

🎯 Objective
Evaluate the performance and integration of the Devstral model from Mistral AI, running locally using Ollama, within the developer environment of Visual Studio Code (VS Code) using GitHub Copilot.
🧩 Components Used
Ollama: Local model runner (https://ollama.com)
Devstral: New coding-focused model from Mistral (Devstral info)
Visual Studio Code: Code editor (https://code.visualstudio.com)
GitHub Copilot: AI assistant by GitHub (https://github.com/features/copilot)
🛠️ Setup Instructions
Step 1: Install Ollama
To run Devstral locally:
Go to https://ollama.com
Download and install Ollama for your OS (Windows/Mac/Linux).
Once installed, open a terminal and run:
ollama run devstralThis will download and prepare the Devstral model for local inference.
Step 2: Install Visual Studio Code
Download the latest version for your OS and install it.
Install recommended extensions:
Python (if you’re working on Python projects)
GitHub Copilot
Step 3: Activate GitHub Copilot
In VS Code, go to Extensions (
Ctrl+Shift+X) and install GitHub Copilot.Sign in to GitHub when prompted.
Copilot should now be active in your editor. You’ll start seeing autocomplete suggestions as you type.
Step 4: Enable Ollama + Devstral in VS Code
Github Copilo offer now the option to set Ollama with you local models:
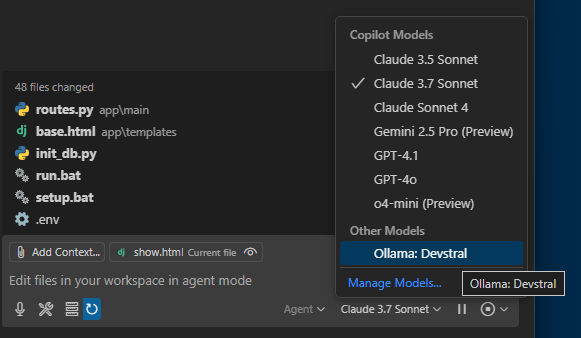 As shown in the screenshot you’ll now see
As shown in the screenshot you’ll now see Ollama: Devstral listed as an available model alongside Claude, GPT, etc.
When you clic on Manage Models you can select your models
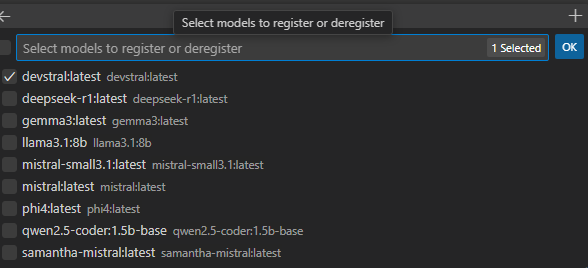
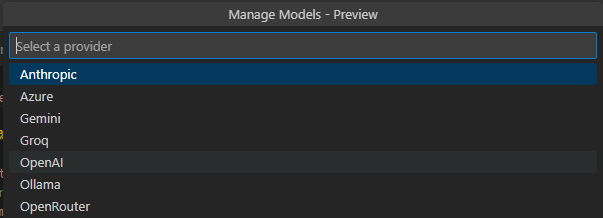 When you click on Ollama, you can set the locam models that you have installed.
When you click on Ollama, you can set the locam models that you have installed.
⚙️ Observations
Devstral performed quite well in code generation, particularly for Python and web frameworks .
It's fast and responsive when run locally via Ollama, and it's a solid alternative to cloud models, the speed depends of your GPU.
However, the Agent Mode in Visual Studio Code didn’t work correctly during tests — the agent mode worked as the Ask mode.. This might still be an early integration issue or a compatibility bug in VS Code plugins.
✅ Conclusion
Running Devstral locally using Ollama and integrating it into VS Code offers a promising experience for developers who want fast, local LLM performance with reduced cloud dependency. It's particularly useful when working on private codebases or when you need consistent latency.
That said, Agent Mode support is not stable yet, so it’s best used in autocomplete/code-completion contexts for now. As the ecosystem matures, we expect full support to arrive soon.