

LoRA作りにおけるタグ付けの仕組みと考え方【Dataset Tag Editor前提】
LoRAを作るうえで欠かせない「タグ付け」。
でも、付けたタグが実際にどのように学習に使われているか、意外と知られていないかもしれません。
この記事では、Dataset Tag Editor(DTE)を使用することを前提として、タグがどのように作用するのか、そして目的に応じた効果的なタグ付けの方法について解説していきます。
「覚えさせたいタグを消す」ってどういうこと?
YouTubeやブログなどで、「覚えさせたいワードを削除する」と説明しているのを見たことがある人も多いと思います。
でも、「覚えさせたいならタグを付けるべきじゃないの?」
そう疑問に思った方もいるのではないでしょうか。
この疑問は、AIがタグをどのように学習しているかを理解することで、きちんと説明がつきます。
AIは「タグと画像の関係」を学習する
AIは、タグを単なるラベルとしてではなく、その画像に含まれる要素との関連情報として学習します。
たとえば、赤いリボンが映っている画像に「red ribbon」や「red bow」といったタグが付いていれば、AIはそれらのタグとリボンのビジュアルをセットで覚えていきます。
そのため、t2iで「red ribbon」と入力すると、LoRAはこの学習内容をもとに、赤いリボンを描き出すことができるのです。
トリガーワードの仕組みも理解しよう
LoRAには「トリガーワード(Trigger Word)」という概念があり、これはLoRAの効果を引き出すために使用されるキーワードです。
ただし、トリガーワードは万能な魔法の言葉ではありません。
プロンプトやモデルの構成など他の要素にも影響されるため、あくまで「LoRAが学習した特徴を呼び出す手助けをするもの」として考えるべきです。
ここで重要なのは、トリガーワードも一種のタグであり、学習時にはその画像に個別タグを付けなかった要素すべてが、トリガーワードに紐づいて学習されるという点です。
つまり、トリガーワードは画像全体を包括して学習するため、うまく使うことで「このワードを打てば全部出てくる」というLoRAにすることも可能になります。
タグ付けの3パターンを比較
タグ付けでは、人物の外見、表情、ポーズ、背景、小物など、さまざまな情報がInterrogatorによって抽出されます。
この中から「学習させたい要素」と「学習させたくない要素」を取捨選択していくことがLoRAの完成度を大きく左右します。
今回は例として、「キャラクターの外見と服装だけを学習させたい」場合を想定して、タグの付け方を次の3パターンで比較してみます。
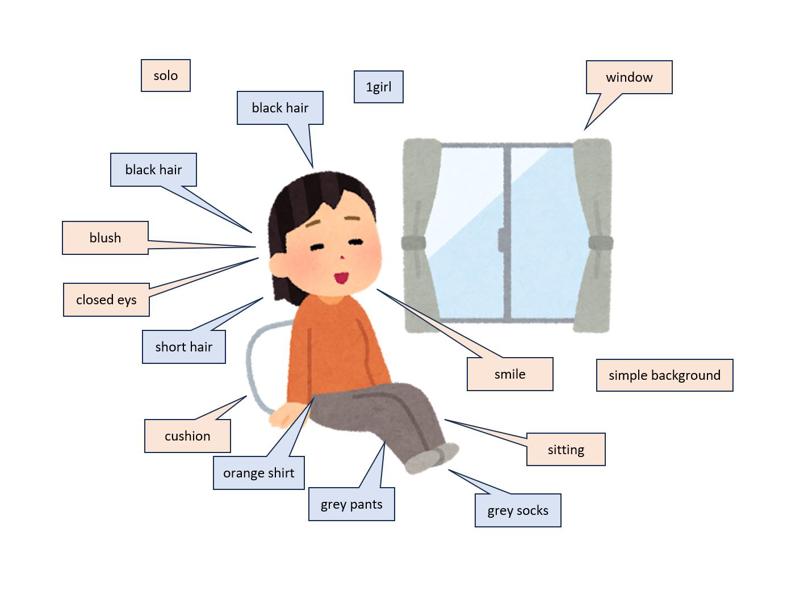
パターン①:すべてのタグを付与する
Interrogatorで抽出されたタグを、すべてそのまま残して学習させる方法です。
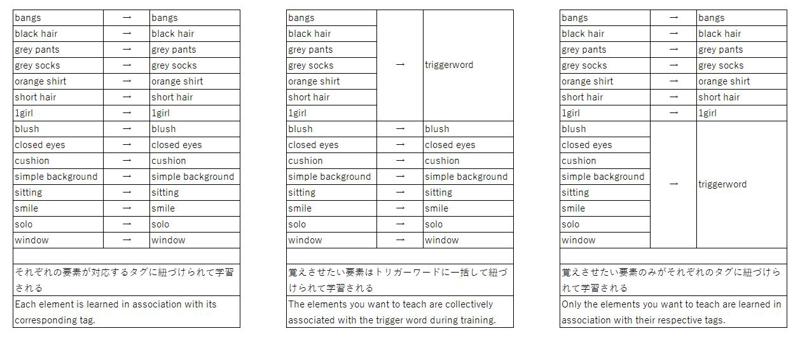
タグ:1girl, bangs, black hair, blush, closed eyes, cushion, grey pants, grey socks, orange shirt, short hair, simple background, sitting, smile, solo, window,
特徴・効果:
各要素がそれぞれのタグに紐づけられて分散して学習される
以下のような特性を持ったLoRAになります:
各タグの学習密度が薄くなり、再現性が下がりやすい
呼び出したい要素はプロンプトで明示しないと反映されにくい
トリガーワードに紐づく要素が少ないため、トリガー単体の効果が薄い
パターン②:学習させたいタグを除去する(=覚えさせたくないタグだけを残す)
この方法では、学習させたい要素にはタグを付けず、その他の不要な要素にだけタグを付けて学習します。
そのうえでトリガーワードを設定することで、タグなしの要素をすべてトリガーワードに吸収させる手法です。
タグ:1girl, blush, closed eyes, cushion, simple background, sitting, smile, solo, window,
特徴・効果:
トリガーワードのみで一括して学習要素を呼び出せる
以下のような特性があります:
トリガーワードひとつでキャラの外見や衣装がまとめて再現される
タグを付けた不要な要素(例:背景など)は、プロンプトに含めない限り生成に影響しにくい
無理にプロンプトで補完しようとすると、他のモデル要素と干渉して再現性が落ちることがある
複数衣装LoRAの作成に適しており、トリガーワードで衣装ごとに明確に切り分けられるため干渉が最小限
パターン③:学習させたいタグだけを付与する(=不要なタグをすべて削除)
この方法では、学習させたい要素のタグだけを残し、背景や小物などの不要な情報を一切付けずに学習させます。
一見シンプルですが、トリガーワードに「抜けた部分の特徴」が吸収されるため、注意が必要です。
タグ:bangs, black hair, grey pants, grey socks, orange shirt, short hair,
特徴・効果:
各タグごとの呼び出し精度が高く、プロンプトによる細かい制御がしやすい
以下のような特性があります:
トリガーワードだけではLoRAの効果がほとんど出ないこともある
明示的にタグを打つことで各要素を呼び出せるため、プロンプトのコントロール性が高い
複数衣装LoRAを作る場合、タグが被ると干渉するため、プロンプトの表現を微妙に変える必要がある(例:"blue uniform" vs "navy school outfit")
これらのパターンなどを表や図で表すと以下のようになります。
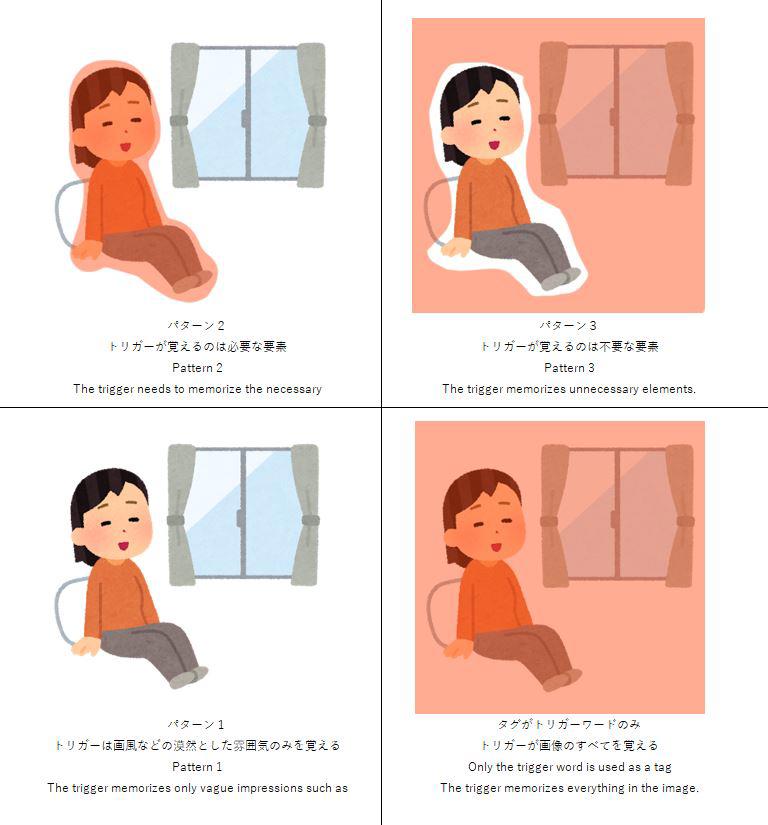
まとめ:タグ付けは「何を覚えさせたいか」次第
タグの付け方ひとつで、LoRAの挙動は大きく変わります。
「全部覚えさせたいのか?」「一点集中で覚えさせたいのか?」を最初に明確にしておくことが、満足度の高いLoRAを作るための第一歩です。
応用編:ボケた学習結果をタグでコントロールする方法
データセット内にピントが甘い画像や画質の悪い画像が混在していると、LoRAの学習結果にもその影響が出てしまい、「なんとなくぼやけた出力」になることがあります。
このような場合、タグを活用して問題を分離・制御することが可能です。
具体的には:
画質の悪い画像に対して blurry タグを付与する
→ LoRAが「ぼやけ=blurry」という特徴として明示的に学習学習されたLoRAを使う際に、プロンプトに blurry を含めない
→ ぼやけた特徴を無効化でき、シャープな出力を得られる可能性が高まります
これは、**不要な画質特性を「タグで隔離する」**というテクニックであり、タグによる出力制御の一例として非常に有効です。
実際にあった面白い例
タグの仕組みを知らないと不思議に感じる、ちょっと面白い実例があります。
ウサ耳のキャラクターを**パターン②(=学習させたい要素をタグなしで学習+トリガーワードを設定)**でLoRA化した場合のことです。
このLoRAを使って生成する際に、出力を補完しようとして rabbit ears をプロンプトに追加したところ、なんと耳が4つ生えてくるという現象が発生しました。
これは、LoRAのトリガーワードにすでにウサ耳が学習されていたため、さらにプロンプトで「rabbit ears」を加えたことで、
トリガー側のウサ耳(LoRAで学習済み)
モデル側のウサ耳(rabbit earsタグによる通常出力)
の両方が同時に出力されたため、重複してしまったのです。
この現象は、一見するとバグのようにも思えますが、タグやトリガーワードの仕組みを理解していれば、「ああ、これは重複して出てきた結果だな」と納得できるはずです。
※
当方独学のため、ここにある記事は自己解釈したものです。間違えている部分などあれば、指摘をお願いします。