![[Miso-diffusion-m] Discovering SD3.5m potential](https://image.civitai.com/xG1nkqKTMzGDvpLrqFT7WA/0a2efdc0-869c-4b5d-8131-24abf2f8aecb/width=1320/ComfyUI_00506_.jpeg)
Hi everyone, since the release of SD 3.5 and flux, a lot of people having been waiting on a large scale fine tune on newer models. So I decided to work on it. While still facing some technical challenges, I would say the training is slowly going towards the right direction, and hope this would be a nice addition to the community.
The latest version Miso-diffusion-m 1.1 is a SD3.5 medium model trained with 710k anime images for 5 epoch.
You can download it and view more detail here: https://civitai.com/models/1404024/miso-diffusion-m-11
or Download from huggingface if you prefer to seperate the text encoder: https://huggingface.co/suzushi/miso-diffusion-m-1.1
I've merged the CLIP encoder directly into the model (without T5) for easier use. Though if you prefer to use t5 you can set it up using the triplecliploder in comfy:
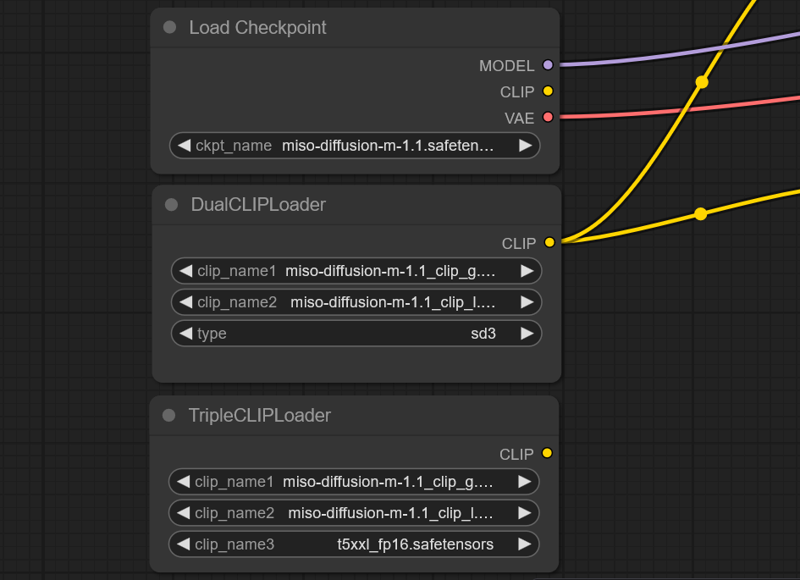
The reason I left out the t5 is mainly due to the censorship and its more computation expensive.
Current Capabilities & Limitations
Strengths:
Picks up small details quicker (unlike SDXL)
Good overall anime aesthetic
Current Limitations:
Struggles with hands and complex poses (will improve with further training)
Learns character and artist tags very slowly
Artist tags currently have minimal effect on generation
Future Plans
I'll be writing a comparison article soon on how SD3.5 medium compares to training SDXL in training, in addition I am also preparing a larger dataset at the moment.
Edit, you can read the training comparison article here: https://civitai.com/articles/13033/comparing-sdxl-and-sd35-medium-training
Training a base model is costly so I would appreciate if you can support this project,
thousand dollar would be enough for me to train a million image for 10 epoch already: