

简介
本文主要面向Galgame的角色LoRA的训练的入门基本框架,对于其它类型或领域的LoRA,流程虽大致相同,但具体涉及到训练集和参数,可能有诸多需要调整的地方。
就个人观察训练LoRA的门槛是拥有12G及以上的显存,8G显存能否在降低分辨率的情况下训练本人未知。
推荐完整阅读本文章,以避免遇到了一些后续才会提到讲解的问题。
当然本文需要读者至少知道Stable Diffusion生图是怎么一回事或者说如何使用的,如果是完全零基础小白可能看不懂一些接下来说的东西。例如进行模型训练需要训练器这种最基本的信息还是要知道的。
For users in other language:
This is a Character LoRA training tutotial mainly for VN (Galgame) (Ero game) character.
Please just use ChatGPT to translate cuz of course my English is worse than its... Sorry I am just lazy x_x~~~
But I will answer any of your question if I can~
训练集图片
图片选择
首先对于一个Galgame,图片的来源肯定是解包,GARbro可以解决90%的游戏解包,剩下的可能需要另辟蹊径或干脆直接截图。而Galgame的图片有两种类型,CG和立绘。
立绘是比CG要好得多的训练素材,因为立绘的服装特征全、一致性高,且没有背景。对于一个角色LoRA,没有背景只有角色的图片才是最好的训练素材。
但是没有背景不代表训练不需要背景,透明的背景中实际可能隐藏了混乱的色彩信息,这些都会被AI识别到,因此需要为所有透明背景的图片添加一个纯黑或纯白的背景。如果你对透明背景的图片进行过超分,应该会注意到,如下图。

对于CG,一般每张CG选择1~2张表情区别比较大的拆分,如下图。

对于立绘,有两种情况。
在立绘有脸的情况下,根据训练集可能的图片总数量,每套服装每个动作保留1~2张拆分,尽可能保证每套服装每个动作的表情不同,如下图。
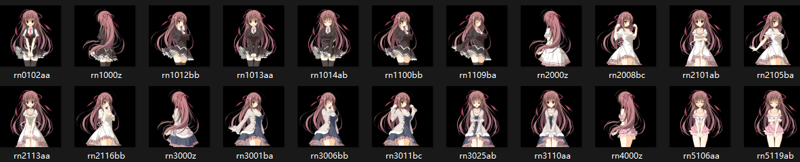
在立绘没有脸的情况下,简单保留每套服装每个动作各一个即可,如下图。

能把脸拼上去是最理想的情况,但是没有脸也问题不大,这点可以简单通过打标解决。
另一个重点是尽可能保证每套服装或者说每个特征的图片数量大致相同,以保证所有服装以同样的速度拟合,大多数情况下不太用担心这点,但如果要保证本身原文件图片中出现频率很少的特征的训练效果,就需要着重考虑了,接下来举一个出现很少的服装的极端例子,如下图。

由于该套服装在本人选取的全部85张图片中只出现一次,因此最后的结果就不能保证在其它特征不过拟合的情况下有比较高的还原度,具体到图中就是服装上的印花样式和腰带上的抽绳等细节。
有时还会出现一些质量比较低的素材。对于AI来说,质量比较低一般指的就是眼睛糊、手比较复杂、有难以辨认的特征,这种情况下会导致一些特征非常难拟合,而另一些特征又非常容易过拟合,以下是一个集百家之短但又不得不用的例子:

该图中角色的左手缩在袖子里,只露出一半弯曲的四指,对于AI来说过于复杂了;裙子上的猫形装饰物根本无法识别,即使用jingle bell或者cat ornament这样的tag对AI来说也只能模糊地识别,可能这一轮认识下一轮就不认识了;脖子上的铃铛和挂绳偏模糊,AI难以还原;右眼被头发遮挡而完全模糊;颈圈两圈的结构过于复杂,AI无法理清。
在条件允许的情况下,应该避免使用有上述特征的图片。
图片处理
为了保证图片的多样性,可以观察一下图中服装是否是对称的。如果是对称的,可以考虑把一些拆分进行反转,如下图。

这个方法也可以在训练集图片过少的时候使用以增加图片量和多样性。
但是如果服装不是对称的,则不建议反转,否则本来该一直在一侧的特征可能会跑到另一侧,甚至两侧都有,常见需要关注的是发饰。
对于有多人的情况,在能够保证角色完整的情况下,可以考虑进行裁剪(一般是裁剪成方形,涉及到后续我的个人习惯),如下图。

接下来是个人的习惯,如果使用bucket可以考虑不进行这一步,也就是对图片进行缩放,首先对所有图片以其最长边为边长添加一个方形黑色背景,图片本身居中,之后根据原始图片的分辨率将图片缩放到1024p或1440p,如下图。
1024p方形在batch size=2的情况下需要的显存大约为12G,而1440p在batch size=2的情况下需要的显存大约为13.5G。1440p的训练速度会比1024p慢几乎一倍。
1440p的训练效果肯定是比1024p要好的,但如果原图分辨率偏低还是选择1024p比较好,比如现在主流的十年前的游戏的原图分辨率只有720p。
还有另一个比较少见的情况,就是将一张完整的立绘裁剪成不同的部分,这样也是可以接受的,而且在部分情况下可以帮助AI更好地理解一些很细的特征细节,比如脖子上的铃铛,裙子上的花纹等。在图片数量很少的情况下,也可以通过这种方式增加图片数量。
但这样需要在后续打标环节具体标准身体展示的部分(upper body, lower body, close-up...)。另外,有时裁剪后的分辨率会很低,这时候就需要进行超分。
如下图。

到这里训练集图片就处理完成了。
训练集打标
本人使用的是b站up主秋葉aaaki的整合包,图片来源其UI界面,训练器整合包的下载不在本文范畴内。
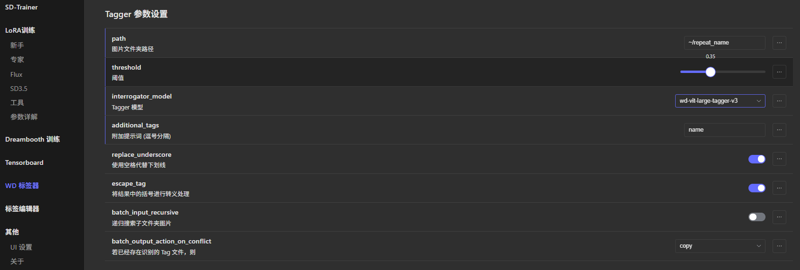
使用WD标签器进行简单打标,阈值为0.35,模型个人常用wd-vit-large-tagger-v3,记得用附加提示词把角色的名字作为触发词打上去,如图。
之后使用标签编辑器进行具体处理,这一步非常重要。
对标签的处理遵循以下规则为最佳:
对于你想让角色tag直接触发的特征,或者说你想训练进角色tag的特征,进行删除,一般为通用的发型、发色、瞳色、胸部大小(保留breast),偶尔会涉及到发饰。
对于所有立绘图,尽可能打全画面视角(front view, from side...)、面朝方向(looking at viewer, looking back...)、身体展示的部分(full body, upper body...)、角色的动作(arm up, clenched hand, hands on own hip...)
对于所有服装特征,尽可能打全而具体,不确定有没有的tag可以上Danbooru进行查询。
例如对于同一个裙子,如果识别到的skirt总共有"skirt, miniskirt, black skirt, grey skirt, plaid skirt",那么就需要删除"skirt"而保留剩下的所有标签。
另一个例子是蝴蝶结领带,可能识别到的tag有"bow, pink bow, bowtie, pink bowtie",那么就只需要保留"pink bowtie"。
还有的例子是tag模型难以识别出来的特征,例如"feather hair ornament",这是SD模型能认出来但是tag模型认不出来的,需要自己单独添加。
对于同一套服装,保证标签的一致性,例如同样一套校服,不要这套用"white shirt",另一套用"white jacket",应该统一只保留其中一个。
为所有没有脸的立绘添加"no eyes, faceless",根据性别添加"faceless male"或者"faceless female"。一般来说,tag模型能识别并自动添加这些tag中的至少一个,本人也很少主动添加这些tag,但是做这一步也只是几秒钟的事情。
如果你进行了我上述的为CG添加黑色背景的步骤,则需要对所有这样的CG打标"letterboxed",也就是电影黑边的意思。一般来说,tag模型可以识别并自动添加,但难免有漏网之鱼。
以下是一个图片和其标签的例子。
Sakuragi Mizuha, 1girl, black pantyhose, solo, black background, pleated skirt, shoes, full body, school uniform, long sleeves, simple background, black footwear, white skirt, loafers, standing, hairclip, faceless female, twin braids, two side up, hair bow, miniskirt, faceless, blue bow, facing viewer, serafuku, breasts, closed mouth, front view, no eyes, white jacket, white sailor collar, waist ribbon, purple ribbon, orange bowtie
删除了"long hair", "white hair"等该角色通用的标签,且所有服装特征几乎都打上了对应的标签,可以一一对应。
该图片直接识别出来是有"hair ornament"标签的,这里就需要替换成更准确的"hairclip"。
保留了发型的"twin braids, two side up",主要是因为该角色有另外的发型,如果追求发型的自由度也应该保留。
几乎没有笼统而不具体的大类tag,比如"jacket, skirt",而是全都换成了带有具体描述的tag。
tag模型在识别时还可能将该套服装识别为"shirt, white shirt",全部被统一成了"white jacket"。
参数相关
参数这一步其实是最轻松或者说没那么重要的,完全是只有刚入门的时候会需要思考一下。接下来讲的内容中也有很大一部分来源于我的个人习惯,不同的教程可能讲解完全不同的习惯和策略,但大同小异,只要能出好结果就是好策略。
训练集文件夹结构
鉴于该文可能有完全没有训练经验的新手观看,讲一下训练集文件夹目录结构。
随便为一个总训练集文件夹取个名字,个人习惯用"<角色名字>training"。
在该文件夹下,为你要训练的tag新建一个文件夹,命名为"<repeat>_<tag>"。其中<repeat>是本次训练中每张图片每轮重复的次数(2~10),<tag>是就是你要训练的tag。
例子如下(~/樱来瑞花training/2_Sakuragi_Mizuha):
--樱来瑞花training
----2_Sakuragi_Mizuha
------Miz_1.png
------Miz_1.txt
------Miz_2.png
------Miz_2.txt
------……
个人常用的repeat数是2。
训练的拟合速度会随着你的repeat数大幅度增加而非简单的线性增加,例如repeat=2, eopch=50的情况和repeat=1, epoch=100的情况,虽然每张图片都重复了一百次,但前者的拟合速度要显著快于后者,所以需要考虑所有参数的协调性。
参数
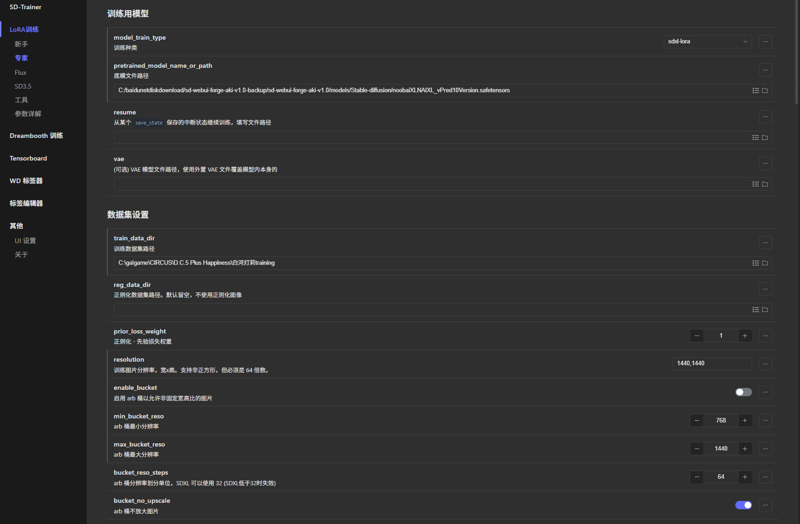
现在训练二次元相关内容肯定都是sdxl为基础的illu、pony或noob底模,所以肯定要在这个所谓“专家”模式进行sdxl训练。
我没有讲到的参数一般保持默认即可,感兴趣可以自己尝试。
底模选择你要使用的底模,一般建议用最原生的illu、pony或noob底模进行训练,而不推荐使用其它二次融合训练过的底模,但也可以考虑,比如WAI-Illu。
本人目前习惯使用Noob XL vPred底模进行v预测训练。关于v预测训练,后续会进行补充说明。
训练数据集路径填刚刚的总训练集文件夹。
本人习惯不使用bucket,分辨率填写你的训练集图片分辨率,即1440,1440或1024,1024。
本人使用50系显卡,所有精度相关都为bf16,但fp16应该是更泛用的省显存的选择。
每1轮epoch保存一次模型,方便后续测试。
保证每张图片重复大约100次,但对于训练集图片数量很少的情况,可以考虑每张图片重复到200次。
本人的max epochs最大训练轮数为50 epochs,有时会拉到100或80 epochs,对应我刚刚提到的repeat=2。具体取决于具体总步数或者说训练集图片数量。
本人的batch size批量大小是2,理论上在显存允许的情况下越高越好,可以加快训练速度,但拉高batch size需要提高学习率,一般是1:1线性提高,也有batch size每乘以2,学习率就乘以√2的说法。
打开梯度检查点,很多教程都没有提到,默认也不打开,但是是必需的,否则训练会非常慢,速度相差几乎10倍。
仅训练U-net可开可不开,开启会让最后的文件大小小一点,具体作用不大。该选项与打标无关,开启也是需要打标的。
本人的U-Net学习率是2e-4~4e-4,text encoder学习率是U-net学习率除以10。分辨率越高,需要的学习率就越高,但后续的dim和alpha参数设置的越高,学习率又要相应降低。在batch size=2的情况下,可以从2.5左右开始尝试。
学习率调度器使用cosine_with_restarts,重启次数为3。
本人的优化器使用默认的AdamW,50系的环境目前不稳定,一般来说可以选择更省显存速度更快的8bit版。
本人dim为8或16,取决于图片数量和你希望AI记住多少细节,一般依据是画风光影和服装数量。如果训练集只有二三十张图并且需要记住的服装只有一两套,那么8即可,如果有大几十张图且有很多套服装,那么16已经足够。dim和LoRA文件大小是成1:1线性正比的,dim=16的LoRA大小已经达到90m+。训练画风需要更高的dim或使用lyCoris训练,不在本文范畴内。
alpha填写为dim的一半,也就是4或8。
低的dim和alpha需要提高一点学习率,反之亦然。
日志前缀填一个你记得住的或者能区分出来的,方便后续测试。
caption选项效果未知,可以尝试,本人打开shuffle caption并且keep tokens=4。
以下两个参数能有效解决训练集导致的明暗问题,在v预测训练中效果显著,推荐一直打开,但使用一般的illu模型进行e预测也就是传统训练时效果一般:
multires noise iterations 多分辨率金字塔噪声=6
multires noise discount 多分辨率金字塔衰减率=0.3
默认打开xformers,对比sdpa提速大约15%。
以下是一个我的训练参数实例(除目录名称):
model_train_type = "sdxl-lora"
pretrained_model_name_or_path = "~/sd-webui-forge-aki-v1.0/models/Stable-diffusion/noobaiXLNAIXL_vPred10Version.safetensors"
train_data_dir = "~/白河灯莉training"
prior_loss_weight = 1
resolution = "1440,1440"
enable_bucket = false
min_bucket_reso = 768
max_bucket_reso = 1440
bucket_reso_steps = 64
bucket_no_upscale = true
output_name = "Shirakawa_Akari_1_nai"
output_dir = "~/Lora"
save_model_as = "safetensors"
save_precision = "bf16"
save_every_n_epochs = 1
save_state = false
max_train_epochs = 50
train_batch_size = 2
gradient_checkpointing = true
network_train_unet_only = false
network_train_text_encoder_only = false
learning_rate = 0.0001
unet_lr = 0.000277
text_encoder_lr = 0.0000277
lr_scheduler = "cosine_with_restarts"
lr_warmup_steps = 0
lr_scheduler_num_cycles = 3
optimizer_type = "AdamW"
network_module = "networks.lora"
network_dim = 16
network_alpha = 8
log_with = "tensorboard"
log_prefix = "Shirakawa_Akari_1_nai"
logging_dir = "./logs"
caption_extension = ".txt"
shuffle_caption = true
keep_tokens = 4
max_token_length = 255
multires_noise_iterations = 6
multires_noise_discount = 0.3
seed = 1337
mixed_precision = "bf16"
full_bf16 = true
xformers = true
lowram = false
cache_latents = true
cache_latents_to_disk = true
persistent_data_loader_workers = true
v_parameterization = true
zero_terminal_snr = true
v2 = false
scale_v_pred_loss_like_noise_pred = true关于V预测训练
以Noob XL进行V预测训练时,需要替换训练器中的脚本包,并在自定义参数 ui custom params中添加以下参数(该部分参数不会随着下载配置文件而保存,每次导入先前的配置文件需要再次输入,需注意):
v_parameterization = true
zero_terminal_snr = true
v2 = false
scale_v_pred_loss_like_noise_pred = true关于训练器的脚本包,来源为站内文章如何在v预测模型上训练LoRA | How to train a LoRA on v-pred SDXL model。对于秋叶训练器,将根目录下scripts文件夹中的stable文件夹替换为新脚本包即可,名称当然需要保留stable,注意文件目录结构,不要发生多套了一层文件夹的情况。
个人怀疑scripts文件夹中的dev文件夹就可以使用,但没有进行确认和尝试,如果确实是的话,备份原本的stable文件夹,之后将dev改名成stable即可。
结果测试与选取
如果你按照我上述所说设置,那么你会获得很多不同的结果LoRA文件,后面的数字代表了不同轮次epoch产生的对应结果。
就像煮饭不可能越煮越好吃,训练也有烧糊了的时候,也就是过拟合,所以并不是最后一个结果就是最好的。
首先打开训练器中的Tensorboard,重点关注loss/epoch的图表,下图是一个例子:
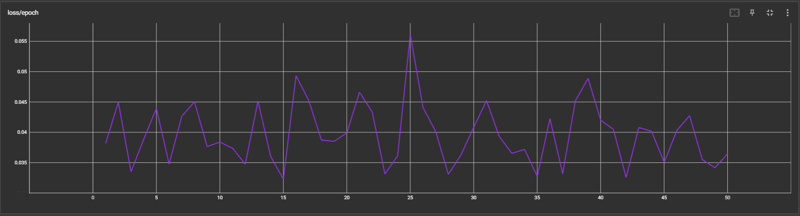
如果你将右侧的的smoothing拉成0,就会得到这么一张最原始的图表。如果你的训练集样本数很多,推荐从30左右找一个谷底开始测试,测试方法就是打开你的Web UI正常用那个epoch跑图即可。如果你的训练集样本数比较少,可以考虑从40左右的谷底开始测试。我不知道为什么有些教程里的图表都看上去那么丝滑合理,可能是我哪里确实设置错了,或者说别人把smooth拉的很高,但我的方法确实是有用的。
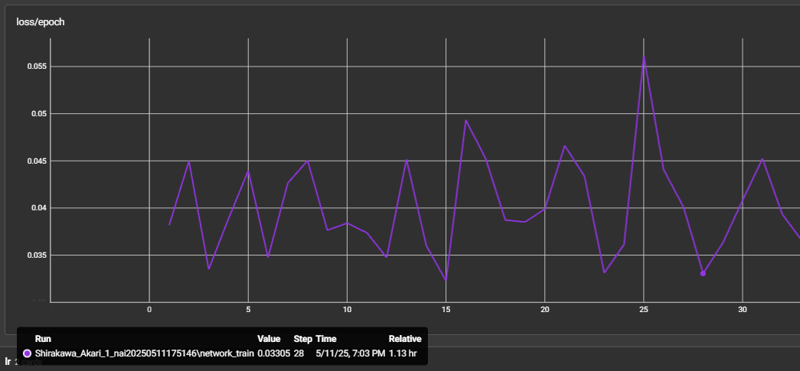
如果你发现某套服装不够拟合,某个特征训练效果不够还原,那么就继续测试下一个谷底。如上图,最开始我选择测试第28个epoch的结果,但发现某个服装不够拟合,于是用同一套服装测试下一个谷底(从上一图中可以看到是35)。
如果你测试时发现某套服装已经拟合得很好了,可以考虑往前测试一个谷底。
如果你发现图片中会生成奇怪的色块,或者眼睛细节非常模糊,或者手指非常容易崩坏,就说明过拟合了,需要大幅度往前选择测试的LoRA。
之后有两个选择:
如果你得到了这样两个谷底,一个没有完全拟合,但下一个都拟合了却容易崩手,那么将这两个谷底之间的LoRA全部测试一遍,找到一个服装表现优秀且不容易崩手的。
如果你已经得到了一个很优秀的LoRA,尝试进一步测试相邻的两个LoRA,看看是不是细节表现更好或更不容易崩手。
关于测试的方法,以下是一些我常用的测试动作:
坐着招手
1girl,solo,smile,sitting,on bench,waving,front view,looking at viewer,depth of field,lens_flare,
坐床上伸手拥抱
1girl,solo,sitting,on bed,front view,straight-on,looking at viewer,reaching towards viewer,outstretched arms,shy,blush,knee up,
教室侧面照
1girl,solo,looking at viewer,sitting,from side,arm support,on chair,desk,indoors,window,curtains,day,arm on table,depth of field,lens_flare,
拉窗帘手指嘴
1girl,solo,smile,window,standing,curtains,curtain grab,looking at viewer,front view,cowboy_shot,finger to mouth,
躺床上胳膊过头微笑
1girl,solo,smile,on bed,lying,on back,front view,looking at viewer,arm above head,straight-on,knee up,主要是测试手的表现,难度从上到下增加。
在秋叶Web UI的最下方有一个脚本功能,选择X/Y/Z plot,x轴类型选择Prompt S/R,x轴的值输入你想测试的LoRA的轮次(对于最后一个LoRA,可以重命名一下添加同格式的轮次的后缀,但是一般不会测试到最后一个LoRA)。要注意,第一个值为提示词中你选择的LoRA轮次的值。该功能会在你生成完一个图片后,自动在提示词中找到当前的字符串的值,并替换成下一个字符串的值,继续再以同样的种子再生成一张图片。这可以帮助我们方便地一次性测试很多LoRA。如图。
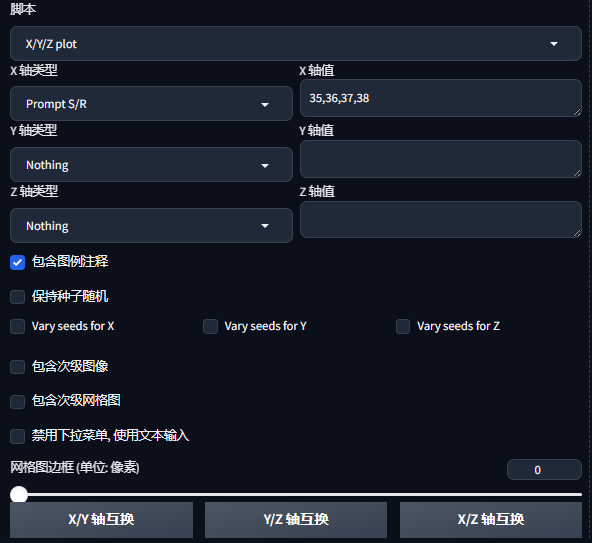

上图中,由于该套服装中的红色夹克样本量显著少于其它服装,且tag与其它服装有重复,直到最后有些过拟合也没能还原出该套服装,也算是一个反例,这时候只能放弃这套服装。
本文就到这里,应该已经把我所知道的东西讲解得比较全面了,如果有问题也可以评论提问,希望大伙都能炼出自己满意的LoRA~