


Hello, fellow latent explorers!
Intro
I recently started playing with Framepack. This is a nice tool for video creation, but I was relatively unsuccessfull in prompting 🙁 It is relatively random, you either have to make a short prompt and pray or write a full on essay. But then I saw a pull request adding Start and End frame control to it. Now we can force Hunyuan to do what we want and make perfect loops!
Easiest way to install it is by copying modified file manuall since it is just one file so far. And then I had a question, how to make two frames consistently?
Well, here I am sharing my way. I am doing that with Framepack gradio demo and Forge webui here.
Choosing model
There are multiple ways to do it. But concistenly and locally? Not that much. Two main ways are using Flux with prompt like "two frames of a video in a single image". But I went a different way.
Danbooru trained models (Illustrious, NoobAI etc) have a tag 2koma and we will abuse it here. There are limitations though, most of the dataset images are 2 horizontal frames stacked on top of each other. So I opted to I model I currently like, WAI-Shuffle-Noob. Be aware, this is a v-pred model. I have a separate set of articles on how to make it work and get really good results in Forge, and some comfy workflows, check them in my profile. Vertical frame generation is lacking. If you stack 2 vertical frames on top results are meh, and with having them side by side inpainting tend to introduce horizontal line.
Getting first reference
Choosing resolution
Let's talk about resolution. This is an issue. Since I am using Framepack is defaults to a standard bucket of resolutions:
bucket_options = {
640: [
(416, 960),
(448, 864),
(480, 832),
(512, 768),
(544, 704),
(576, 672),
(608, 640),
(640, 608),
(672, 576),
(704, 544),
(768, 512),
(832, 480),
(864, 448),
(960, 416),
],
Basically no matter what image you feed it, it finds one that suits it most from the list above and resizes the image accordingly. But SDXL degrades image greatly if you go below 1MP. Since we will be producing 2 frames - we will double it, but single frame results were too bad at those resolutions. This is why I ended up increasing resolution a bit.
So let's start. No artist tags, 992x576 resolution, the only lora I used is my detailer. You can check other parameters and extensions used in my previous articles.
Prompt:
1girl, breakdance, street, wall, graffiti, casual, cargo pants, black t-shirt, straight-on, short hair, green hair, brown eyes, full body, standing, light, shadow, long legs,
general,
very awa, masterpiece, best quality, highres, newest, year 2024, absurdres, highres,<lora:NOOB_vp1_detailer_by_volnovik_v1:1>,
Negative:
worst quality, low quality, bad quality, lowres, worst aesthetic, signature, username, artist name, error, bad anatomy, bad hands, watermark, ugly, distorted, (mammal, anthro, furry:1.3), (long body, long neck:1.3), extra digit, missing digit, (censored:1.3), (loli, child:1.3), stomach bulge, bar censor, twins, plump, expressionless, steam, extra ears, futanari, mosaic censoring, pixelated, (fisheye:1.3), , serafuku, displeasing, sweat, toy, animal, wet, blue skin, sketch, blur, blurry, young, blonde hair,
I will exclude quality tags and negative from following prompts since they do not change.

Top tier SDXL content isnt it? Fear not, it will get better.
Creating background plate
Now send it to inpaint tab. Mask girls and her shadow, choose denoise 0.5, inpaint whole picture, and lama cleaner in masked content.

To have this option available you have to install corresponding extension.
Change prompt to:
street, wall, graffiti, straight-on, light, shadow, no humans,
Now boom, we have a clean boackground starter:

Now open this image in uimage redactor you like (I use Krita), expand canvas height x2 and copy and paste the image:

Let's also fix the shadow a bit on top image:

I used assitant tool and airbrush soft for that. Tops skills, eh?
Now get it to img2img and set extra noise multiplier to 0,02 (since original image is kinda bad):

Now add 2koma to prompt run it at 0.5 denoise with controlnet canny
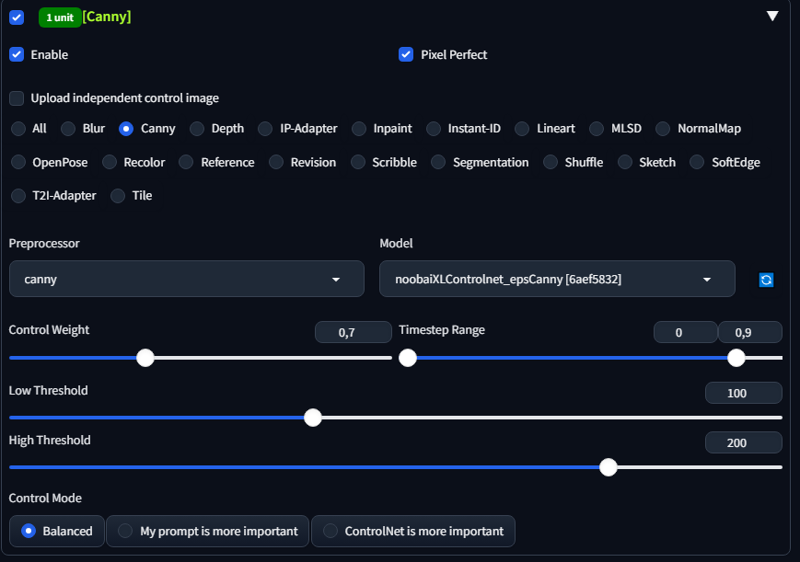

Not perfect, but good enough. Now cut out desired plate and add it copy it to the other side. I'll use top one. Save this image separately since it will be our consistent background for future use.
Adding character
Here you can simply inpaint characters on plate, or draw them above to give model some guidance. Remember first reference? Let's use it. Add character as a separate layer and use eraser to blend edges. No need for complete precision, it will get redrawn anyway.

MAD SKILLS. Am I an artist now?
Now the prompt is:
2koma, 1girl, breakdance, street, wall, graffiti, casual, cargo pants, black t-shirt, straight-on, short hair, green hair, brown eyes, full body, standing, light, shadow, long legs, one arm handstand,
Inpaint full at 0.5 denoise, dont forget to disable extra noise.

Now at first inpaint each character separately.
You can use contronnet depth to keep posture. But not in this case since lower character is meh.
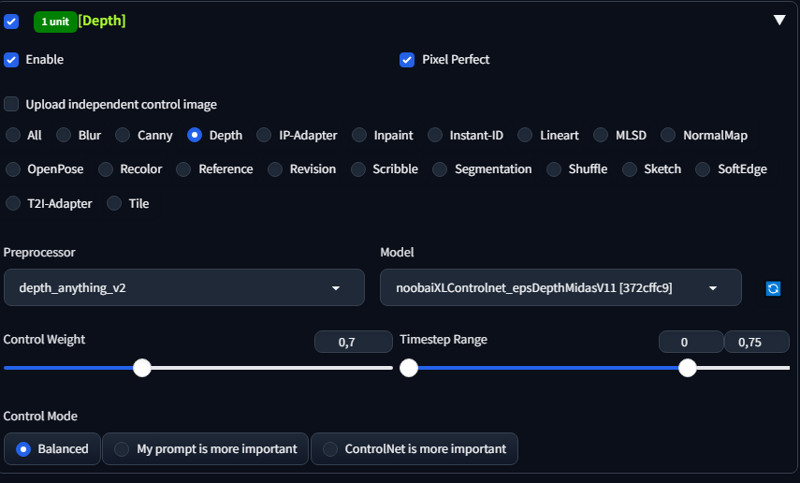
Inpaint only masked at increased resolution. Play with denoise to get desired result.

Now we have 2 slightly different character. But at least they look good. main difference is in pants. Now here comes the magic. Inpaint whole image with only upper characters pants and shoes masked at 0.5 denoise.

Here I plcaed a dot of a mask to inpaint whole image as only masked but at increased resolution of 1328x1024
Dont expect perfect one-shot result, this is SDXL. Also I dliberately chose a relatively hard picture where character is in non standart pose.

Now shoes and pockets differ. Now let's mask only them and place one dot near lower one to fit in the frame. Also I manually removed logo off her shirt. Also added converse to the prompt to get those shoes right faster.

YUP, that's better. Had to add seams to negative. Now let's inpaint upper character as only masked at 0.25 denoise to add details.

Almost perfect. Now add our background plate as lower layer and erase all edges to make background static:

This is boring, tedious and time consuming. But all segmentation methods I know to automate it are enough off to give up on them. In Krita edge detection is abysmally bad. Write in the comments if you know a better way.
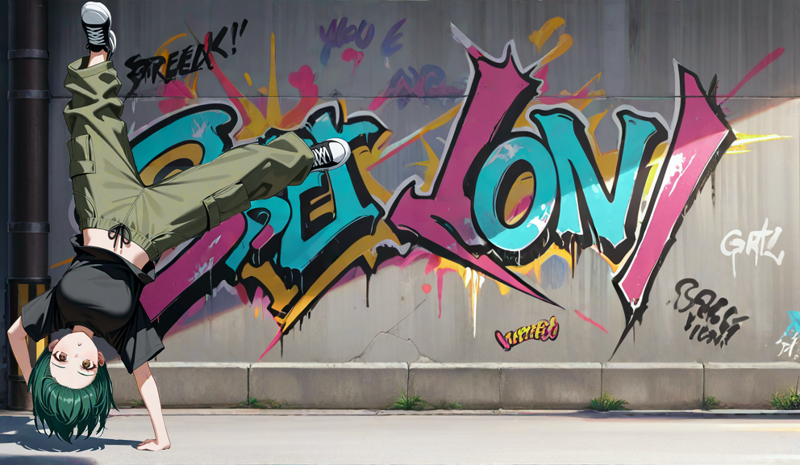
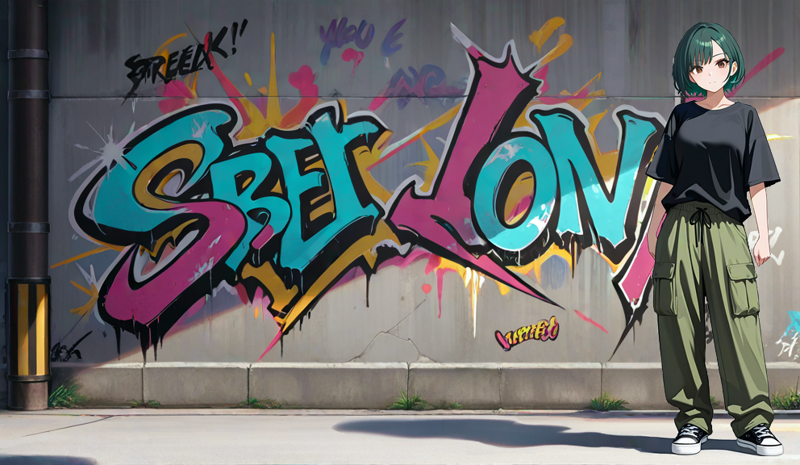
Aaaand thats it.
We have first and last frames.
Was it worth time spent? Not sure.
Result is here:
https://civitai.com/images/73564348
Also I learned today that hunyan video does not really like characters upside down, especially on first frame 😆
With enough keyframes made this way you can force it to make anything. But at the same time it is a way better interpolation between frames then anything else I've seen.
Almost forgot. When doing a lot of frames - put them all in one image and run it through autocontrast, balance tends to move off quite a bit. And in case it is a small 2s movement it introduces distortions.
This whole thing can get way easier if you use existing charater that model is aware of, or add character lora.
Please leave a like for more guides 💗