


Weighting the T5xxl-Unchained
I've been working out a process to weight it just like the other text encoders; allowing for a full restructured and uniform cleaning of the modified new weights to be more in parity with it's old, while still allowing the new weights to function correctly with the new training.
This is a normalization technique that involves very little information but a lot of interrogating, so it'll take a while to perform after the necessary inverse calculations and learn rates are established with losses.
The text encoder offset preparer
import torch
# Define timesteps and normalize
timesteps = torch.tensor([9, 11, 14, 22, 73, 94, 99, 113, 149, 199], dtype=torch.float32)
timesteps_normalized = timesteps / 1000.0
timesteps_inverse = 1.0 - timesteps_normalized
# Create base vectors using some pattern (e.g., sinusoidal encoding base offset)
def encode_offset(value):
return torch.tensor([
torch.sin(value * 3.14),
torch.cos(value * 3.14),
value,
value ** 2,
torch.sqrt(value + 1e-6),
torch.log(value + 1e-6),
torch.exp(value) if value < 0.5 else value * 2, # clamp for stability
1.0 / (value + 1e-6)
])
# Generate encoded vectors for each
encoded = [encode_offset(t.item()) for t in timesteps_normalized]
encoded_inv = [encode_offset(t.item()) for t in timesteps_inverse]
# Convert to tensor format
offsets = torch.stack(encoded) # shape: [10, 8]
offsets_inv = torch.stack(encoded_inv)
# Print outputs (optional)
print("Offsets:\n", offsets)
print("Inverse Offsets:\n", offsets_inv)
This should be sufficient enough to prepare a weighted interpolation starting point for BeatriXL's trained timestep embeddings.
More information soon.
The Long List
So here's the extent of what needs to happen for the full clip-suite.
clip-suite
model converter
loads any diffusion checkpoint and attempts to quantize automatically.
quantize target bools;
convert_unet
convert_tokenizer
convert_te1
convert_te2
convert_te3
convert_te4
convert_te5
convert_te6
convert_te7
convert_te8
convert_te9
convert_te10
load as; cpu / cuda
fp8, q4, q8, bf16, fp16, fp32 etc;
if your graphics card does not support the quantization, it will default to CPU and attempt to convert anyway.
if the conversion fails you'll receive an error to go complain on the github about. As you know I read everything.
save location
choose the location; automatically defaults to outputs/checkpoints
this is a single standalone node meant to convert entire checkpoints if desired.
The reason for this is the lack of RUNTIME CAPABLE LIBRARIES capable of actually running these things at runtime in a bit by bit hardware level. Currently bitsandbytes is capable of running some things, and other libraries are capable of others; however there are none capable of loading and preparing them at runtime... yet.
There are some options; but they involve hacky workarounds; like dumping existing models, calling the C++ libs at runtime, feeding them the correct model location, and simply running it alongside the program; catching errors that way. This is not an easy process and would require a wrapper of my own to interface with a program that I'm unfamiliar with, so it's risky at the best of times.
pytorch is building to it and has SOME capability with some of the nightly builds, but it's sketchy at best at times, and I don't think I want to subject random computers to this treatment.
so, load and safe save it is.
clip loader
loads any text encoder into the structure
can load encoder groups or checkpoints to extract clips from as well if you don't want to run the full loader for a checkpoint.
can hard set a configuration file or load a configuration node to feed into it
automatically detects model's configuration and pulls from the most important common repos for the models if one is known to exist, otherwise it must be manually defined if it cannot be found.
automatic or manual selection of bit, quantization, or whatnot.
automatically converts if the values don't match with a warning;
requires save and reload if Q_# conversions are selected, otherwise the behavior and quality of the inferenced version will suffer. Potentially introducing high amounts of vram or ram spikes depending the conversion, as the conversion will be imperfect and is primarily used for experimental purposes.
once saved the conversion becomes hardware permanent, allowing for a correct and careful hardware load of quantized models on next run.
OUTPUTS
ABS_CLIP
tokenizer loader
can be given a custom tokenizer configuration from the tokenizer configuration node
will attempt to load a tokenizer with the standard sentencepiece or whatever is defined by the tokenizer's configuration
ABS_TOKENIZER
model configuration node
can point at a repo, a file, or simply create one here by pasting it.
allows the direct editing of model configuration files and feeding the configuration files into the clip loader for attempted loading and utilization
string input and boolean to save named config for later use.
OUTPUTS
STRING
tokenizer configuration node
a node to manually edit a tokenizer configuration using simple plain text.
cannot edit tokenizer directly, but can point at a tokenizer file.
string input and boolean to save for later use.
OUTPUTS
STRING
vram cleaner
a passthrough that attempts to clean the vram.
attempts to clean and normalize the vram used by the system internally, attempting to free unnecessary hooks and vram.
this can be used at any point within the system and takes in any ABS_CLIP based types.
INPUTS
ABS_CLIP
ABS_CLIP_GROUP
ABS_CLIP_LAYER
ABS_CLIP_LAYER_GROUP
ABS_TOKENIZER
ABS_TOKENIZER_GROUP
OUTPUTS
matching input
clip splitter (working name)
a pipeline splitter that turns the ComfyUI "CLIP" pipeline into a series of pipelines automatically and dynamically.
example; hook sdxl dual clip to it -> CLIP_L and CLIP_G are the only output nodes.
example 2; hook hunyuan dual clip to it -> CLIP_L and LLAMA are the only output nodes.
OUTPUTS
ABS_CLIP
ABS_CLIP_L
ABS_CLIP_G
ABS_CLIP_H
ABS_CLIP_L_VIT
ABS_CLIP_G_VIT
ABS_CLIP_H_VIT
ABS_LLM
ABS_T5
ABS_T5L
ABS_T5XL
ABS_T5XXL
ABS_UNKNOWN_CLIP
ABS_UNKNOWN_LLM
likely as many as necessary
ABS_CLIP_GROUP
ABS_TOKENIZER
ABS_TOKENIZER_GROUP
clip joiner (working name)
Something that can take in any split clip from the system and reform them into the pipeline.
changing the joiner value from say sd15 to sdxl will alter the input expectations and output a different type of converted pipeline clip for the main COMFYUI to seamlessly process.
can define a tokenizer type here, or one from the subsystem manually.
INPUTS
* ABS_CLIP
ABS_CLIP_L
ABS_CLIP_G
ABS_CLIP_H
ABS_CLIP_L_VIT
ABS_CLIP_G_VIT
ABS_CLIP_H_VIT
ABS_LLM
ABS_T5
ABS_T5L
ABS_T5XL
ABS_T5XXL
ABS_UNKNOWN_CLIP
ABS_UNKNOWN_LLM
likely as many as necessary
ABS_TOKENIZER
If one is not supplied, the system will try to guess.
OUTPUTS
CLIP -> the standard comfyui inference-capable clip and tokenizer.
save tokenizer
saves the defined tokenizer with a name, alongside the configuration defined for the tokenizer as well as the defined bit conversion depending if it was converted or not.
save clip
save as a quantization or different bf value of desired; auto is default and is suggested for regular merge/save use.
saves individual split text encoder clips using their current configurations as the standard .safetensors with the standard format and layer names matching what is currently being modified.
cannot save as the same name in the same location, will automatically output to the output/abs_clips/ folder with a similar name and a number.
clip layer analyzer
similar to the outputs of the splitter, this will create dynamic nodes for an anticipated fed clip type.
this will use the configuration if one exists upward in the chain, and output the information based on the logic chain.
if no logical configuration exists upward in the chain the system will guess based on what is connected to it.
clip layer strength adjuster
a simple layer strength adjuster, which will allow the singular layers within a clip to have it's numbers tweaked based on interpolative scheduling, simple math, and so on; will link directly to math nodes for expectations and parse at runtime.
clip layer group joining
joins a series of layers together into a dict for group editing, programmatically keeping the host model's natural origination in memory to prevent ram leaks.
takes in as many layers or layer groups as you require
outputs a single "CLIP_LAYER_GROUP" type for iterative editing.
clip layer merger
will allow targeted or groups of layers to be merged together; programmatically populating the lists and options internally for ease of use.
included schedules and formulas for ease of use, will also accept I/O from external math systems when formatted correctly.
clip layer joiner
takes in a single clip and a series of layers, attempting to rejoin them to their parent if possible.
save clip layers
saves a single or layer group as a miniature safetensors model for editing in the future
config file specifically saved alongside for editing later
load clip layers
loads a single or layer group for editing based on the safetensors and config file
if no config exists, attempts to load anyway but will likely be unsuccessful
clip image interrogator
interrogates the clip with an image using the clip-interrogator and a series of additional custom features specifically targeting the common clip models that can be toggled.
LAION flavors
the clip-interrogator specific flavors defaulted to the system
BOORU flavors
a set of flavors targeting anime and booru flavors
R34 flavors
a set of flavors targeting nsfw related acts and nsfw specific details
a configuration file location to modify the interrogator's feature files that it'll attempt to target.
not the fastest idea, but it'll definitely give a good idea if your clip is lobotomized or can see what you want it to see.
outputs
STRING
ACCURACY
CHART
Beatrix is based on this entire concept with unets and diffused images; however Beatrix does not have a good controller or understanding of CLIP. I think it's a perfect opportunity to fully explore this topic and prepare some fun experimentation nodes.
clip feature finder
feed an image and caption, and it'll do it's best to target the full clip's internals based on the interrogation with multiple seeds.
attempts to find hotzones on clip layers to determine to create a feature hot-zone map of the clip
cosine, linear, interpolation, etc available for mapping and testing.
outputs CLIP_FEATURE
teach clip feature
replaces the neurons of a hot found interpolative feature map from one clip layer to another clip model or another clip layer
takes in an image, prompt, and interpolated feature to rapidly replace information
learn rate and repeats available here
outputs the modified clip layer or full clip model depending what is fed in
forget clip feature
attempts to weaken or unlearn a single interpolative feature response
similar to learn, takes in an image and a prompt
interrogates and targets feature zones that it accesses to weaken them
outputs a clip layer or full clip model depending what is fed in
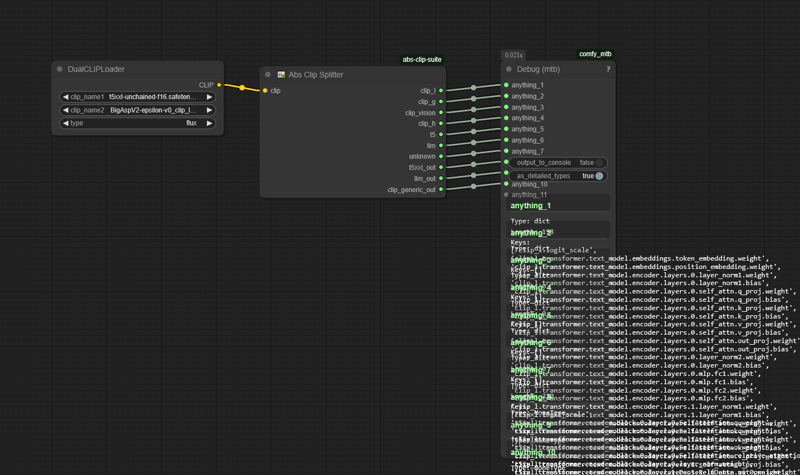
We have reached hello world point; where we have now split away the clips into separate models attached to their own internal clip-based wrappers.
Doesn't matter what CLIP you feed it; if it has the type CLIP it'll wrapper it and shove it in the square hole.
Unknown T5's go out the unknown_t5 slot;
Unknown LLMs go out the unknown_llm slot;
Unknown CLIPS go out the unknown_clip slot.
They can be seamlessly reintegrated down the pipeline after manipulating or altering the various clips within the pipeline. The reintegration will be 1:1 with the original ComfyUI to allow for seamless editing and manipulation of these clip models in an expert controllable fashion.