
Recently, I working on a project. I trained a LoRA model for a big-head toy. During the process, I discovered quite a few interesting phenomena. I’m recording them here and sharing them with everyone at the same time.
Target
Generate a toy with a fixed design, featuring a 1:1 head-to-body ratio, while preserving the toy's original artistic style.
Dataset
The dataset like this:

Label
Principles for Image Generation Annotation:
"Describe the attributes you want to control. If some content need to generate everytime, don't describe it, and simply add a trigger word without extra descriptions."
Like the white background, don't add "white background" in label file. Force model bind to trigger word.
The annotation format is: Trigger Word + Attribute Description.
Currently, the dominant model is Flux, but it’s relatively slow. So, I also tried SDXL and SD1.5. These three models have different requirements for natural language descriptions:
SD1.5:
The earliest model, mainly tag-based. It doesn’t really understand captions.
Description format:["man", "dog", "beach", "sunset", "walking"]SDXL:
Understands tags and partially understands captions. However, it struggles with overly long annotations.
Description format:"A man walking his dog along the beach during sunset."Flux:
Understands both tags and captions. Officially, using captions is recommended. Since it has two text encoders, it can handle long sentences well.
In my case, the toys are always positioned in the center, the background is pure white, the poses and body proportions are mostly consistent, and the toy style is plastic material combined with a specific design style (which I can't exactly define). So these attributes no need to describe in label, just use trigger word as representative.
What can actually be controlled includes: facial features, skin color, hairstyle, clothing style, and shoe style.
Regarding trigger word selection:
The more uncommon, the better. How to test if a trigger word is uncommon?
You can use the same trigger word with different random seeds. If the resulting images show little similarity, it suggests the word is rarely used in the base model.
In my case, I selected PNBPT as the trigger word.
Here is an example annotation:
PNBPT toy. black hair styled in a short, curly manner, is facing the viewer with a neutral expression. black skinned with black hair and a little beard, wearing a white jersey and white shorts, shoes are yellow.
The chest area of the jersey displays the green text "BUCKS", and the number "34" centered below it. The edges of the jersey sleeves are green.There are also some additional techniques and tips, which I will supplement later.
Training
I used the repository kohya-ss/sd-scripts for training. Of course, some readers might be using Qiuye's炼丹炉 (We commonly use warehouses in China, but they are actually developed based on sd-scripts) or other tools like AI-toolkit. It doesn't matter which tool to use — the underlying principles are the same.
By using Dreambooth-style concept injection, you can either train LoRAs or perform full fine-tuning. Let me briefly explain: LoRA itself is a low-rank decomposition technique called Low-Rank Adaptation of Large Language Models. It is not a model nor a training method by itself. However, out of habit, we often casually say “train a LoRA” nowadays.
Currently, the dominant approach for injecting specific concepts into models is based on Google's Dreambooth technology, which allows you to train a model on a specific concept using only a small number of images. (Of course, Dreambooth also includes regularization techniques to prevent overfitting, but we won't go into that here.)
The sd-scripts framework uses TensorBoard to record the loss curves and training parameters.
Here is the training curve:
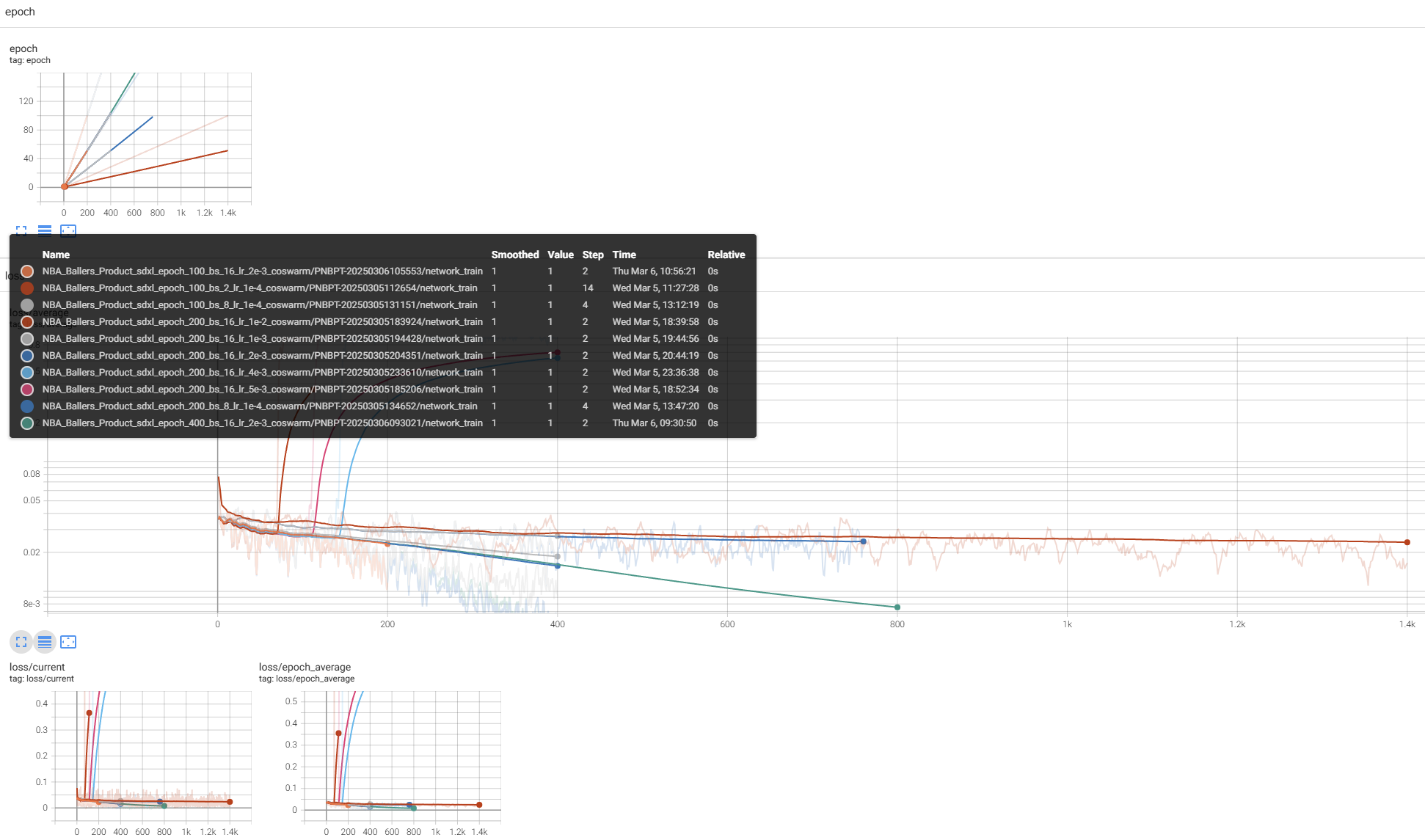
I mainly compared three sets of parameters: Learning Rate, Batch Size, and Epochs. Why didn't I compare other parameters? Firstly, based on experience from other fields (such as object detection and image classification), most other parameters generally don't need much tuning.
Moreover, the loss value can basically reflect the model's performance — in this project, a lower loss typically indicates better image generation quality.
In addition, I also compared different labeling methods. One method involved detailed annotations, as described in the previous section. The other method used only a single trigger word for all images (forcing the model to learn only a fixed style). An interesting observation is that, with the images remaining unchanged, no matter how the labeling content varied, the overall trend of the training loss curve stayed the same.
This is because during the training process, I kept adjusting the labeling content, hoping it would make the model perform better. However, the loss trends were almost identical.
Thus, I summarized a method: if you are working with a new dataset and want to quickly find the best hyperparameters, you can simply annotate all images with one trigger word and proceed with training.
Experiments and results
color control

Since we defined skin color in the annotations and the dataset contains toys with different skin tones, the model learns to associate the text with the corresponding attributes. However, it’s important to note that during training, we only fine-tuned the UNet part — the CLIP part (i.e., the text encoder and image encoder) was not trained. This means that both the image embeddings and text embeddings remained fixed. Even though the UNet is mainly responsible for image generation, it also has a certain degree of feature-binding capability.
Interestingly, although there were no yellow-skinned (Asian) characters in the dataset — only black and white — thanks to the generalization ability of the base model, the LoRA was still able to generate yellow-skinned players.
Comparison of Learning Rate, Batch Size, Epoch Parameters

Obviously, the result on the far right will be better.
One trigger word

The LoRA trained with a single trigger word showed a good loss curve and was able to generate high-quality results. However, its control over text prompts was relatively weak. It is suitable for quickly validating parameter settings.
Just to be sure, I also tested it using full prompt inputs.

The results were much better than using only a single trigger word for control.
However, from the outputs, it was clear that many attribute controls did not take effect — for example, there were extra basketballs, the clothing color was not completely white, and the skin tone was also incorrect.
Comparison with the full caption version:

Its consistency was noticeably better than the version trained with only a single trigger word.
However, even in the hairstyle part, the results were not very consistent — which, of course, is largely related to the completeness of the prompts we used.
In later face-swapping tasks, this instability would also become apparent.


For example, chicken brother inexplicably grew a beard, and James shoes were very big (perhaps his big beard provided some reference).
Overfitting problem
The problem of overfitting is very common. For example, in pedestrian detection, overfitting might cause the model to mistakenly identify objects that are not pedestrians as pedestrians. So, what does overfitting look like in the field of image generation?

Your example nicely illustrates the problem of overfitting. When you input "curly hair" into the prompt, the jersey color, shoe color, and beard type all change. It's as if the model has memorized the appearance of a certain figure.
In my analysis, why does this problem occur? Ideally, feature binding should be as you described below.
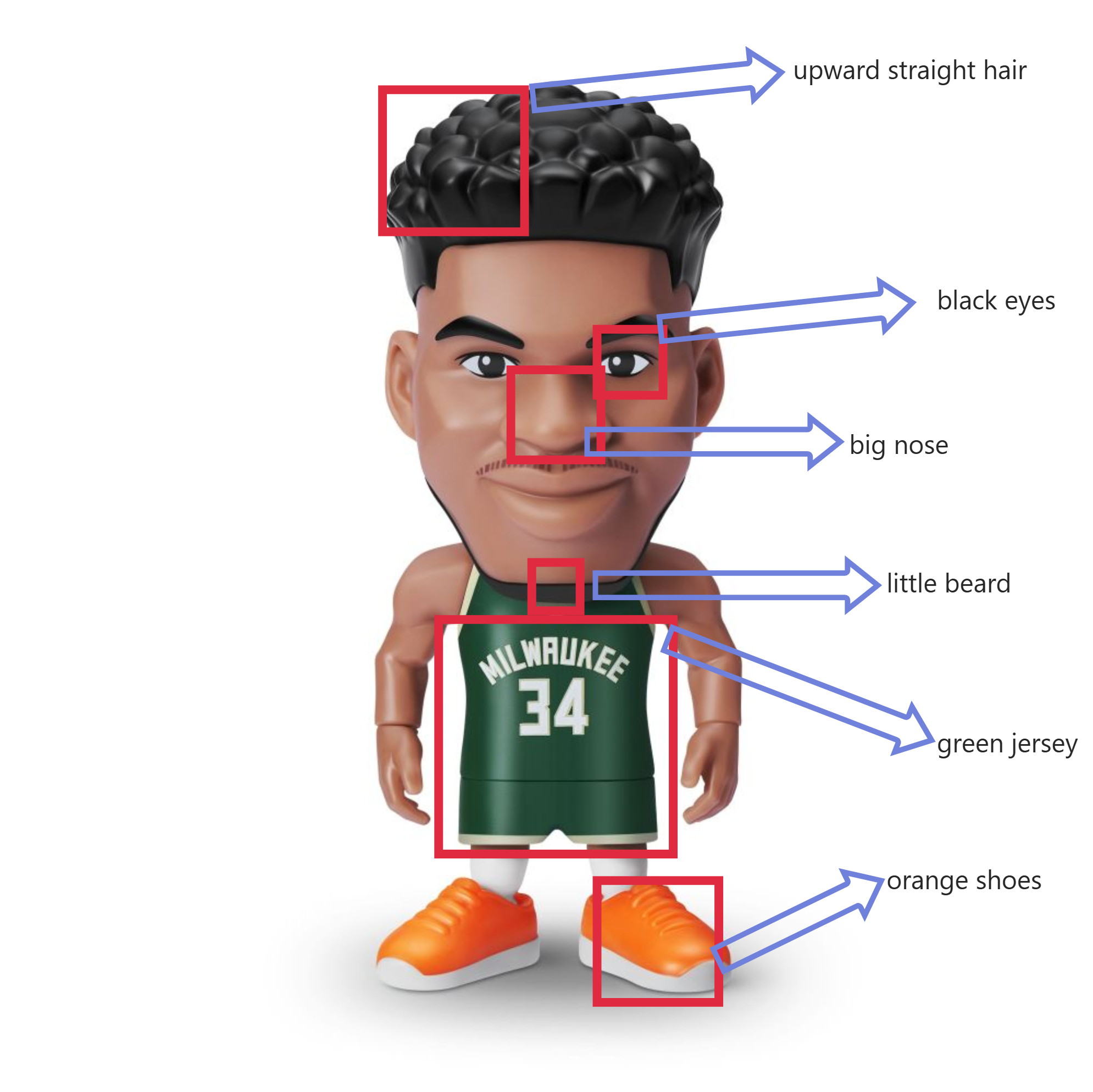
But actually, in most cases it is like this:
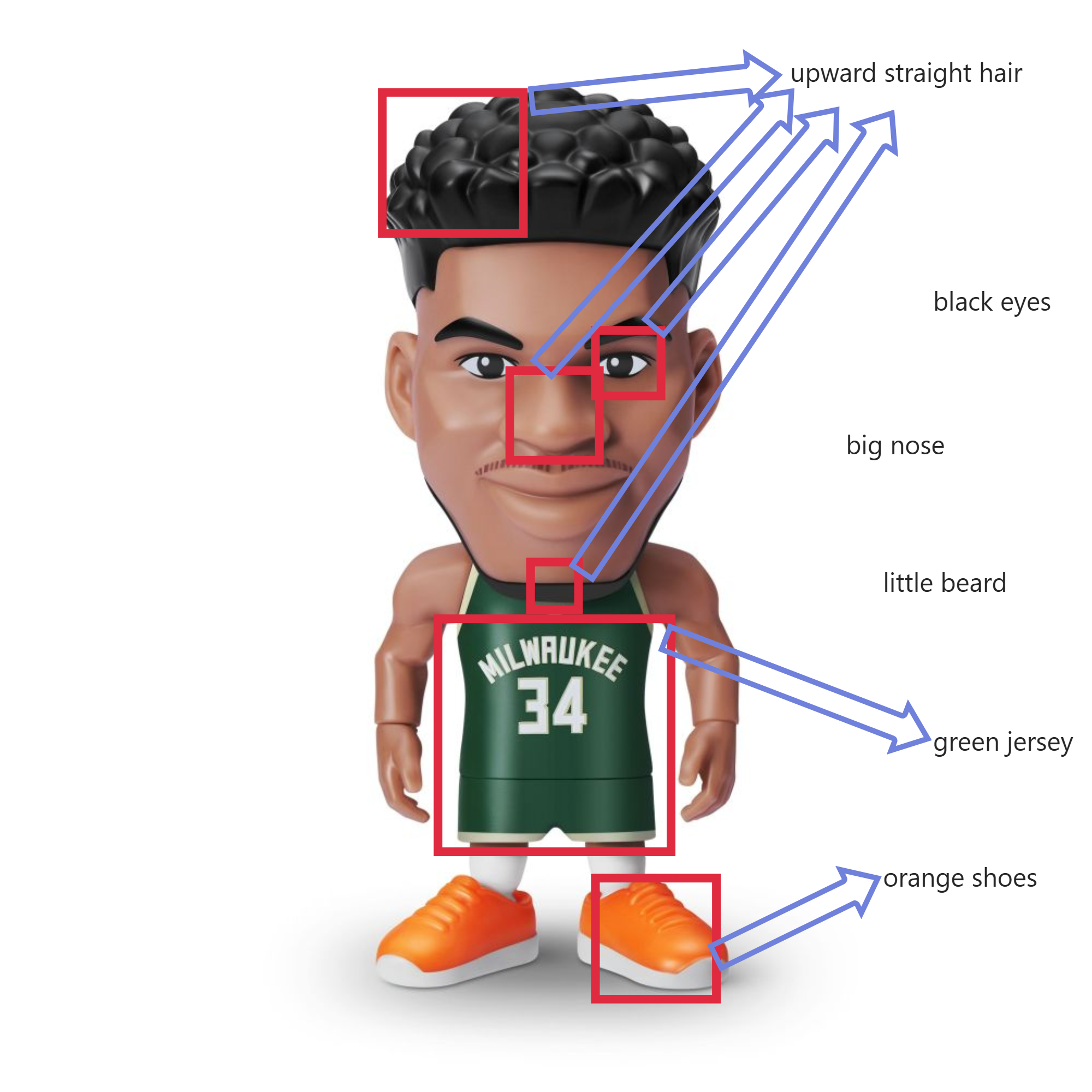
Certain words are not correctly bound, while others are bound with too many features. I've also observed that overfitting issues often occur with facial features. In contrast, attributes like clothing, shoes, and skin color tend to align well with textual descriptions. This is likely because repetitive examples of these attributes can be found in the dataset. However, facial features are unique to each individual, making it difficult to find identical samples. Essentially, it's an overfitting issue—there are too few similar examples, causing the model to memorize a fixed appearance.
Multiple trigger words
To mitigate overfitting, typically methods such as Early Stop, Dropout, and expanding the dataset are used. However, aside from Early Stop, I can't apply the other strategies due to constraints like the fixed structure of LoRA and the predefined datasets provided by designers. So, I devised another approach: binding facial features to a different trigger word.
What does this mean? Besides using the trigger word like "PNBPT" for generating a toy, I intend for another attribute to control the appearance of a face. For example:
PNBPT toy. ANTETOKOUNMPO face. black skinned with black hair and a little beard, wearing a white jersey and white shorts, shoes is yellow. PNBPT toy. EMBIID face. black skinned with black hair and full beard, wearing a blue jersey and blue shorts, shoes is white.When you describe someone with terms like "thick eyebrows" and "high nose bridge," these might not conjure a specific image in the mind. But if you have seen this person before and know their name, you can quickly picture them. Therefore, directly using the player's name as an additional trigger word is my approach to achieving a clearer image of the person.

Based on this principle, after training the LoRA, the consistency of the generated results has improved. However, the style of the clothing also seems to be bound to certain features. If you don't specify whose face it is, the model will generate random faces.

I stopped here because the next steps would involve swapping faces and changing clothes, so it's essential to decouple the attributes of faces, clothing, and styles.
This concept of multiple trigger words is also mentioned in Dreambooth. However, in my practical tests, it's still crucial to have a large number of samples for different toys. If each player's toy has a one-to-one correspondence, the results aren't very good. In my current batch, each player is represented with both home and away jerseys, which adds sample diversity.
Code
I forked a copy from kohya-ss's repository at https://github.com/Runist/sd-scripts/tree/sd3 and primarily developed on the sd3 branch. I didn't change any code, just add some config files, I have set up training parameter templates for SD1.5/SDXL/Flux and dataset parameter templates, along with startup scripts for the training commands. If you find it helpful, please give me a star. Thank everyone.
Subsequent work
There are tasks like swapping faces, changing clothes, and shoes to work on later. I'll continue writing if I have more time.
