
Someone asked me if I can share some of my knowledge about how to train meme/pose LoRA, including using CivitAi onsite training. I’m gladly someone ask it. This article will give people about what am I doing with LoRA training and some of my observation when training a concept LoRA relate to meme/pose.
Please note that the information I’m about to share here is undocumented. This is purely base on my observation when training and genning images.
I will mention most about anime model, the illustrious checkpoints.
I’m not a programmer nor a machine learning researcher, I’m just a person who love genning images with Stable Diffusion models. I don’t know too much about what is the technology and documents behind, as well as the specific terms or words that I can express for the situation I’m talking about.
As far as I know, there are not much articles relate to Concept LoRA, and it’s worse when mention about training a LoRA for meme :D
I assume that people who read this article understand what a LoRA is and how it works. For LoRA, especially for a concept LoRA, it bases on how good is the dataset and how well the training model understanding the concept in the image. All of the memes LoRA available on my CivitAI profile contain poses the checkpoints (Illustrious 0.1 based) already known or briefly known, except “The otp and the third wheel meme”.
When you have a good dataset and you believe the model understands the pose in the image, just start training the LoRA. For me, with multiple characters in the image, I’ll try to be more specific in the clothes, the hairs, the eyes, of the character and their actions/poses. You do not need to tag too specific like “skirt, pink skirt, pleated skirt”, sometimes “skirt” is enough.
If the pose does not have a specific tag in Booru or the entries are too low for the model to understand it, I have to see which other actions/poses that can combine together to get that specific pose. For example, “the body bridge pose”, body bridge, according to Danbooru: ”A stretch performed when someone's balancing on all fours with the body facing upward, resulting in an arched back and the abdomen being the highest point of the body”. This means, I can use some of the tags for this pose like: “all fours, looking up, arched back, flexible, yoga, balancing, arms support” and put the trigger word at first “body bridge”.

If you can invest some times before training a concept LoRA, you can try to make some images with the model you are going to train on first to see if it can understand the concept even just a little bit. This might help you to see which kinds of settings you are going to have for the LoRA.
For a meme tag with have a count higher or almost to 150 in Booru, there will be chance the model to understand it. For example, anya's heh face (meme), which currently have higher than 600 counts in Danbooru, Illustrious XL 0.1 based checkpoint understand this tag very well that you don’t have to have a LoRA to get this meme to work, unless you want to make it more stable in some way.

“piper perri surrounded (meme)” is another tag you can use for meme, but result sometimes will give a full body latex girl sitting on couch or some fking creepy creatures surround your character. This is when you want to train a LoRA to stable it. :D

If the count is less than 150 in Booru, but the poses performed by those characters for the meme are known to the model, then you might able to successfully train a meme LoRA with a low dim rank and low steps.
For example, this meme “your milkers look heavy ma'am let me hold them (meme)”, a meme involving a character typically drawn in fumo style offers to fondle a large-chested woman's breasts (or "milkers") on the pretense of helping her hold them up. Model already understand what is “ fumo (doll)” and “open hands”, you can have some 5-20 images which same pattern, tag the images with those two tags “fumo (doll), open hands” and put the key word at first.

Make sure to be specific with other tags like clothes, objects, background, hair, eyes, etc. Then you should denoise the images, or do any kind of method that help to reduce the noise in the images, it will help a lot for the training later. Next, you can go on CivitAI onsite training or any other training scripts and start to train the LoRA. For this meme “your_milkers_look_heavy_ma'am_let_me_hold_them” LoRA, I only used 6 images for the training dataset, batch size of 4, 20 repeats, 10 epoches, 8 dim rank, 4 dim alpha, which only 300 steps in total.
SETTINGS:
I believe that everyone has their specific way of tagging and settings for the process of training a LoRA. But here are my setting styles for training those LoRAs, these settings you can find it on the CivitAI onsite training:
- Num repeats: depend on how many images, 5-20 when dataset contains less than 20 images
- Train batch size: 2 or 4
- Steps: 500 – 1300 (usually)
- UNET LR: 0.0003 – 0.0005
- TE LR: 0.00005 – 0.00006
- LR Schedulers: cosine_with_restarts
- LR Scheduler Cycles: 3
- Min SNR Gamma: 7 (off when training on NoobVpred)
- Network Dim: depend, between 8-32
- Network Alpha: depend, between 4-16
- Optimizer: AdamW8bit or AdaFactor
- Epoch: 10
The above settings work fine, but for a better quality LoRA, I still recommend using training script or train it locally. Please go with the guide from arcenciel for a better training method than the one I mention here.
Currently I'm changing the training method, so this article is out of dated. Beware of the content in this article will change drastically in the near future.
1/ Meme with 1 person only:
- Network Dim: 8 (no text)
- Network Alpha: 4 (no text)
2/ Meme with 2 more person with different poses:
- Network Dim: 16-32
- Network Alpha: 8-16
3/ Meme with text:
3.1/ Text less than 10 letters:
- Batch size of 2
- Network Dim: 8-16
- Network Alpha: 8-16
- Epoch: 10-15
- Optimizer: AdamW8bit
3.2/ Text more than 10 letters:
- Batch size of 1 or 2
- Network Dim: 16-32
- Network Alpha: 8-16
- Epoch: 10-15
- Optimizer: Prodigy or AdamW8bit (Prodigy go with cosine LR schedulers)
4/ Comic, 2koma, 4koma:
- Network Dim: 16-32
- Network Alpha: 8-16
- Tagging: add the tag comic, 2koma, 4koma depend on the LoRA you are training on
5/ Photo background:
- Network Dim: 8-16
- Network Alpha: 4-8
- Tagging: add photo background
6/ Other:
- Goodluck
- Try you best
Some observation when training LoRA:
1/ Meme with 1 person only:
- The easiest one sometimes
- Depend on how the training model understand the pose
- Easy to overtrain with some extra details
2/ Meme with 2 more person with different poses:
- Depend heavily on how the training model understand each pose
- A lot of tags for one image since we have tags for every single character and their actions
- Sample images are not good every time until you test them by yourself with the help of some extensions like Regional Prompter, Forge Couple, etc
3/ Text meme:
- Pray to GOD before training this kind of LoRA. This is purely based on luck
- Illustrious checkpoints are bad at recognizing these letters: W, L, P, D, N, I
- Dataset images need to be extremely strict on the text position, size, font, color to get a stable result
- NoobVPred 1.0 understand text better, but always struggles to gen the last word of a sentence
- Always add tags related to text like: text, english text, speech bubble, etc
4/ Comic, 2koma, 4koma:
- Goodluck
- Don’t believe the sample images until you test it by yourself
- Need extension like Regional Prompter, Forge Couple most of the time
- Remember to add tag relate to this kind of LoRa: comic, 2koma, 4koma, etc
5/ Photo background:
- Be prepared for noise all over the place
- Easy to train, easy to overtrain
6/ Other:
- Good luck
- Try your best
About tagging meme:
- Tag “meme” is extremely weird, it tends to give a result with a watermark in the corner of image, so you may need to add some watermark tags into the negative prompt.
- Sometimes you can put the whole meme name, sometimes you shouldn’t. For example, “i'm a healer but... (meme)”, this tag contains “healer” that tends to give your character with “a healer clothes or a priest clothes”, somehow "healer" is not listed in Booru, but it works. Or “do you see this shit? (meme)”, omg this really give “shit” into your character’s face.
- Try to tag the images with tags already existed in Booru, you can add other description later when testing the LoRA.
Some examples of LoRA that can be considered as bad/failed:
As we know that the settings have a big impact to the result LoRA. Depend on the batch size, num repeats, UNET LR, TE LR, LR Scheduler, Optimizer, etc that can give a huge different to the result.
I'm not a person who frequently reading and understand the scientific documents behind these technology, so I will not express too much about them.
I frequently use CivitAi onsite training. My UNET LR and TE LR usually high because I do not want to waste Buzz for underfit LoRA result or spend more Buzz to get more steps. This will usually let the LoRA overtrain and I'll just pick an epoch before epoch 10 and test.
This one will show some Meme LoRAs I'm working on, and they might not be good enough to post it to CivitAI right now.
1/ woman scared of breasts (meme)
Exclaimer: May have some disturbing contents
A meme based on a photoshopped image in which a woman in a car is showing fear of breasts.
Reference image:

Sample dataset from Danbooru:
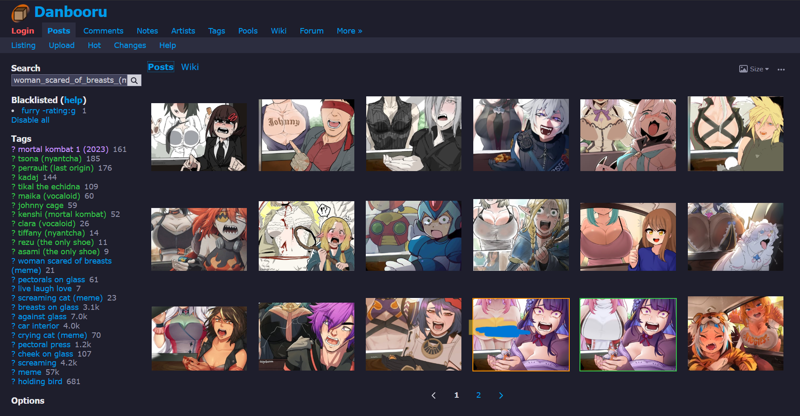
My training settings:
I forgot to take a screenshot for the settings, but here is the setting:
Dataset with 17 imgs
Batch size of 2
Repeat: 15
UNET LR: 0.0005
TE LR: 0.00005
LR scheduler: cosine_with_restart
Min SNR Gamma: 7
Network Dim: 8
Network Alpha: 4
Optimizer: AdaFactor
Result on CivitAI training:
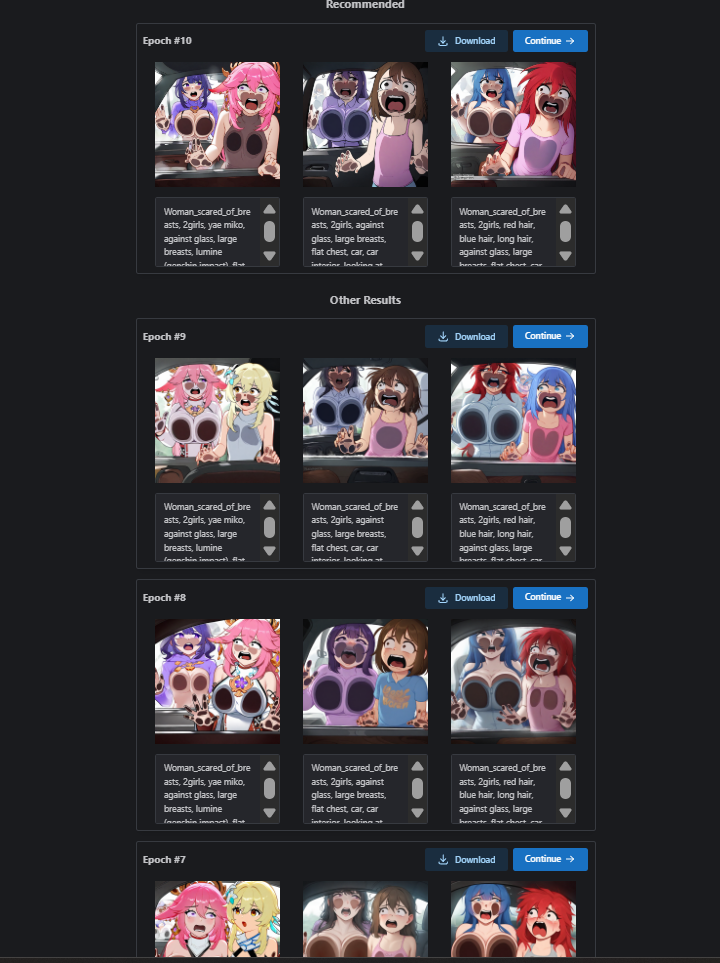
It's fking messed up. I didn't edit or cover any body parts, the result is just like that :D
But hold on, let test the LoRA, I'll choose epoch 8. I'm going to use WAI-NSFW-ILLUSTRIOUS v11
No extra settings or extensions:

YEAH, this is really mess up.
But let me try with extra extension like Regional Prompter:


Damn, Failed!
This is the example of bad LoRA. It did learn some expression but it did not understand one person inside and the other outside the car. Also the hands are something I don't know how to tag in the training dataset.
2/ woo yeah baby! that's what i've been waiting for (meme)
A meme involves Cr1TiKaL jubilantly screaming in excitement while rising both his hands up, proclaiming "Woo yeah baby! That's what I've been waiting for! That's what it's all about!". In reality, this famous scream is actually a sarcastic act in response to the delivery of pooping unicorn toys that he ordered to play and make fun out of it.

Dataset include only 4 imgs
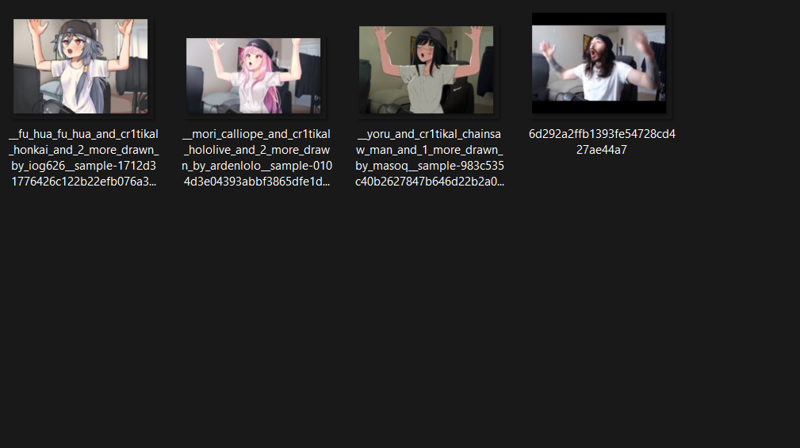
This was trained on XL Lora Trainer by Hollowstrawberry using Google Colab
Some of settings:
Dataset with 4 imgs
Batch size of 2
Repeat: 20
UNET LR: 0.0003
TE LR: 0.00005
LR scheduler: cosine_with_restart
Min SNR Gamma: 7
Network Dim: 8
Network Alpha: 8
Optimizer: AdamW8bit
I do not know how to set up samples for each epoch. This one will show the result of epoch 8 and 10 only :D
Epoch 8:

It started to learn the arms up correctly, but white shirt is always appear without clothes tag in positive prompt.
Epoch 10:

Now it is better, but it learned something in the background that I did not include in my positive prompt. And when I test with other character and more complicated prompt, it tends to give some unwanted results.
It is not too bad, but I'll try to make another one and test it with another settings later to see if it can improve or not.
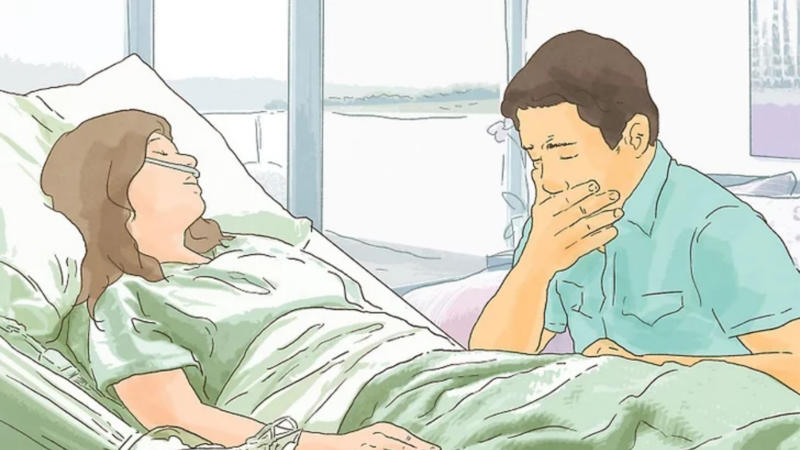
3/ please stop beatboxing (meme)
Starts Beatboxing refers to a parody meme format in which images of people and characters covering their mouths while crying or in surprise are intentionally misinterpreted as if they are beatboxing due to the similarity of the gesture. In 2020, a WikiHow image depicting a man crying near his dying partner gained popularity as the Please Stop Beatboxing redraw format.
I tried to just put no tag for this LoRA, only the trigger word: please_stop_beatboxing
Batch size of 2
Repeat: 20
UNET LR: 0.0003
TE LR: 0.00005
LR scheduler: cosine_with_restart
Min SNR Gamma: 7
Network Dim: 8
Network Alpha: 8
Optimizer: AdamW8bit
Image sample:
Without proper tag:
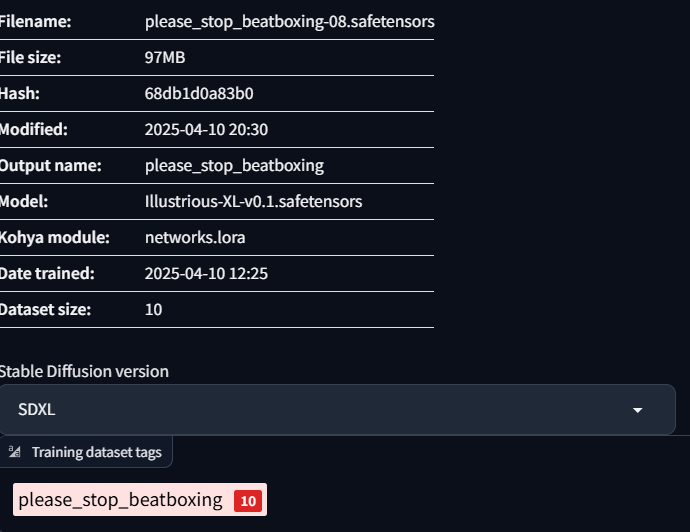

With proper tag:
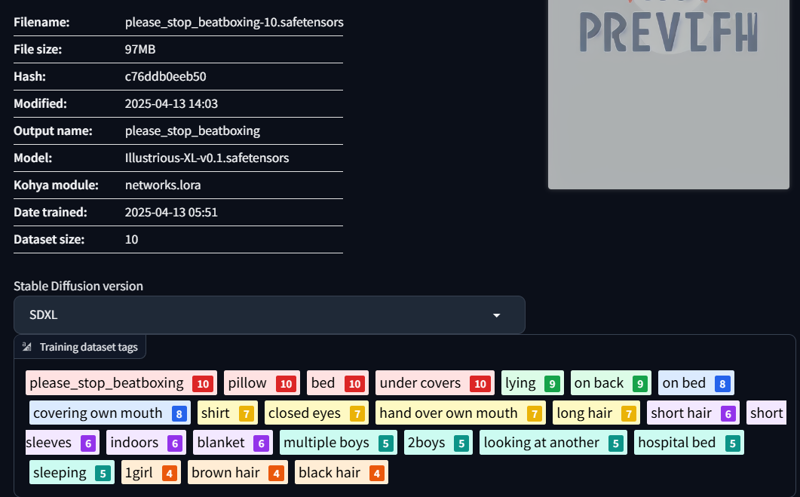

As you can see, without proper tag for the training dataset, the result have some bad clothes, hands, and eyes. With proper tag, it did improve the quality. But both of them still have problem with the hands :(
Please note I picked the best epoch (according to myself :D) to compare from different training, they are not the same training.
4/ did you want to talk? (meme)
A size difference meme, coming from the reveal trailer for Tomodachi Life: Living the Dream.

I overtrained this one.
Dataset:
Forgot to take note for the training setting
Here the result:

The style was blended in, this is not the original style for Illustrious NSFW WAI ANI checkpoint. It also learned the blushing cheeks that I did not add it in the prompt. Also, the position of the chibi person did not correct and the giantess did not look at the chibi one.
Useful links and documents:
Regional Prompter: https://github.com/hako-mikan/sd-webui-regional-prompter
Forge Couple: https://github.com/Haoming02/sd-forge-couple
How to Generate Multiple Different Characters, Mix Characters, and/or Minimize Color Contamination | Regional Prompt: https://civitai.com/models/339604/how-to-generate-multiple-different-characters-mix-characters-andor-minimize-color-contamination-or-regional-prompt-adetailer-and-inpaint-or-my-workflow
Tag groups: https://danbooru.donmai.us/wiki_pages/tag_groups
XL Lora Trainer by Hollowstrawberry: https://colab.research.google.com/github/hollowstrawberry/kohya-colab/blob/main/Lora_Trainer_XL.ipynb
About my previous article:
I did promise about putting my dataset for LoRA I trained, not yet trained, failed to trained for some BUZZ, but I forgot that images I collected for the datasets not only from Booru but also from different site and I do not have the right to make commercial with it.
I'll release some dataset I believe that I have the right to share without charging any BUZZ, instead of charging the BUZZ for those.
I'll update more when needed
04/04/2025 update: Fix minor grammar errrors, and TE LR.
04/05/2025: Add section about Bad/Failed LoRAs. Continue posting later
04/18/2025: Add 2 more LoRAs in Bad/Failed LoRAs.
05/21/2025: Add note into training parameters
Thanks for reading this