



If you find our articles informative, please follow me to receive updates. It would be even better if you could also follow our ko-fi, where there are many more articles and tutorials that I believe would be very beneficial for you!
如果你觉得我们的文章有料,请关注我获得更新通知,
如果能同时关注我们的 ko-fi 就更好了,
那里有多得多的文章和教程! 相信能使您获益良多.
For collaboration and article reprint inquiries, please send an email to [email protected]
合作和文章转载 请发送邮件至 [email protected]
By: ash0080
So, here's the situation. A few days ago, a friend in our discussion group shared a link to a photo that someone had posted on Reddit. The photo had a lot of busty women in it, and had been annotated with ControlNet Seg. The original poster claimed to have used the demo function of "anything", but didn't tell anyone how he did it. So the friend wanted to ask me about it. I started to suspect something, because the color codes used in the seg maps generated by "anything" were not consistent with the two color codes used by ControlNet Seg. I think this may be the real reason why the original poster didn't reveal the exact method he used to create the image. The seg maps generated by "anything" may not be completely accurate in terms of recognition.
At any rate, there seems to be some kind of trickery going on here. Today, I will try to take you through a test to see if "anything" is really useful for this type of image.
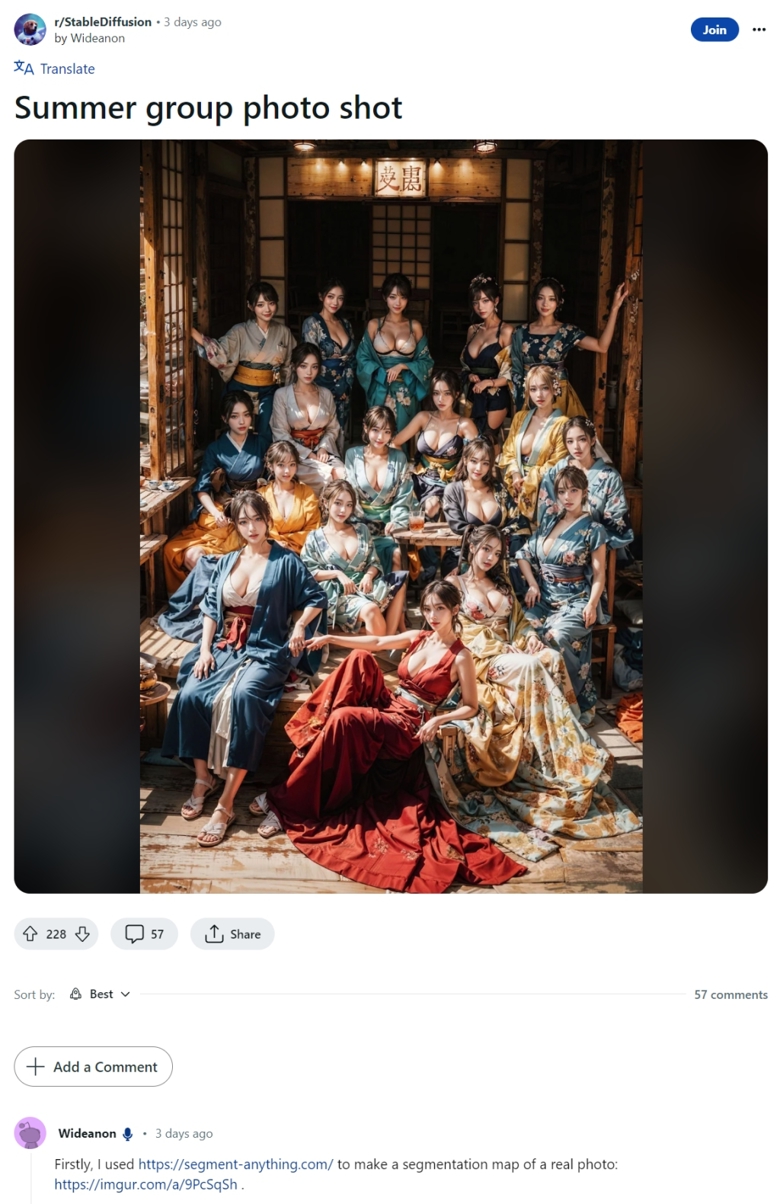
Sure, let's give it a shot!
First, let's take on a more challenging task without using "anything"!
stacked happiness
I found a family photo on the internet and used the "seg_ofade20k" preprocessor to generate a segmentation image. However, we can observe that the preprocessor has a simple problem - it doesn't differentiate between individuals in overlapping areas. Instead, it marks all the individuals in those areas as a single color, and adds a white outline around the entire group. So if we want to differentiate between individuals, we just need to segment each individual.
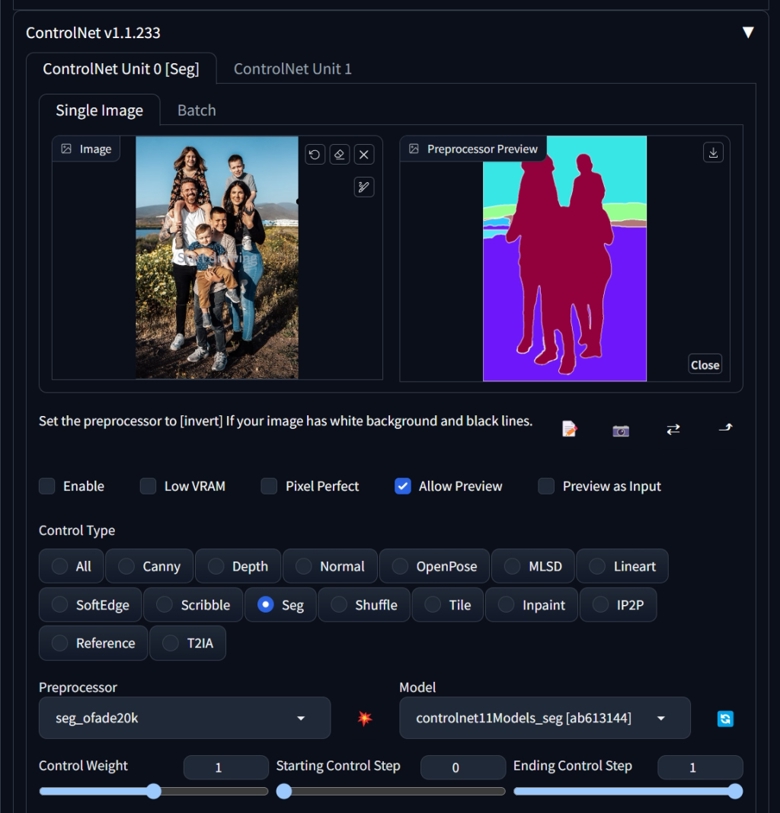
I overlapped two images in Photoshop and roughly sketched the boundaries using a brush on my iPad Pro, resulting in the image on the right. Using a brush was pretty quick, taking about 2 minutes, but it might be more difficult if you only have a mouse.

After that, Drop the image back to SD, removed the preprocessor, added prompts, and generated the final image.

You can see that there are still some errors in the overlapping areas, but this is already much better than not using "Seg" at all. You can try disabling Seg to see the difference.
If you want to achieve a relatively "perfect" final output, you would need to segment the image into multiple blocks, and repeat the process several times to combine the correctly segmented parts. Finally, you can use IMG2IMG or "tile" to enlarge the final output.
Who wouldn't want to draw a crowd of zombies?
In order to compare the performance of "anything", let's first try regular image segmentation by drawing a bunch of zombies.

The biggest problem with regular Seg is that it doesn't perform any block segmentation inside. However, it has more randomness, which reduces the chance of errors.

By adding depth of field, backlighting, and other prompts, the results are quite good.
Let's try again with the segmentation image generated by "anything". (I'll explain how I obtained that image later.)

Wow, the details and lighting have become much richer. Comparing the two images, it's not an exaggeration to say that it feels like the difference between switching from a PS4 to a PS5.

So, by increasing the segmentation detail within the image, we can indeed increase its realism. This is a confirmed fact. However, when I changed the prompts from "zombie" to "multiple girls", I couldn't draw the girls at all, because the segmentation color codes generated by "anything" are random. Therefore, it can only be used to some extent for random content. It's almost certain that the segmentation image generated by "anything" cannot be directly used without processing, or generating a picture with little detail or brightness, or significantly reducing the Control Weight.

So, if you really want to draw a bunch of portraits of people, it's more reliable to follow the method outlined in the first part of our discussion.
Finally, how to obtain the seg image from anything?
Actually, I can write a JavaScript script, but I don't have time for that. So, let me teach you the simplest and most cumbersome method.
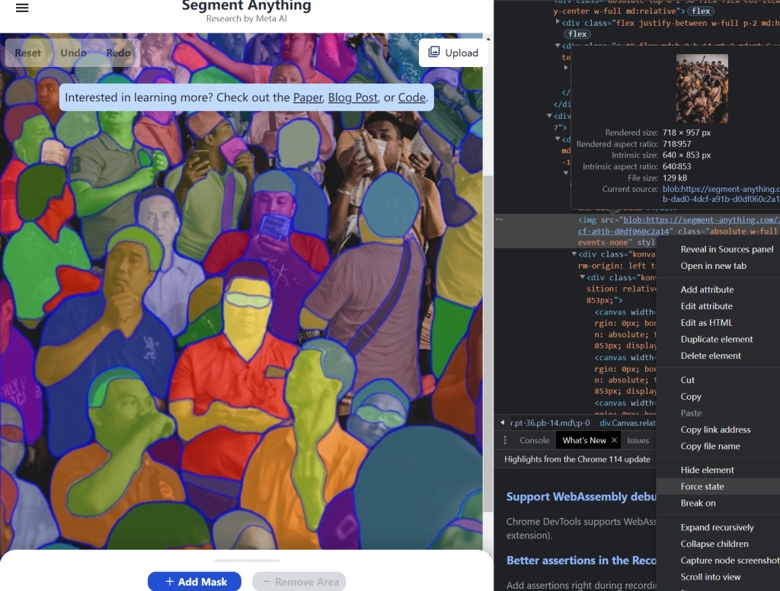
1. After uploading to the anything website and generating the segmentation, it will be displayed as a canvas overlaid on the image. Open the browser "developer tools" and find the base image. Right-click on its tag and select "hide element".
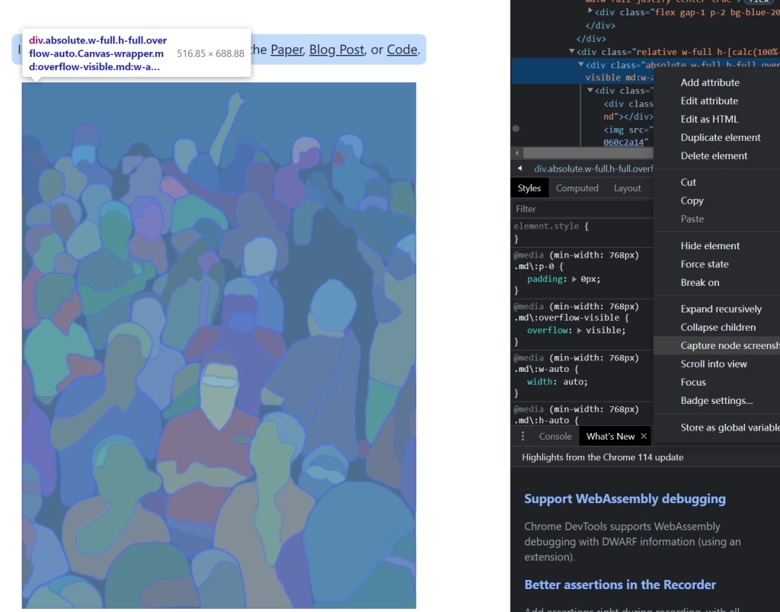
2. Right-click on the <div> layer above it, select "Capture node screenshot", and you can save the segmentation image without the base image.
Summary:
1. Seg can be used to create crowd.
2. Segmentation image generated by anything can be used with ControlNet Seg, but it is not as simple as directly using it.
3. Manual modification of segmentation is feasible and can result in more reliable results.