#checkpoint_every_n_minutes = 15
activation_checkpointing = true
partition_method = 'parameters'
save_dtype = 'bfloat16'
caching_batch_size = 1
steps_per_print = 1
video_clip_mode = 'single_middle'
[model]
type = 'wan'
ckpt_path = 'models/wan/Wan2.1-T2V-14B'
transformer_path = 'models/wan/Wan2_1-T2V-14B_fp8_e4m3fn.safetensors'
llm_path = 'models/wan/umt5-xxl-enc-fp8_e4m3fn.safetensors'
dtype = 'float8'
# Optional: use fp8 for transformer when training LoRA
transformer_dtype = 'float8'
timestep_sample_method = 'logit_normal'
[adapter]
type = 'lora'
rank = 128
dtype = 'bfloat16'
[optimizer]
type = 'adamw_optimi'
lr = 2e-5
betas = [0.9, 0.99]
weight_decay = 0.02
eps = 1e-8
---------------------------
🧠 2 GPU Training
Using 2 GPUs on diffusion-pipe does not support block swapping with RAM 🚫💾. So you must choose between:
💪 Two powerful GPUs
🐢 One GPU with RAM block swap (much slower)
If you have 24GB VRAM + 8GB VRAM, don’t bother trying dual GPU 😓—it will run out of memory (OOM) 💥.
Training Wan LoRA with 2 GPUs requires at least two 24GB VRAM cards 💻💻. You might get by with a 3090 and 4090 combo (barely 😬), but 2x4090 is a more reasonable setup for this case. Even with a 5090, it may still not be enough ⚠️.
This high hardware requirement creates a significant bottleneck ⛔ for Wan's popularity, especially among consumer GPU users.
-----------------------------

----------------------------------
Tips :
For the first 300 steps, it is very good to copy all log to have ChatGPT analyze the learning rate. This will save you a lot of time, if it goes bad just terminate and test last epoch lora. Otherwise, you can check how fast lr (learning rate) loss is going down. Good lora need to be around 0.02xxx to shine.
For a small batch of 15 - 30 images, go around 1000 epochs and see when it reach 0.02 to stop. Check the tensorboard scalars (Diffusion-pipe logs each step)