

![[EZ AI]The underlying logic of GPT](https://image.civitai.com/xG1nkqKTMzGDvpLrqFT7WA/fabd8b78-c109-4d9f-836d-33c8cce74681/width=1320/fabd8b78-c109-4d9f-836d-33c8cce74681.jpeg)
“Something unknown is doing we don't know what.”
——Sir Arthur Eddington, comment on the Uncertainty Principle in quantum physics, 1927
“Why not rather try to produce one which simulates the child's?”
——Alan Turing, 1950
“It's important though to note that we know of no problem so far that a human mind can solve that couldn't be solved by a Turing Machine.”
——Kurt Gödel, 1931
Chapter.0 Start
The legendary sweeping monk, extremely rare in reality.
Some monks are just pretending to sweep; and most of the "sweeping monks" are not really master.
The movie "Good Will Hunting" tells the story of such a young genius, the janitor "Will Hunting" who solved the problem posed by the professor of the Massachusetts Institute of Technology's mathematics department while mopping the floor at the university, and his talent shocked this Fields Medal winner (the "Nobel Prize" in mathematics).
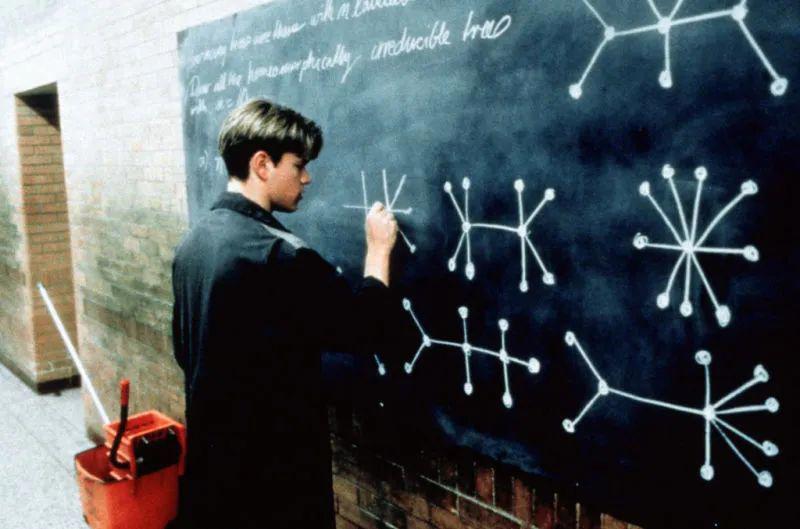
Who is the prototype of the poor and unruly genius protagonist in the movie?
People may think of Walter Pitts, a logician who worked in computational neuroscience.
He proposed a groundbreaking theoretical representation of neural activity and generative processes, which influenced different fields such as cognitive science and psychology, philosophy, neuroscience, computer science, artificial neural networks and artificial intelligence, as well as the so-called generative science.
In a sense, it is the source of ChatGPT. In the 1930s, Pitts was sweeping floors at the University of Chicago, about 15 years old. This was an important turning point in his life, and almost determined the starting point of today's hottest neural network.
Pitts came from a poor family, and like the protagonist of "Good Will Hunting", he taught himself by borrowing books from public libraries while fighting. He liked logic and mathematics, and also mastered many languages such as Greek and Latin.
He lived in a slum area. At the age of 12, he spent three days reading Russell's "Principles of Mathematics" and wrote to the author pointing out errors.
Russell, who cherished talent like life, immediately invited Pitts to Cambridge University as a graduate student, but failed.
When he graduated from junior high school at the age of 15, his father forced him to drop out of school and work to support his family. Pitts ran away from home.
With nowhere to go, Pitts learned that Russell was going to teach at the University of Chicago and went there alone. He did meet the great master.
Russell's love for talent remained unchanged. He recommended him to Professor Carnap, a philosopher.
Hearing that Pitts was a young genius, Carnap showed him his book "Logical Syntax of Language". Pitts quickly finished reading it and returned the original book with notes to the author.
The famous analytical philosopher was shocked and arranged for Pitts, who had graduated from junior high school, to work as a cleaner at the University of Chicago.
The scene that moved the audience in the movie appeared in the real world. The job of sweeping not only allowed Pitts not to wander on the street, but also allowed him to freely explore the truth with masters.
The biggest footnote buried by fate at this moment was to let this poor and lucky child meet the most important person in his life for him two years later.
In 1940, 17-year-old Pitts met Professor McCulloch, 42 years old. From then on, they changed the world together.
Unlike Pitts' chaotic life, McCulloch graduated from Harvard, Yale and Columbia University successively. He obtained a dazzling string of bachelor's, master's and doctoral degrees.
McCulloch was not like the lonely psychology professor in "Good Will Hunting". He was born superior, had a happy family, had a thriving career, lived a mainstream and orthodox life, and had received widespread praise academically.
However, two people who seemed to come from different times and spaces came together at the deepest level of thought.
In 1943, McCulloch and Pitts published a paper titled "A Logical Calculus of the Ideas Immanent in Nervous Activity", which proposed for the first time the M-P model of neurons.
The model draws on the known principles of biological processes of nerve cells, is the first mathematical model of neurons, and is the first attempt in human history to describe the working principle of the brain.
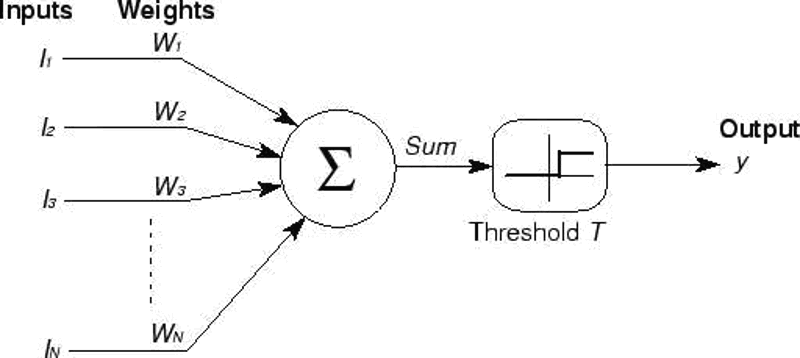
The M-P neuron is an idealized and simple model based on the basic characteristics of biological neurons. Its working principle is as follows:
The neuron receives a set of binary inputs, each input corresponding to a weight;
When the sum of the weighted inputs exceeds a certain threshold, the neuron is activated and outputs 1, otherwise it outputs 0.
This mechanism simulates well the "all-or-none" response mode of biological neurons.
The influence of the M-P model is that it is a good start, paving the way for later complex neural network models.
However, the M-P model also has great limitations, such as it cannot learn and adjust its own weights, and can only handle binary inputs and outputs.
This model is the cornerstone of artificial neural networks and deep learning.
Modern neural network models are much more complex than the McCulloch-Pitts model, but their basic principles - calculating output based on input, and possibly adjusting themselves to optimize this process - are still the same.
McCulloch and Pitts' paper is not only an important milestone in the history of artificial intelligence, laying the foundation for understanding the working mechanism of the brain and developing artificial intelligence, but also inspired people:
The biological brain "may" complete information processing through physical and fully mechanized logical operations, without too much Freudian-style mystical explanation.
McCulloch later proudly declared in a philosophical article:
"We know how we know, this is the first time in the history of science."
Chapter.1
In the same year that McCulloch and Pitts published their milestone paper, Alan Turing was cracking the German Enigma code machine at Bletchley Park.
He and his team used their intelligence to save hundreds of thousands of lives and played a key role in the Allied victory in World War II.
Their intersection also had something to do with Russell.
In the early 20th century, mathematicians and logicians were trying to find a system that could reduce all mathematical truths to a set of simple axioms and logical rules.
This was the famous Hilbert program, proposed by the German mathematician David Hilbert.
Russell and his collaborator Whitehead tried to do this in their book "Principia Mathematica", where they tried to establish the foundations of mathematics on formal logic.
However, the Hilbert program was frustrated in 1931, because Gödel proved his incompleteness theorem. This theorem states that:
Any sufficiently powerful formal system contains some propositions that cannot be proved or refuted within the system.

(From left to right:Russell、Hilbert、Brouwer、Gödel)
In 1936, Turing studied Hilbert's "computability" and "decidability" problems in a paper.
To solve this problem, Turing first defined the concept of "computation", and created the Turing machine, which is a theoretical computing device.
Then, he constructed a problem that the Turing machine could not solve (the halting problem) to prove that the decidability problem was actually unsolvable.
This meant that there was no universal algorithm that could give an answer to any possible problem.
An unexpected gain was that Turing created a new field of research - computability theory (or computability).
The Turing machine gave a way to formalize the concept of "computation" or "algorithm", which was not only useful in his original problem, but also had a profound impact on the development of computer science.
In fact, all modern electronic computers are based on the Turing machine model, which makes the Turing machine the core of computability theory.
There is no evidence that McCulloch and Pitts read Turing's paper. Their common interest was to apply Leibniz's mechanical brain idea to build a model of brain thinking.
In the "Principles of Mathematics", only three basic logical operations, namely and, or, and not, were used to connect simple propositions into more and more complex relational networks, and then to describe the entire mathematical system clearly. (Although not complete)
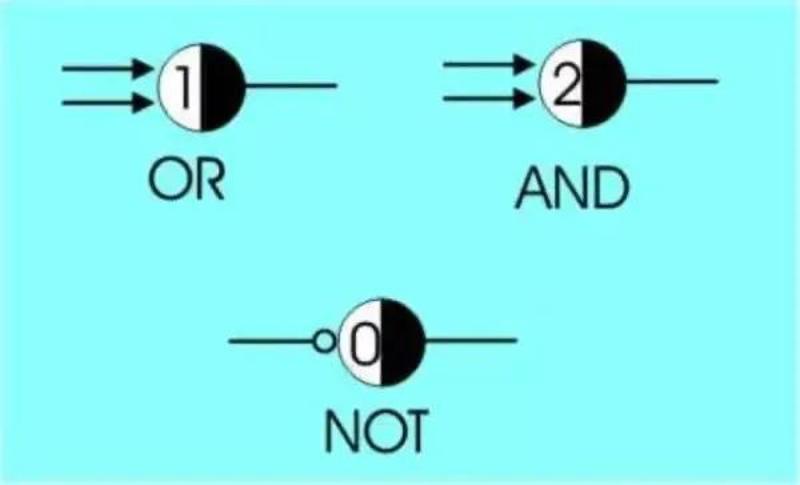
McCulloch envisioned: Is human thinking also achieved by neurons performing these most basic logical operations?
Pitts, who was gifted in mathematics and logic, helped McCulloch realize this great idea.

(Pitts and McCulloch)
McCulloch and Pitts proposed the neuron model in 1943, which forms the basis of what we call artificial neural networks today.
Their model depicts a simplified neuron, which is activated and sends signals to other neurons when its input exceeds a certain threshold.
A key idea of this model is that even though each individual neuron is simple, by connecting them together, a network that can handle very complex problems can be formed.
Although a single McCulloch-Pitts neuron can only perform simple logical tasks, when these neurons are composed into a complex network, the neural network can perform complex computations, thus exhibiting Turing completeness.
In fact, neural networks are one of the important methods for achieving artificial intelligence (AI).
By designing different network structures and using a large amount of data to train the network, artificial neural networks can learn the ability to complete various tasks, including image recognition, speech recognition, natural language processing, etc.
Chapter.2
AI's neural network is a game of imitating human brain and human collective intelligence based on social network.
Human brain neuron structure and working principle are as follows:
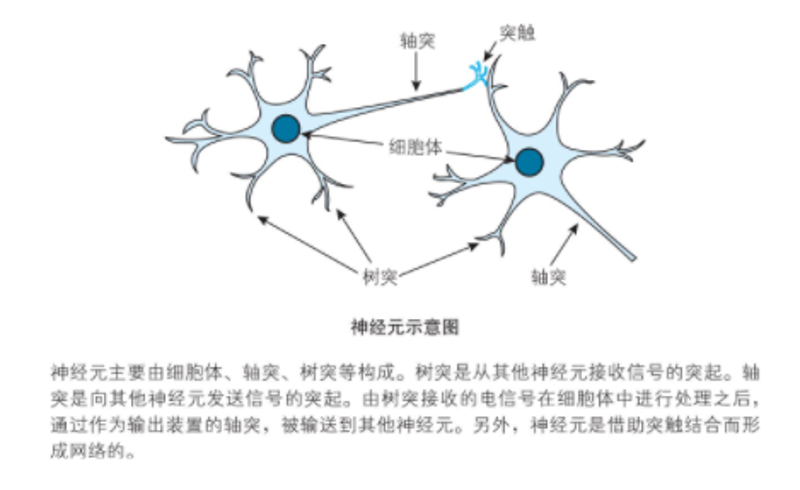
The picture is from the book "The Mathematics of Deep Learning".
The above principle, using computation to simulate and explain, is: neurons fire when the sum of signals exceeds the threshold, and do not fire when the threshold is not exceeded.
In the 1950s and 1960s, Oliver Selfridge created a concept called "pandemonium". This is a pattern recognition device, where "demons" that perform feature detection compete with each other to claim the right to represent objects in the image.
"Pandemonium" is a vivid metaphor for deep learning, as shown in the following figure:
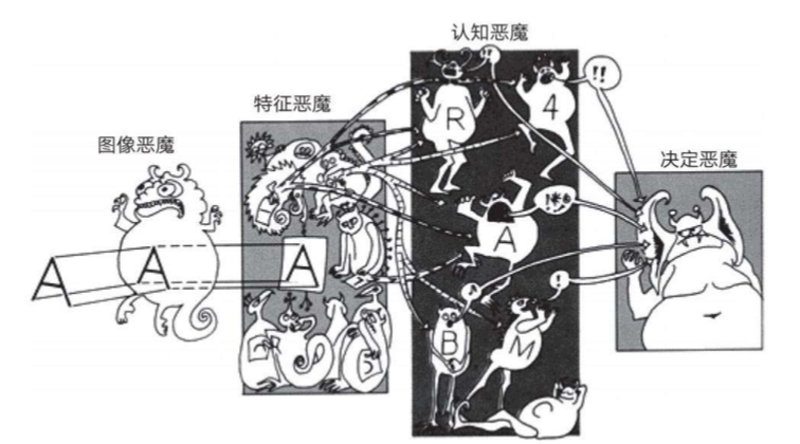
The picture is from the book "Deep Learning".
The above figure is a metaphor for the current multi-level deep learning network:
1. From left to right, it is from low to high level of demons.
2. If each level of demons matches the input from the previous level, it will be excited (fire).
3. Higher-level demons are responsible for extracting more complex features and abstract concepts from the input of the next level, and then make decisions. Then pass it to their superiors.
4. Finally, the big demon makes the final decision.
In the book "The Mathematics of Deep Learning", according to the above metaphor, a vivid example is used to explain the working principle of neural network.
Question: Build a neural network to recognize handwritten digits 0 and 1 read by 4×3 pixel images.
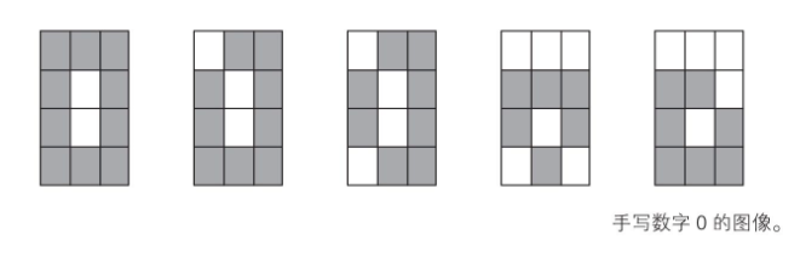
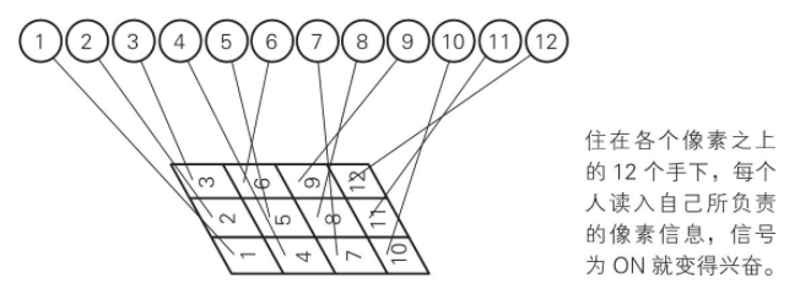
Step one: input layer
12 squares, equivalent to each square living a person, numbered 1-12 respectively. As shown in the figure below.
Step two: hidden layer
This layer is responsible for feature extraction. Assume that there are three main features, divided into patterns A, B, and C. As shown in the figure below.
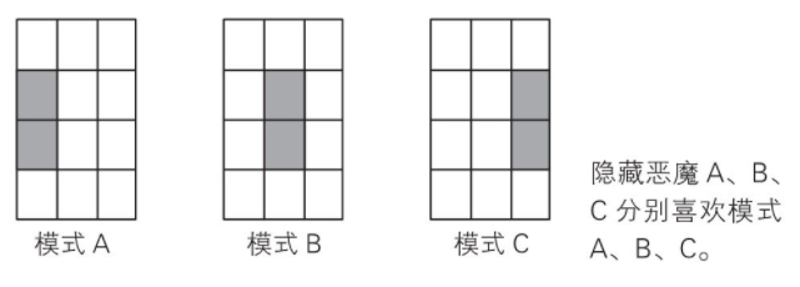
Different patterns correspond to different combinations of digital squares. As shown in the figure below. Pattern A corresponds to numbers 4 and 7, B corresponds to 5 and 8, and C corresponds to 6 and 9.
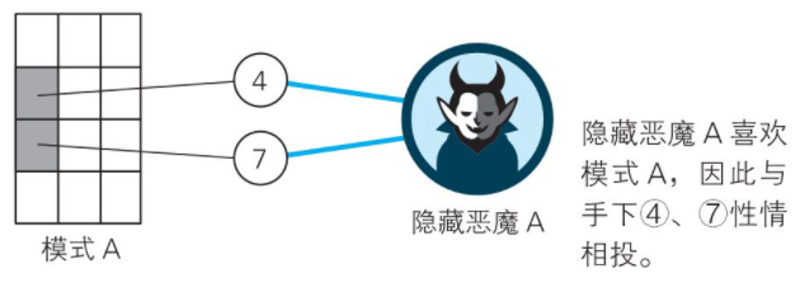
Step three: output layer
This layer obtains information from the hidden layer.
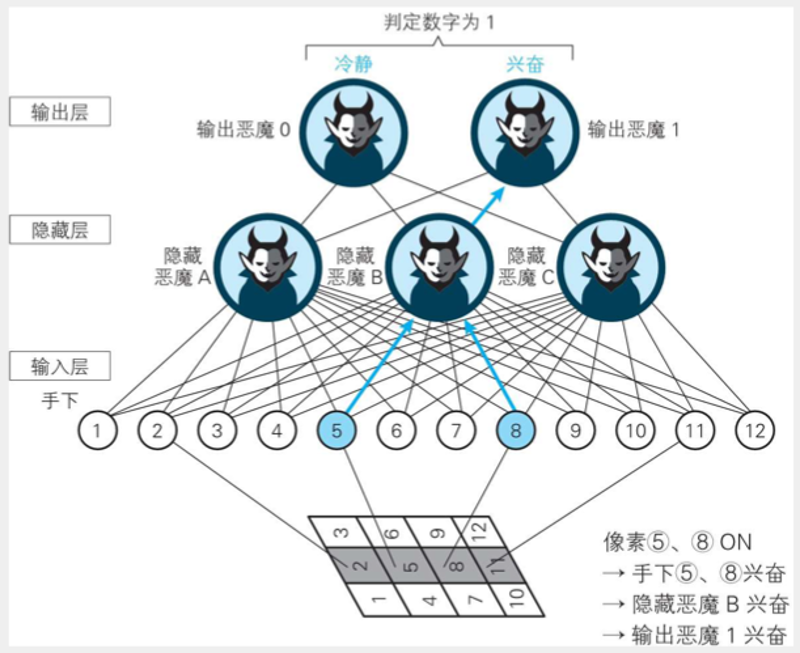
As shown in the figure above, at the bottom is the image that AI wants to recognize.
First, input layer 2, 5, 8, 11 fire;
Then, hidden layer 5 and 8 corresponding features are extracted, "pattern B" fire;
Finally, output layer 1 is fired by corresponding "pattern B".
Therefore, "big demon" recognizes image as number 1.
In the above example, AI can accurately identify 0 and 1, but it does not understand 0 and 1, it only has pixels in its eyes.
To say so seems too anthropomorphic. How do humans understand 0 and 1?
Aren't humans also inputting through their eyes, extracting features through their brain neural network (a more complex, powerful and energy-saving hidden layer) that is still the biggest mystery in the universe, and then self-explaining through some part of their brain?
Hinton mentioned in an interview that there are two schools of thought in cognitive science about "how the brain processes visual images":
One school believes that when the brain processes visual images, what you have is a set of moving pixels. As shown in the above demonstration;
The other school tends to favor old-fashioned artificial intelligence, which believes that it is hierarchical and structural descriptions that are processed in the brain. The brain processes symbolic structures.
Hinton himself thinks that both schools are wrong. "Actually what's inside your brain are big vectors of neural activity." And symbols only exist in the external world.
Anyway, neural network models are useful and very useful.
Hinton, who was unwilling to share professional topics with laymen, vividly introduced "neural network" with this paragraph:
First there are relatively simple processing elements that are loose models of neurons. Then neurons connect together with each connection having its own weight which can change through learning.
What neurons do is multiply together activities on connections with weights on those connections then add them up then decide whether or not to send out a result. If they get a big enough number they send out a result. If they get a negative number they don't send out anything.
What you do is put together lots of activities with lots of weights and then figure out how to change those weights so it works. The key problem is how you change those weights.
Chapter.3
ChatGPT's underlying logic is extremely complex, but if it is to be simplified into three core elements, ChatGPT-4 thinks they might be:
1. Deep learning: The core of ChatGPT is a deep learning model based on Transformer.
Transformer model uses self-attention mechanism to capture complex patterns in the input text. During the training process, the model learns these patterns through optimization algorithms such as backpropagation and gradient descent, so that it can generate natural, coherent, and consistent text with the input.
2. Big data: ChatGPT learns language models by training on massive amounts of text data.
The data set contains various language patterns and contexts, enabling the model to generate appropriate text in various situations. Big data plays a decisive role here.
3. Powerful computing power: In order to process these large amounts of data and complex deep learning models, ChatGPT requires powerful computing power.
This includes powerful hardware (such as high-performance GPUs), excellent computing frameworks (such as TensorFlow and PyTorch), and efficient parallel and distributed computing technologies.
These three elements form the basis of ChatGPT, enabling it to learn and generate natural language.
However, this is only the surface logic. In fact, there are profound theoretical foundations behind each link, covering knowledge from multiple disciplines such as machine learning, natural language processing, computer science, mathematics, etc.
Deep learning is a powerful machine learning method, whose underlying logic is quite complex. However, if we try to simplify the core principles of deep learning into three elements, ChatGPT-4 thinks they can be described as follows:
1. Neural network architecture: The core of deep learning is deep neural network, which is a computational model that simulates the working principle of human brain.
Neural network consists of multiple interconnected layers, each layer consists of a large number of neurons (or nodes). Each neuron receives input from the previous layer of neurons, performs some calculation, and then passes the result to the next layer of neurons.
2. Weight optimization and learning: Each connection in the neural network has a weight that represents the importance of this connection.
The goal of deep learning is to adjust these weights by training data, so that the output of the network is as close as possible to the real target value. This process is usually achieved by optimization algorithms (such as gradient descent), which adjust the weights according to the gap (loss) between the network output and the target value.
3. Non-linear activation function: Another key element of deep learning is non-linear activation function, such as ReLU (Rectified Linear Unit) or Sigmoid.
These functions are used to increase the expressive power of neural networks, enabling them to learn and represent non-linear complex patterns.
These three elements together constitute the underlying logic of deep learning.
It should be noted that this is only a rough overview, and in fact deep learning involves much more complex theories and techniques.
For example, there are regularization, convolutional neural networks, recurrent neural networks, self-attention mechanism, batch normalization, optimization algorithms, loss function design and many other methods and techniques that are indispensable parts of deep learning.
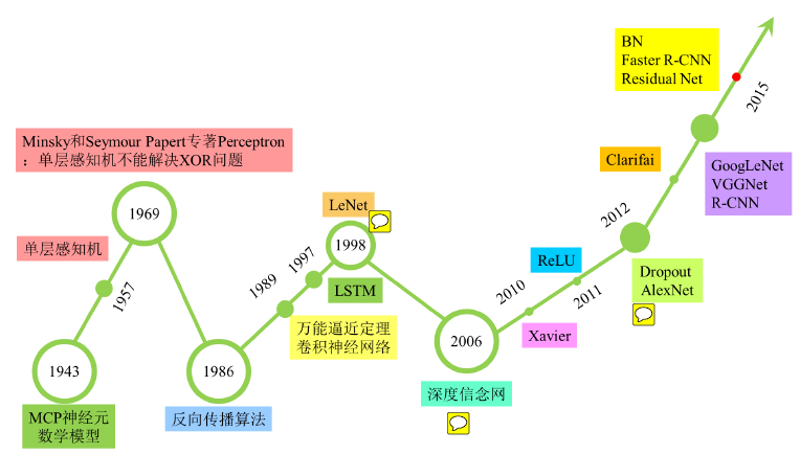
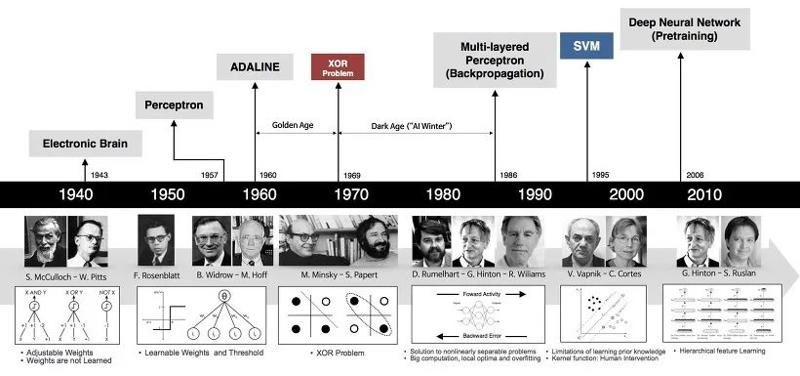
1. McCulloch-Pitts neuron model (1943): Warren McCulloch and Walter Pitts first proposed the McCulloch-Pitts (M-P) model of neurons, drawing on the known biological processes of nerve cells.
2. Perceptron (1957): The perceptron model proposed by Frank Rosenblatt was based on the working principle of biological neurons and was the main form of early neural networks.
3. Minsky and Papert (1969): Marvin Minsky and Seymour Papert pointed out the limitations of perceptrons, namely that they could not solve non-linearly separable problems (such as XOR problem). This partly led to the first artificial intelligence winter.
4. Multilayer perceptron (1986): Under the research of Rumelhart, Hinton and Williams, multilayer perceptron (MLP) became the main form of neural networks. MLP introduced one or more hidden layers and used the backpropagation algorithm to train the network.
5. Convolutional neural network and LeNet-5 (1989/1998): Convolutional neural network (CNN) proposed by Yann LeCun and others is a type of neural network that specializes in processing grid-like data (such as images). LeCun and his team developed LeNet-5 in 1998, which was the first convolutional neural network to be successfully applied to a practical problem (digit recognition).
6. Long short-term memory network (1997): Long short-term memory network (LSTM) proposed by Hochreiter and Schmidhuber is a type of recurrent neural network that specializes in processing sequence data. LSTM introduces "gate" structure, which can learn long-term dependencies and avoid the gradient vanishing problem of traditional RNN when dealing with long sequence.
7. Deep learning and deep belief network (DBN, 2006): Hinton and others proposed deep belief network (DBN) and deep autoencoder (DAE), marking the arrival of the era of deep learning. Deep learning uses multi-layer neural networks, which can learn more complex patterns and representations.
8. ReLU activation function (2010): Nair and Hinton proposed rectified linear unit (ReLU) as an activation function for neurons, which greatly improved the training speed and performance of deep neural networks.
9. AlexNet (2012): AlexNet model by Krizhevsky, Sutskever and Hinton greatly surpassed other models based on traditional machine learning techniques, triggering a revolution of deep learning in computer vision field.
10. word2vec (2013): word2vec by Mikolov and others is a method that uses neural networks to generate dense vector representations for words.
11. GoogLeNet and VGGNet (2014): GoogLeNet by Szegedy and others and VGGNet by Simonyan and Zisserman further improved the performance of convolutional neural networks on image classification, and promoted the design of convolutional neural networks to further develop towards depth.
12. ResNet (2015): ResNet by He and others solved the gradient vanishing problem of deep neural networks by introducing skip connections, enabling the depth of the network to reach an unprecedented level.
13. Self-attention and Transformer (2017): Transformer model proposed by Vaswani and others introduced self-attention mechanism, which allows neural networks to establish dependencies over a larger range, providing a new framework for processing sequence data.
It is obvious that I used ChatGPT-4 to complete this section.
The human brain can think about itself, although the mystery is hard to solve;
neural networks can also recall their own history, even though they cannot be moved by those who have contributed to this process.
Chapter.4
Chris McCormick thinks that neural networks are pure mathematics.
Technically speaking, "machine learning" models are largely based on statistics. They estimate the probabilities of all options, and even if the correct probabilities of all options are very low, they will still choose the path with the highest probability.
Neural networks are inspired by biology, especially the working principle of the human brain, but their design and operation basis is indeed mathematics, including linear algebra (for data and weight representation and operation), calculus (for optimization algorithms, such as gradient descent) and probability theory (for understanding and quantifying uncertainty).
Every part of a neural network can be described by mathematical expressions, and the training process is a process of learning model parameters by optimizing a mathematical objective function (loss function).
Jen-Hsun(Nvidia CEO) said:
"AI is both deep learning and an algorithm to solve problems that are difficult to specify. It is also a new way of developing software. Imagine that you have a universal function approximator of any dimension."
In Jen-Hsun's metaphor, "universal function approximator" is indeed an accurate and insightful description of deep neural networks. This metaphor highlights the core characteristics of deep neural networks:
They can learn and approximate any complex function mapping, as long as the network is deep enough and the parameters are enough.
This "function approximation" ability enables deep learning to cope with various tasks, from image classification and speech recognition to natural language understanding and generation, and even more complex tasks such as games and decision making.
As long as we have enough data to train these models, neural networks can learn the complex patterns behind these tasks. --Even if these patterns are just a black box for humans.
Especially in generative models (such as ChatGPT), this "function approximation" ability enables the model to generate creative outputs, such as writing articles, creating poems or music, etc.
These models learn the rules of language or music by learning a large amount of data, and then generate new creations that conform to these rules.
What exactly is ChatGPT doing? Why is it successful?
Wolfram explained it this way:
Surprisingly, when ChatGPT tries to write an article, it basically just asks "what is the next word based on the existing text?" over and over again, and adds one word each time. (More precisely, it is a token)
So, does it always choose the word with the highest probability?
Not so simple.
Wolfram tells us how ChatGPT "writes" an article based on probability:
At each step, ChatGPT generates a list of words with probabilities.
but if you always choose the highest "probability" of words, you will usually get a very "bland" article.
So magic comes in the form of a specific so-called "temperature" parameter, which controls how often lower-ranked words will be used.
For article generation, we found that a "temperature" of 0.8 worked best.
Probability and randomness show their magic again.
Chapter.5
In Microsoft's report, researchers used GPT-4 to simulate a dialogue:
Socrates: My friend, I am uneasy about the recent rise of these so-called autoregressive language models.
Aristotle: What do you mean, Socrates?
Socrates: I mean, these models are used to generate text that looks like it was written by humans, but in fact it is produced by machines.
Aristotle: What is the problem with that?
Socrates: The problem is, these models are used to deceive people, manipulate them, control them.
Aristotle: But surely there are some positive applications of these models?
Socrates: There may be, but I am still uneasy about the possibility of abuse. After all, a model that can generate text that is indistinguishable from human-written text can be used to spread fake news, impersonate others, and create propaganda.
Aristotle: But isn't this just a matter of how these models are used, rather than a problem with the models themselves?
Socrates: I disagree. I think these models are problematic in themselves. They are a form of disguise, a way of creating illusions, a part of human thought and interaction. Therefore, they can be used to deceive and manipulate in subtle ways.
Aristotle: But isn't this exactly the reason why you oppose rhetoric and speech?
Socrates: Yes, I also hold this view. I believe that any art or form of communication that aims to deceive or manipulate is inherently dangerous.
Aristotle: I see. Thank you for sharing your thoughts, Socrates.
Jobs once imagined such a dialogue. He predicted that one day it would be possible to use computers to capture Aristotle's underlying worldview, so that people could talk to him personally.
Socrates, who opposed rhetoric and speech, believed that sensation was unreliable, emotional cognition was uncertain, and only reason could know things themselves.
And in Aristotle's method, he determined Rhetoric as one of the three key elements of philosophy. The other two are Logic and Dialectics.
Aristotle believed that logic focuses on achieving scientific certainty through reasoning, while dialectics and rhetoric focus on probability. The latter applies to human affairs.
The above two paragraphs are taken from the online encyclopedia. Although I cannot confirm their original text and source (especially the part about probability), they are admirable.
However, in the following years, Aristotle's logic and deterministic knowledge system had a greater impact on humans.
People believed in causality and determinism. Under Newton's promotion, the world seemed to be a machine composed of countless precise gears. Under God's first push, it continued to operate in an orderly manner.
And another clue was also brewing. Hume's skepticism and empiricism completely changed people's ideological world. He believed that sensory perception was the only object of cognition. People could not go beyond perception to solve the problem of the source of perception.
In Hume's view, objective causality does not exist.
Then Kant tried to reconcile rationalism and empiricism. He denied objective causality, but advocated using innate rational categories to organize chaotic experience.
Mach then created empirical criticism. He emphasized direct discussion of observational data. Scientific laws are only regarded as means to describe data in the most economical way.
The book "Scientific Inference" believes that he opened up the main progress of modern methodology.
Einstein, who was deeply influenced by Mach, could not accept this destructive scientific belief and contempt for laws, formulas, and theorems. He later parted ways with him.
Einstein constructed logical principles with exploratory deduction methods. He believed in the universe and did not believe in supernatural powers.
In a sense, Einstein was the last Newton (except for replacing God with Spinoza's "God"), and he was the defender of scientific causality determinism.
In 1967, Popper made a conclusion for this intertwined and long philosophical journey. He proposed the view of the three worlds and Borkin drew it as follows:
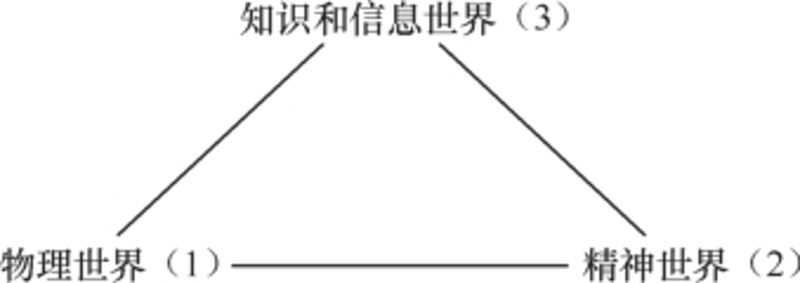
This seems to be a modern version of Plato's cave theory.
Look how ignorant and divided people are!
Based on this structure, Popper proposed: We cannot confirm this world or confirm laws and theorems. We can only falsify them.
Chapter.6
Maybe you still remember the honest artificial intelligence of the last generation--Deep Blue. A huge machine with endless hand-made code, several professional chess players involved in it, and violent algorithms defeated Kasparov but passed by like a meteor.
The Massachusetts Institute of Technology Technology Review described Deep Blue as a dinosaur, while this generation of neural networks (especially deep learning) are small mammals that survive and change the earth.
In the 1950s, Shannon optimistically predicted that AI would soon appear. This was not the case. The main reason for failure was:
The creators of artificial intelligence tried to use pure logic to deal with the chaos in daily life. They patiently made a rule for every decision that artificial intelligence needed to make. However, because the real world is too vague and subtle, it cannot be managed in a rigid way.
We cannot build intelligent systems like cars according to Newton's principles, with clockwork thinking and expert systems. That kind of AI is not only narrow, but also fragile.
ChatGPT is the "victorious product" of empirical evolutionism.
Empiricism is also called "empiricism". As a theory of knowledge, it is opposed to "rationalism". Empiricism believes that sensory experience is the source of knowledge, and all knowledge is obtained through experience and verified in experience.
This is exactly ChatGPT's thinking and learning path.
And virtual evolution exponentially accelerates the learning speed based on experience. Popper believes that scientific development itself is a kind of evolution.
ChatGPT not only simulates evolution from the perspective of time, but also expands the breadth of possibilities from the perspective of space, so that people can't help but discuss Emergence with surprise and joy.
So how does artificial intelligence think? How does it make decisions?
Unlike the deductive reasoning of gears, we need to use probability to establish a connection between evidence and conclusion.
AI's task is to make decisions, combining beliefs and desires under uncertainty, and choosing actions.
"Artificial Intelligence: A Modern Approach" describes it as follows:
Due to partial observability, non-determinism and adversaries, agents in the real world need to deal with uncertainty. Agents may never be able to know exactly what state they are in now, or where they will end up after a series of actions.
In addition, the correct actions of the agents - Rational Decisions - depend not only on the relative importance of various goals, but also on their likelihood and degree of achievement.
To perform uncertain reasoning, we need to introduce degrees of belief, such as an 80% probability of having a cavity for a toothache patient.
Probability theory provides a way to generalize the uncertainty caused by our inertia and ignorance.
In addition to probability, agents also need a concept when making decisions: utility theory.
For example, if you leave for the airport 90 minutes in advance, the probability of catching the flight is 95%; if you leave 120 minutes in advance, the probability increases to 97%.
So, should you leave as early as possible and pursue the maximum probability of catching the flight? In this way, you may have to stay at the airport a day or even earlier.
Most of the time this is not necessary, but if you have a meeting that you can't miss, or you have to catch an international flight, staying at the airport a day in advance may be the best decision. Marriott Hotel was the first to rise by insight into this need of business people.
From this, we derive the general theory of decision theory:
Decision theory = Probability theory + Utility theory
The above modern methods are inseparable from two ancient enemies who have never met.
Chapter.7
Among the many opponents of Hume, Bayes may be the most important one.
When Hume severed the inevitable connection between cause and effect, the most angry was the church, because God has always been regarded as the first cause of causality.
One often has to reach a certain age to understand Hume's philosophy. Especially for those of us who have been trained in certainty since childhood.
The basic form of logical reasoning is: if A, then B.
Hume said that such reasoning is either an illusion, nonsense, or circular reasoning.
It is said that the pious and mathematically proficient priest Bayes studied the Bayes formula in order to refute Hume.
A magical ending appeared:
The Bayes formula became a realistic antidote to Hume's philosophy, connecting the causality that was cut off by his sword with a bridge of inverse probability.
Probability modifies the form of logical reasoning to: if A, then there is an x% chance of causing B.
And the Bayes formula completes a small (but has an immeasurable huge impact) reversal of cause and effect:
If B is observed, then there is an x% chance that it is caused by A.
In this way, the world that was doubted by Hume continued to build a more complex and complicated network of causality linked by probability.
If Bayes' motive for counterattacking Hume was true, it would add a powerful argument to "cherish your opponent".
Let's use a simple Bayesian calculation to see how intelligent agents learn from experience.
Question: There are two dice in a black box, one is a normal dice, the probability of throwing a 6 is 1/6; one is a cheating dice, the probability of throwing a 6 is 1/2.
At this time, you pick out a dice from it and throw it once, getting a 6.
Question: How likely are you to get a 6 again when you throw this unknown dice again?
The first step in the calculation is to calculate how likely this dice is a normal dice and a cheating dice respectively.
Please allow me to skip the Bayes formula and quickly calculate as follows.
The probability of being a normal dice is: 1/6 ÷ (1/6 + 1/2) = 1/4
The probability of being a cheating dice is: 1/2 ÷ (1/6 + 1/2) = 3/4
The second step in the calculation is to update the information of this dice. The original probability was 1/2 each, but now they are 1/4 and 3/4 respectively.
Then, throwing it again, the probability of getting a 6 is: 1/4×1/6+3/4×1/2=5/12.It is not easy to understand this simple calculation from an essential level:
Both throwing dice are independent events, why is the probability of throwing a 6 for the first time different from the second time?
The explanation of Bayesian probability is that the result of throwing a 6 for the first time, as information, updates our judgment on the probability of throwing a 6 for the second time.
People who are puzzled will continue to ask: The dice has no memory, why does the first result "change" the second result?
The answer is: It does not change the result, it just changes the "belief".
Even if we throw two dice, we still don't know whether this dice is normal or cheating, but we can move forward with this uncertainty. For this we need to "guess" the probability that this dice is normal or cheating. This probability is belief.
According to the change of information, quickly update, reflecting a kind of Darwinian evolution.
From this perspective, AI reasoning may be weak and vague at first, but it has proactive adaptability, learns from experience continuously, and evolves rapidly.
Take this question as an example: The second time you throw the dice, you learn from the result of the first dice, making your prediction more accurate.
This process can also be repeated continuously, like an engine, thus producing a leverage effect of decision-making and intelligence.
As mentioned earlier, Aristotle once thought that rhetoric and probability and other uncertain elements should be applied to human society. And in natural science and mathematics fields, it is the territory of logical reasoning (especially mathematical logic).
And now, the certain world has become an uncertain world, and absolute truth has been replaced by probable truth.
Therefore, probability not only becomes a ladder for "truth", but even becomes truth itself.
"Artificial Intelligence: A Modern Approach" wrote that this is how the world works. Sometimes actual demonstrations are more convincing than proofs. The success of inference systems based on probability theory is easier to change people's views than philosophical arguments.
Just like two people arguing about different opinions, one way is to reason and logic; another way is:
Let's make a bet first, and then try to run it.
Reid Hoffman, an early investor in OpenAI, discovered the following three key principles when trying to apply GPT-4 to his work.
Principle 1: Treat GPT-4 as an undergraduate-level research assistant, not an omniscient prophet.
Principle 2: Think of yourself as a director, not a carpenter.
Principle 3: Be brave and try!
What interesting suggestions, we see the wisdom of "The Gardener and the Carpenter" and "Bottom-up" from them:
In most work, we are used to planning ahead and trying to avoid mistakes. This is because implementing the plan consumes a lot of time and other resources. The saying "think twice before you act" refers to this situation.
But what if implementing the plan is more time-saving and effortless than thinking about it?
Hoffman thinks this is the paradox of GPT-4 and large language models that puzzles people.
In that case, the correct way is:
1. In a shorter time than discussing and making a plan, GPT-4 can generate a complete response for you to review.
2. If you are not satisfied with the response, you can discard it and try to generate another one.
3. Or generate multiple versions at once and get more choices.
We have come to an era of "Three lines and then think" of "Reinforcement Learning".
Chapter.8
In the report "The Spark of Artificial General Intelligence: Early Experiments with GPT-4", Microsoft Labs stated:
"The most significant breakthrough in artificial intelligence research in the past few years has been the progress made by large language models (LLMs) in natural language processing.
These neural network models are based on the Transformer architecture and are trained on large-scale web text data sets. Their core is to use a self-supervised objective to predict the next word in a partial sentence."
ChatGPT is a master of "language games", using Neural Networks and Deep Learning.
This is different from traditional language and logical language.
Russell once tried to construct a logical language, hoping to deduce mathematics from a few logical axioms.
He proposed his own logical atomism, trying to eliminate the confusion of metaphysical language, and correspond logic language with our real world one by one.
Under the mutual influence of Russell, Wittgenstein thought that all philosophical problems are actually language problems, thus promoting the linguistic turn of philosophy.
One view of Western philosophy history is that ancient philosophy focused on ontology, modern philosophy focused on epistemology, and 20th century philosophy focused on linguistic issues.
So, as the "first person to systematically think about the world from language", how is Wittgenstein different from Russell?
Chen Jiaying(Chinese philosopher)'s argument is: Russell thinks about the nature of language from ontology, while Wittgenstein always conceives ontology from the nature of language.
Perhaps we can find some empirical clues of Wittgenstein's philosophy from a letter Russell wrote to his lover Ottoline Morrell:
"Our German engineer, I think he is a fool. He thinks that nothing empirical is knowable - I asked him to admit that there was no rhinoceros in the room, but he refused."
Like every genius, Wittgenstein was outstanding, but also puzzled.
Speaking of ChatGPT, does it understand language? As the book "Genius and Algorithm" asks:
Can machines generate meaningful sentences, even beautiful sentences, without understanding language or touching the surrounding physical world?
Old-school AI tried to use Russell's method. These models think that:
"Rationality and intelligence are deep, multi-step reasoning, directed by a serial process, consisting of one or a few threads, using little information, expressed by a few strongly related variables."
In contrast, "modern machine learning models consist of shallow (few-step) reasoning, using large-scale parallel processing of large amounts of information, and involving many weakly related variables."
An interesting example to describe the contrast between the two is Turing in the movie "The Imitation Game", who fired his own code-breaking team's linguist.
"Artificial Intelligence: A Modern Approach" believes that purely data-driven models are easier to develop and maintain than hand-built methods based on "grammar, syntactic analysis and semantic interpretation", and score higher in standard benchmark tests.
The authors of the book also mentioned:
It may be that Transformer and its related models have learned latent representations that capture the same basic ideas as grammatical and semantic information, or it may be that something completely different happened in these large-scale models, but we don't know at all.
A not-so-accurate analogy is: AI learns language like a child. This is exactly what Turing envisioned back then:
Have a child-like brain and then learn. Instead of designing an adult brain from the beginning.
Children don't understand grammar construction, nor do they have mature logic, nor do they have as much deliberate practice as adults. But think about it, how bad is the efficiency of adults learning languages compared to children?
I can't help but think of a mockery of education:
Children who are born language learning geniuses have to learn languages under the guidance of adults who can't learn a language well in their lifetime.
Let's see how AI learns like a child, like a genius.
Chapter.9
The neural network and deep learning of AI have experienced a not-so-short dark period.
For nearly 30 years since the 1980s, only a very small number of related researchers devoted themselves to it, suffering from doubts and almost unable to obtain research funding.
Perhaps for this reason, the three giants of deep learning, Hinton, Bengio, and LeCun, seem to have something to do with Canada. They retreated there to study, teach, and read books. This is very in line with the temperament of that "silly country".
A "heartbreaking" detail is that in 2012, Hinton took his students to win the championship in the ImageNet image recognition competition, and commercial companies flocked to it.
Professor Hinton's commercial offer was only a mere one million US dollars.
(Google later "won the bid" for 44 million US dollars.)
The "old-fashioned" AI uses clear step-by-step instructions to guide the computer, while deep learning uses learning algorithms to extract the association patterns between input data and expected output from data, as demonstrated in the previous section.
As everyone knows, after a long night, with the exponential growth of human computer computing power and data, deep learning has soared to the sky, from Alpha Dog's battle to seal the gods, to ChatGPT conquering the world.
Why is it Open AI instead of DeepMInd?I am a little curious about this.
Ilya Sutskever, co-founder and chief scientist of OpenAI, was a student brought by Hinton at the University of Toronto.
He seems to have continued Hinton's belief in deep learning and is brave enough to bet all his money.
Hinton believes that "Deep Learning is enough to replicate all human intelligence" and will be omnipotent as long as there are more conceptual breakthroughs. For example, "transformers" use embedding to represent word meanings for conceptual breakthroughs.
In addition, the scale must be greatly increased, including the scale of neural networks and data.For example, the human brain has about 1 quadrillion parameters, which is a truly huge model. And GPT-3 has 175 billion parameters, about a thousand times smaller than the brain.
Neural networks mimic the human advantage: processing a small amount of data with a large number of parameters. But humans do better in this regard, and save a lot of energy.
One step ahead of DeepMInd, its development direction and speed, in addition to being caught in the dilemma of "business vs. research" with Google, is inevitably influenced by Hassabis's AI philosophy.
Hassabis thinks that whether it is ChatGPT or his own Gopher, although they can help you write, paint, and "have some impressive imitations", AI "still can't really understand what it is saying".
So he said: "(These) are not really (intelligent) in the true sense."
Hassabis's teacher, Professor Poggio of MIT, pointed out more sharply: deep learning is a bit like the "alchemy" of this era, but it needs to be transformed from "alchemy" to real chemistry.
Le Cun opposes the term alchemy, but he also thinks that we should explore the nature of intelligence and learning. Artificial neurons are directly inspired by brain neurons and cannot simply copy nature.
His point is that what engineering has achieved can only go further by opening the black box through science.
"I think we have to explore the basic principles of intelligence and learning, regardless of whether these principles exist in biological or electronic forms. Just as aerodynamics explains the flight principles of airplanes, birds, bats and insects, thermodynamics explains the energy conversion in heat engines and biochemical processes, intelligence theory must also take into account various forms of intelligence."
A few years ago, Hassabis at his peak expressed that relying solely on neural networks and reinforcement learning would not make artificial intelligence go further.
Similar reflections also occurred to Judea Pearl, the father of Bayesian networks.
He said that machine learning is nothing more than fitting data and probability distribution curves. The inherent causal relationship between variables is not only ignored, but deliberately ignored and simplified.
Simply put, it is: Pay attention to correlation, Ignore causality.
In Pearl's view, if we want to really solve scientific problems, or even develop machines with real intelligence, causality is a hurdle that must be crossed.
Many scientists have similar views and think that artificial intelligence should be given common sense, causal reasoning ability, and the ability to understand world facts. Therefore, the solution may be a "Hybrid Mode"-using neural networks combined with old-fashioned hand-coded logic.
Sutton despises this idea. On the one hand, he firmly believes that neural networks can have reasoning abilities, after all, the brain is a similar neural network. On the other hand, he thinks that adding hand-coded logic is stupid:
It will encounter all the problems of expert systems, that is, you can never predict all the common sense you want to give to the machine.
Does AI really need those human concepts? AlphaGo has already proven that chess theory and patterns are just redundant intermediate explanations.
Regarding whether AI really "understands", really "knows", really has "judgment", Sutton uses "insects recognize flowers" as an example:
"Insects can see ultraviolet rays, but humans can't, so two flowers that look exactly the same to humans may look completely different in insect eyes. Can we say that insects are wrong? Insects recognize that these are two different flowers by different ultraviolet signals. Obviously insects are not wrong, it's just that humans can't see ultraviolet rays, so they don't know there is a difference."
Do we say AI "doesn't understand" something because we are too human-centered?
If we think AI has no explainability and is not intelligent enough, could it be that even if AI explains it, we don't understand? Just like "humans can only rely on machine detection to see that the color signals of two flowers belong to different regions on the electromagnetic spectrum before they can be sure that the two flowers are indeed different."
Since he was a teenager, Sutton believed in "imitating brain neural networks", as if he had some kind of religious firmness.
So at a certain intersection, Hassabis hesitated slightly, while Ilya Sutskever and Sutton went all the way forward and gambled to the end.
Sutton's life philosophy is "Differentiation based on faith", and he indeed practiced it.
Nowadays, although Hassabis thinks ChatGPT is just more computing power and data brute force, he also has to admit that this is currently the most effective way to get the best results.
Chapter.10
The divergence of AI routes is nothing more than a continuation of some kind of scientific undercurrent for more than a hundred years.
For a long time, in the snow-covered Toronto, Sutton was almost the only night watchman of deep learning.
He studied physiology and physics at Cambridge University for his undergraduate degree, then switched to philosophy, and got a bachelor's degree in psychology. He later read a PhD in artificial intelligence.
Inspired by statistical mechanics, Sutton and others proposed the neural network structure Boltzmann machine in 1986, which introduced the Boltzmann machine learning algorithm to networks with hidden units.
As shown in the figure below, all the connections between the nodes are bidirectional. Therefore, the Boltzmann machine has a negative feedback mechanism, and the value output by the node to the adjacent node will feedback to the node itself.
The Boltzmann machine introduces statistical probability in the change of neuron state, and the equilibrium state of the network follows the Boltzmann distribution. The network operation mechanism is based on simulated annealing algorithm.
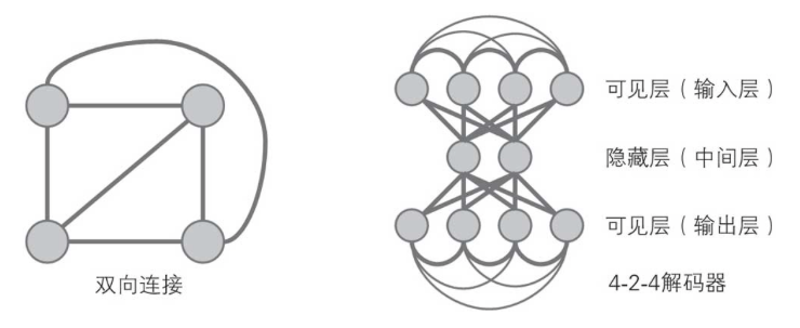
From Shannon to Sutton, they all got great inspiration from Boltzmann.
Introducing "probability" into physics seems very strange.
Humans did not know until after the 19th century that "heat" is the manifestation of the irregular movement of a large number of molecules inside an object. So why does heat always transfer from a hot object to a cold object?
Boltzmann said that atoms (molecules) are completely random in motion. It is not that heat cannot be transferred from a cold object to a hot object, but because:
From a statistical point of view, an atom of a fast-moving hot object is more likely to hit an atom of a cold object and transfer some energy to it; while the probability of the reverse process is very small. Energy is conserved in the collision process, but when a large number of accidental collisions occur, energy tends to be evenly distributed.
There is no physical law in this, only statistical probability. This looks very absurd.
Feynman, a staunch scientificist, later also proposed "probability amplitude" to describe the nature of the physical world.
To this, Feynman explained: Does this mean that physics-a very precise discipline-has degenerated to the point where it can only calculate the probability of events, but cannot accurately predict what will happen? Yes! This is a retreat! But this is how things are:
Nature only allows us to calculate probabilities, but science has not collapsed because of this.
In fact, Russell also advocated the probabilistic nature of causality, thinking that all laws have exceptions, so he did not agree with strict determinism.
Perhaps because they both hold a "bottom-up" worldview, Boltzmann liked Darwin and declared in a lecture:
"If you ask me what I believe deep down in my heart, will our century be called the iron age or the steam or electricity age? I will answer without hesitation: it will be called the mechanical view of nature century, Darwin's century."
For Darwin's natural selection theory, Boltzmann realized that living beings compete for resources through "a battle that minimizes entropy", and life is a struggle to reduce entropy by capturing as much available energy as possible.
Like life systems, artificial intelligence is also a system that can automatically achieve "entropy reduction".
Life feeds on "negative entropy", while artificial intelligence systems consume computing power and data.
Le Cun estimates that it takes 100,000 GPUs to approach the brain's computing power. The power of a GPU is about 250 watts, while the power of the human brain is only about 25 watts.
This means that the efficiency of silicon-based intelligence is one millionth of that of carbon-based intelligence.
Therefore, Sutton believes that the key to overcoming the limitations of artificial intelligence lies in building "a bridge connecting computer science and biology".
Chapter.11
Da Vinci once said: "Simplicity is the ultimate complexity."
The scientists of Newton's generation who believed in God thought that God must have used rules when creating the world.
They just went to discover the rules, without worrying about the temporary incomprehensibility. For example, why does the formula of universal gravitation look like that? Why is it inversely proportional to the square of the distance?
On the other hand, the Newtonians adhered to the principle of Occam's razor, believing that the model of the world was based on some simple formulas. They at least believed that there was such a formula, from Einstein to Hawking, all of them did.
However, in the era of uncertainty, probability seems to explain this world better than determinism. Newtonian certainty has shrunk to a limited domain.
Perhaps Feynman was right, scientists were testing this world with a sieve, and sometimes it seemed that all phenomena could pass through the sieve holes, but now we know how complete science is only a temporary explanation, only a temporarily unfalsified sieve. But this does not affect us moving forward.
There is another philosophy that believes that the world itself is modeling itself. It is almost impossible to explain the world with a grand unified theory, let alone that the universe is still expanding.
From the above interesting but slightly vague perspective, ChatGPT is modeling the world in an anti-Einsteinian way. It has the following characteristics:
It is probabilistic, not causal;
It tries to simulate the human world as a "big model", learning and evolving from experience, rather than seeking the first principle;
It believes (at least for now) that "complexity is the ultimate simplicity";
It expelled God. Because it is becoming more and more like a god.
AI and other human-like things are often cyclical.
The last wave was in 2016, heated up, and then slowly calmed down.
Seven years have passed, and AI has heated up again. Open AI did not open the "black box" as usual, but brought a more widespread wave of influence.
This time, extensiveness seems to have defeated professionalism. People seem to be more concerned about the AI that can draw pictures and may replace their own fishing, rather than the AI that can defeat the world champion and research protein folding to solve human top problems.
How much of this is engineering breakthroughs and technological leaps? How much is a miracle driven by business? How much is human society's usual bubble?
There is no doubt that many of the great breakthroughs in human history have been achieved under the interweaving of various rational and irrational forces.
The opportunities here are:
1. Water sellers. Such as Nvidia, Scale AI, etc.;
2. The emergence of new platforms. Will there be super applications that break through Microsoft and Google's invincible old wine in new bottles?
3. The new platform has both new value spaces created by improving productivity, such as various new products and services, and plundering of old value spaces;
4. There may be iPhone disruptors, as well as various applications and services around it;
5. AI will become infrastructure.
However, water and electricity become infrastructure, the Internet becomes infrastructure, and AI becomes infrastructure are not simple analogies or upgrades.
The general trend may be that business monopoly and polarization will become more cruel. Professionally, perhaps the middle class will become more hopeless;
6. Because AI consumes a lot of electricity, there is a lot to do in the energy field;
7. There will be opportunities for "scenarios" and "applications". Especially those that can better use AI platforms to achieve human-computer integration scenarios and applications.
8. For individuals, what we have to ask is whether AI still needs humans to play roles similar to "operators, drivers, programmers, couriers" in new infrastructure and new systems?
Chapter.12
The changes of artificial intelligence almost correspond to the changes of human cognitive world.
From certainty to uncertainty, from physical laws to statistical probability, physics and information converge at "entropy", and evolve into living entropy reduction systems with similar Darwinian ideas.
In this increasingly bewildered world, AI has gained extra attention from the world after the epidemic;
The gods have been abandoned by humans, and algorithms have replaced mysticism and causal hegemony with powerful and unknown correlations, as if becoming new gods.
Reality and belief, certainty and randomness, consciousness and nothingness, once again confront each other at the edge of the cliff of the times in the carnival of the masses.
From an optimistic point of view, Newton's followers and Darwin's followers may join hands and use artificial intelligence that does not know where the evolutionary boundary is to break through the boundary of human wisdom.
Hayek said: "An order is desirable not because it puts each element in its place, but because it can grow new forces that cannot grow under other circumstances on this order."
So far, we still cannot define what intelligence is, what consciousness is.
However, there is a dark box that tells us that we may surpass human intelligence, and even emerge human consciousness.
Microsoft's report wrote:
We have not solved the basic problem of why and how to achieve such excellent intelligence. How does it reason, plan and create?
Why does it show such universal and flexible intelligence when its core is just simple algorithm components--the combination of gradient descent and large-scale transformers with extremely large amounts of data?
AI researchers admit that whether intelligence can be achieved without any agent or intrinsic motivation is an important philosophical question.
In this not easy spring of 2023, I am calm and expectant about ChatGPT:
I hope to see its possibilities and bring some "entropy reduction" to this chaotic world.
Among all predictions, I look forward to Kurzweil's prophecy that "technology will make humans enjoy eternal life by 2030".
I am not interested in eternal life, but I don't want to lose the people around me. I depend more on the secular than on the "transhumanism".
I don't believe in uploading consciousness, because once uploaded, it can be copied, it is not unique, it loses free will, and what is "consciousness" then?
Will humans penetrate the deepest secrets of the brain? Tom Stoppard warned:
"When we discover all the secrets and lose all the meaning, we will be alone on the empty beach."
Gödel's "incompleteness theorem" tells us that uncertainty is inherent in human cognition's formal logical thinking.
"A computer can modify its own program, but cannot violate its own instructions--at best it can only change some parts of itself by obeying its own instructions."
Did Gödel set boundaries for AI and humans? Otherwise, humans create super AI, and then worship it as a god. Isn't that self-enslavement?
Gödel also told us that humans can always introduce new things that constitute a higher-level formal system in "realism" through "intuition and intuition", and establish a new axiom system, thus advancing to infinity.
This is Penrose's view that "human mind surpasses computer".
END
The last time, seven years ago, humans had cried in front of AlphaGo;
This time, no one cried, but there was a carnival of thousands.
In the seven years between the two AI climaxes, we have experienced a lot and lost a lot.
People long to embrace some hope, some certainty, even if those certainties come from some uncertain wisdom.
As for myself, I have also encountered some unprecedented difficult moments. The so-called difficulty does not mean some difficult choices, nor does it mean that there are no options.
On the contrary, according to the optimal decision principle, I can easily calculate the expected value and get the so-called maximized benefit.
However, I traced back to the source of my heart, redefined my expected utility, and then made a somewhat Crichton-style "Faith-based differentiated" choice based on it.
For anyone, whether it is difficult or easy, smart or stupid, rational or willful, this kind of thing is only a small dish on the technical level.
But for AI, it is temporarily difficult to define its own expected utility.
Therefore, researchers say that equipping "large language models" with agency and intrinsic motivation is an important and fascinating direction for future work.
And these two points of "agency" and "intrinsic motivation", an ordinary human being can achieve in a second or a few sleepless nights.
Perhaps the key is not in gain or loss, not in utility function, but in "existence".
As Italo Calvino said:
"As time goes by, I slowly understand that only things that exist will disappear, whether it is a city, love, or parents."
In the legendary story written at the beginning of this article, the extraordinary friendship between the sweeping boy Pitts and Professor McCulloch lasted until their death.
Compared with the psychology professor "Williams" in the movie "Good Will Hunting", McCulloch's feelings for Pitts were deeper, full of fatherly love and academic "harmony".

Later, when McCulloch had a falling out with Wiener, the father of cybernetics, Pitts stood firmly on McCulloch's side, even though Wiener was his doctoral supervisor and could almost determine his academic future. Pitts even burned his own paper for this.
He was passionate and impulsive like a street boy.
Soon after, Pitts suffered another academic blow, as an experiment showed that logic did not seem to determine brain thinking processes as his theory had expected.
The boiler worker's child returned to the shackles of fate. The passion for mathematics and logic that had ignited his dark years, and the genius-like ideas about artificial intelligence, were gradually drowned by the worldly smoke.
The falling genius used his self-destruction that could not be cut off in his blood to rebel against his unparalleled logical talent. Pitts began to drink heavily and finally died alone in a boarding house at the age of 46.
Four months later, McCulloch also died in the same year.
Many years later, when people trace the ups and downs of the development of neural networks, they will always come to the starting point: the monument jointly built by McCulloch and Pitts.
Just like we come to the source of a great river and find nothing but a small stream.
Gödel once left a sentence in his philosophical manuscript: The meaning of the world lies in the separation of facts and desires, that is, things go against one's wishes.
I prefer to use Gibran's words to replace Gödel's confusion, although it may be the same thing at the bottom. The poet said:
We live only to discover beauty, everything else is a form of waiting.
Translated form here
https://mp.weixin.qq.com/s?__biz=MjM5ODAyMjg3Ng==&mid=2650757382&idx=1&sn=7f6893e0ed8be35bcdc5818457529600