

The field of artificial intelligence has witnessed remarkable advancements in recent years, and one area that continues to impress is text-to-image generation. On 26th July, StabilityAI released the SDXL 1.0 model. [1]
Following the research-only release of SDXL 0.9, SDXL 1.0 emerges as the world’s best open image generation model, poised to set new standards in creativity and quality.
The Best Open-Source Model?
SDXL 1.0 represents Stability AI’s flagship image model and has undergone extensive testing to solidify its position as the leading open model for image generation.
It outperforms the previous StabilityAI models [1],
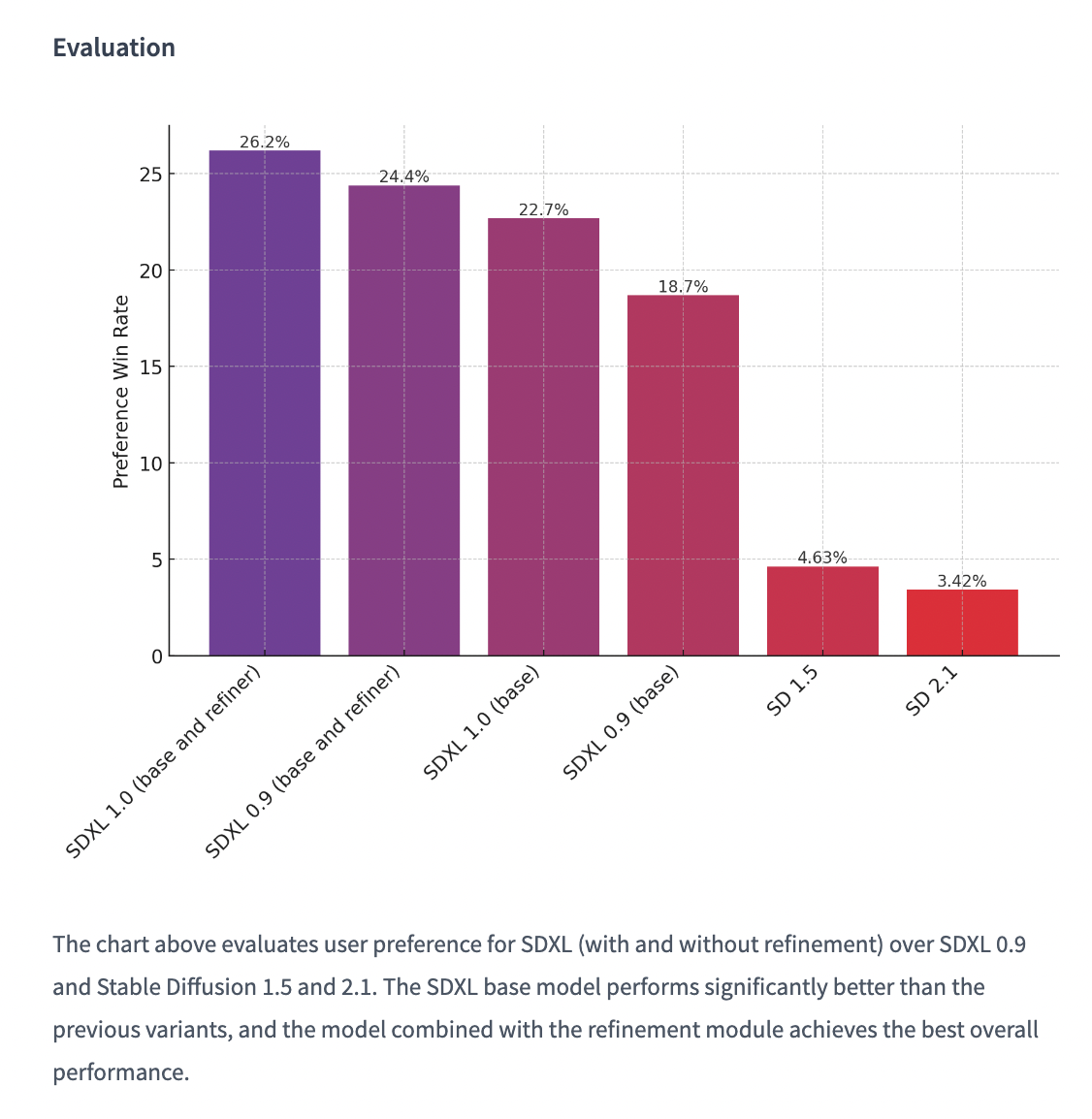
But also other open-source models, including Midjourney [4].
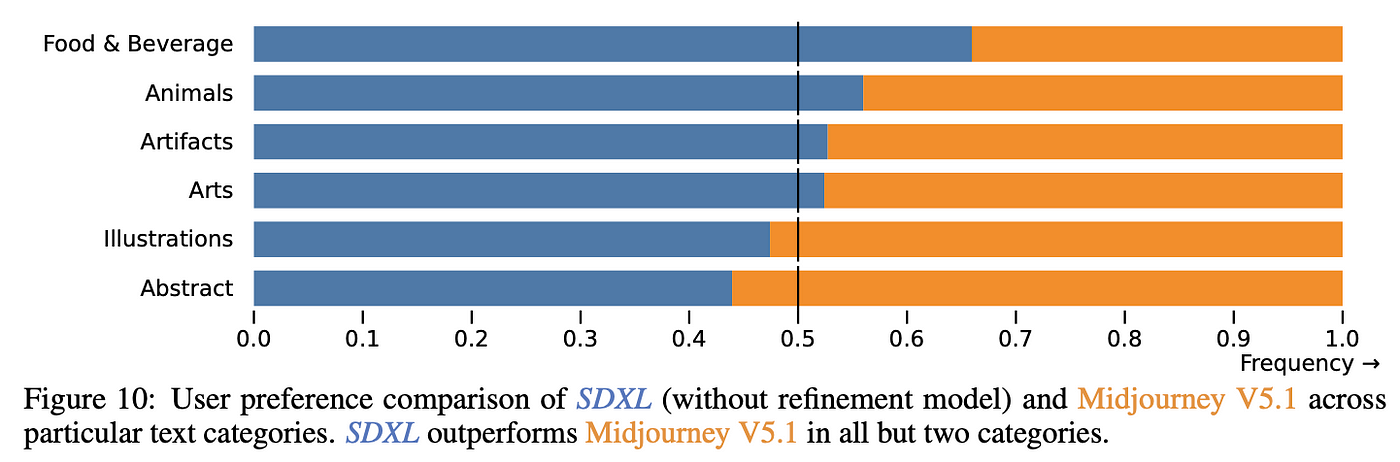
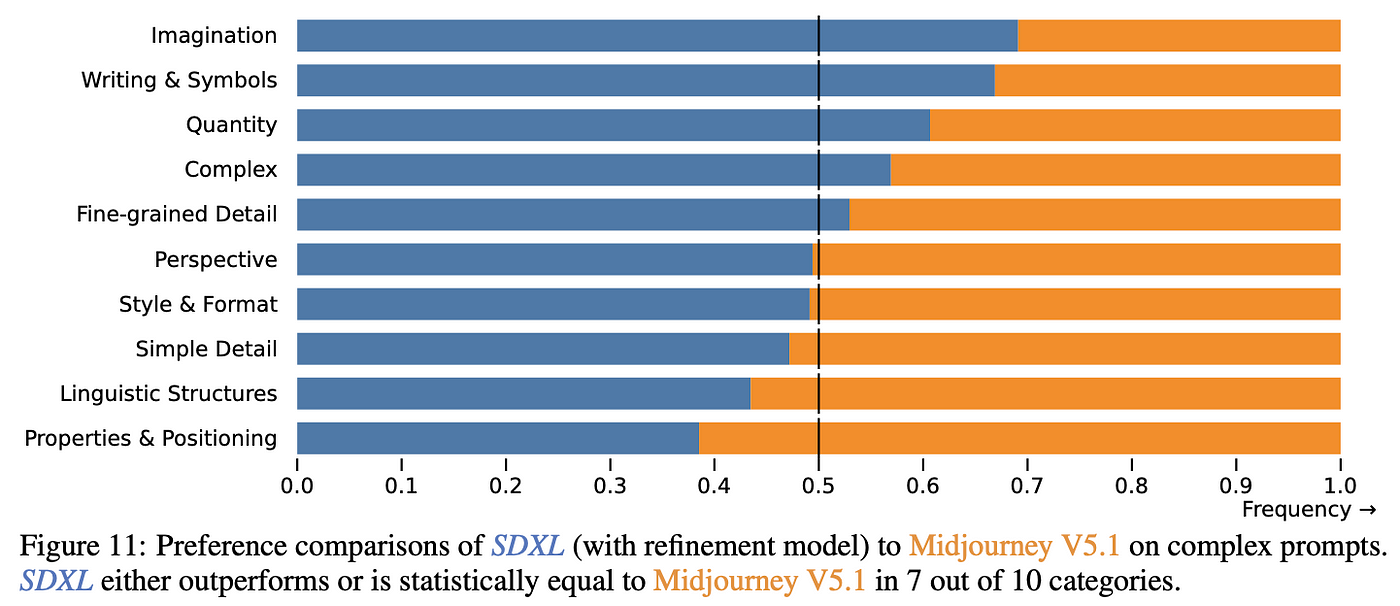
Or at least, this is what comes out from the main paper D. Podell et al. [4]
What Has Changed?
SDXL can be split into two models:
SDXL Base
SDXL Refined
What’s the difference between the two? The base model is a standalone model and can be used as such. The refined model is an additional part of the SDXL Base model aimed at improving the visual fidelity of samples generated by SDXL Base. In simple words, it applies the img2img technique to the latent generated by the SDXL Base model.
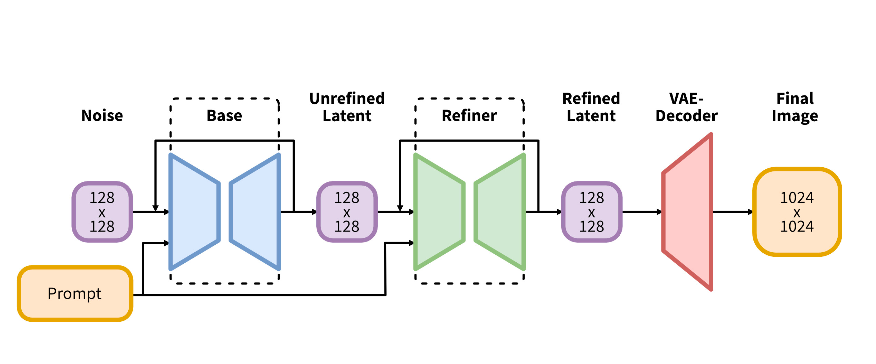
Said that, the main changes that characterize SDXL compared to previous SD models [4]:
They used a U-ViT architecture, i.e., a UNet with a transformer backbone. From this, they have shifted the bulk of the transformer computation to lower-level features in the UNet.
They used a more powerful pre-trained text encoder, which is a combination of OpenCLIP ViT-bigG and CLIP ViT-L.
They used a larger cross-attention context.
The model includes two new conditioning techniques which do not need supervision: (1) conditioning on image size, and (2) conditioning on cropping parameters.
The model is fine-tuned to handle different aspect ratios.

These changes have increased the number of parameters by 3 times (3x) compared to the previous Stable Diffusion models. Nonetheless, SDXL 1.0 is suitable for consumer GPUs with 8GB VRAM or readily available cloud instances.
Perfect for Photorealism
One of the striking features of SDXL 1.0 is its ability to produce high-quality photorealistic images.
SDXL 1.0 particularly excels in vibrant and accurate color rendition, boasting improvements in contrast, lighting, and shadows compared to its predecessor, all in a 1024x1024 resolution.

Some limitations: hands, concept bleeding, and text seem to still be an issue. Let’s test it!
Exploring SDXL 1.0
In this section, we are going to quickly explore SDXL 1.0 using ComfyUI/A1111.
According to the main StabilityAI article, prompts don’t have to be as detailed as we are used to; a few simple words are enough to generate stunning high-quality images. Let’s try this simple prompt:
"A portrait of a woman with long hair, blonde, green eyes, hyper-realistic, hyper-detailed, 8k, cinematic"
What we've found is truly amazing! Granted, concept bleeding is a slight hiccup, as previously mentioned — we've seen a verdant overload with green eyes transforming into a green ensemble complete with background, even when we only asked for the eyes.
Let’s have a look at more challenging concepts, such as hands and text. [1]
Positive Prompt: "A beautiful woman holding a flower"
Negative Prompt: "text, watermark, (deformed iris, deformed pupils, semi-realistic, cgi, 3d, render, sketch, cartoon, drawing, anime), text, cropped, out of frame, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers, long neck"

While we’ve made headway with faces and realism, rendering hands correctly remains an issue…
Now, let’s shift gears and attempt to generate some text.
"A road sign pointing to Hawaii"
Three generations later, and voilà! Our desired text appears. Admittedly, the overall image quality may not be award-winning, but the key element — the text — is there, and that’s a win!
What’s Next?
The Stability AI team is actively developing the next generation of task-specific structure, style, and composition controls, with T2I / ControlNet specialized for SDXL. These exciting features promise even greater flexibility and control over the image generation process.
Where is SDXL 1.0 Available to Download?
You can download the SDXL models (Base and Refiner) from the StabilityAI official HuggingFace page.
Hope this was useful! Thank you for reading.
References:
[1] StabilityAI, Announcing SDXL 1.0, 2023
[2] StabilityAI, SD-XL 1.0-base Model Card, 2023, Hugging Face
[3] StabilityAI, SD-XL 1.0-refiner Model Card, 2023, Hugging Face
[4] D. Podell et al., SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis, 2023, Computer Vision and Pattern Recognition