



If you find our articles informative, please follow me to receive updates. It would be even better if you could also follow our ko-fi, where there are many more articles and tutorials that I believe would be very beneficial for you!
如果你觉得我们的文章有料,请关注我获得更新通知,
如果能同时关注我们的 ko-fi 就更好了,
那里有多得多的文章和教程! 相信能使您获益良多.
For collaboration and article reprint inquiries, please send an email to [email protected]
合作和文章转载 请发送邮件至 [email protected]
By: ash0080

I'm sure anyone who has used Stable Diffusion for a while has encountered the dreaded CUDA OUT OF MEMORY error. It's a problem that has plagued me for a long time and has caused me endless frustration. In earlier versions of the WebUI, you couldn't even release the VRAM by restarting, and you had to resort to reboot your PC. So one day, I made up my mind to solve this problem once and for all. And guess what? I actually managed to do it! Now, I want to share my experience with all of you.
Smart Settings to Increase CUDA VRAM Garbage Collection Efficiency
[!Note] this operation is only applicable to Nvidia graphics cards. If you have a different type of graphics card or are a Mac user, please skip this step.
// add this line in your webui-user.bat
set PYTORCH_CUDA_ALLOC_CONF=garbage_collection_threshold:0.9,max_split_size_mb:512 In most cases, the above arguments are already set to the optimal configuration. However, if your VRAM is larger than 24GB, you can consider setting max_split_size_mb to 1024 or higher. If your VRAM is smaller, you should decrease it, but not lower than 128. If you experience crashes in the SD WebUI process, you can try decreasing the garbage_collection_threshold parameter, but it's recommended not to set it lower than 0.6.
Magic Plugin to Estimate VRAM Consumption Before Run
We'll be using the VRAM-ESTIMATOR plugin, which you can install directly from the Extensions panel in the WebUI.
https://github.com/space-nuko/a1111-stable-diffusion-webui-vram-estimator
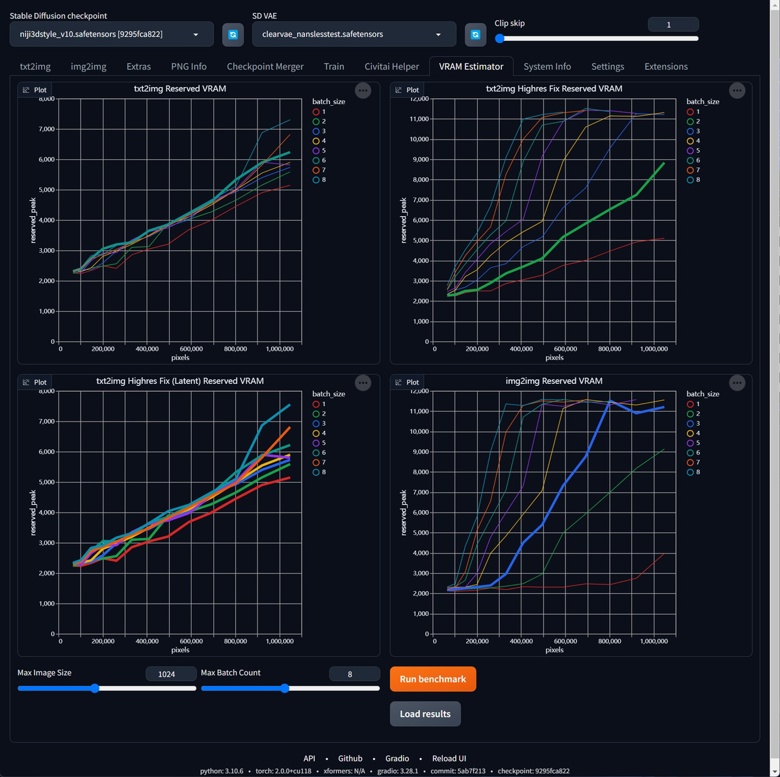
Once installed, you'll see a VRAM Estimator panel added to your SD WebUI. To use it, you'll need to run the benchmark first. Depending on your VRAM size, this process can take anywhere from several tens of minutes to several hours. If your VRAM is larger than 16GB, it's recommended to increase the Max Image Size to 2048 and simultaneously increase the Max Batch Count to 16. This will help determine the actual execution limit of your GPU. You only need to do this once, but if you change your GPU, upgrade PyTorch, or update the SD WebUI with major changes, such as the introduction of new accelerators, it's recommended to run the benchmark again.
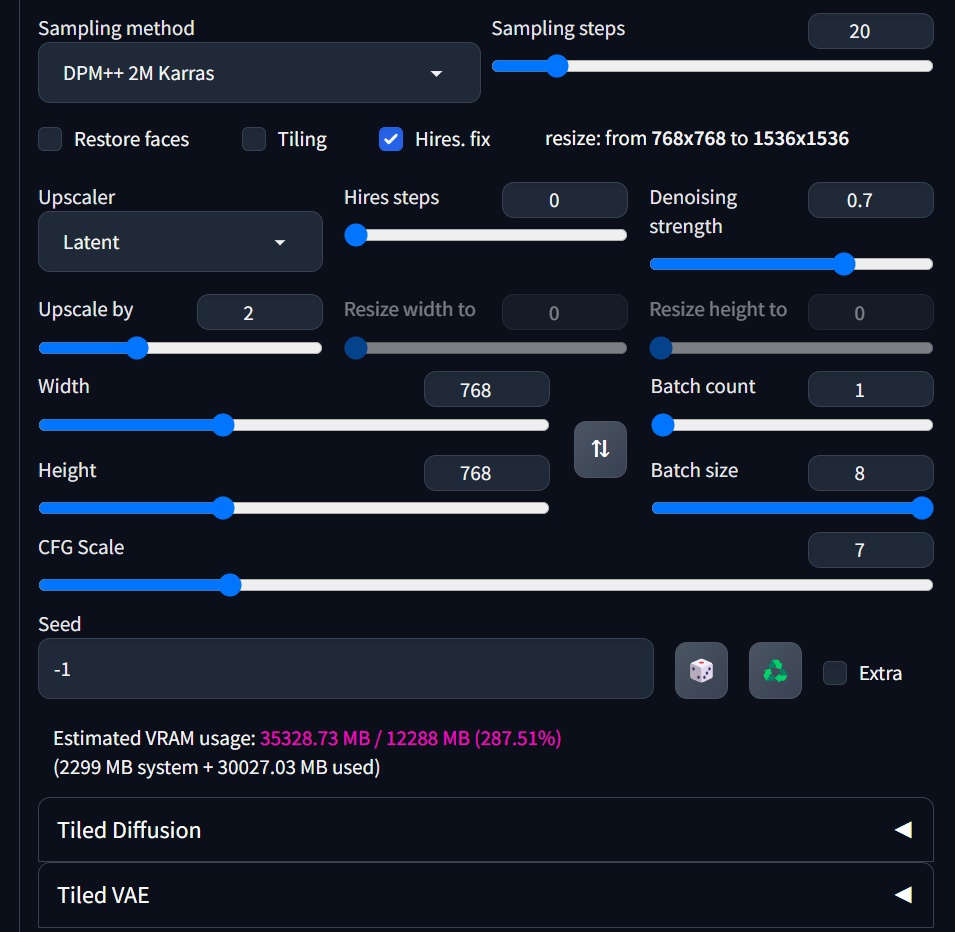
After completing the benchmark, the plugin will help you estimate the VRAM consumption for each task whenever you change the parameters. It will even color-code the estimates to help you avoid VRAM overflow in 99% of cases. The plugin works for all hardware configurations, and you can even use it on a Mac.
Ultimate Solution: Forcefully Clearing VRAM
Even after doing the above steps, sometimes we still find that VRAM is occupied and not released. This is mainly due to Python's garbage collection mechanism and is a known issue. In the past, the only solution was to restart the SD WebUI or even the entire system. However, now you can manually release VRAM by clicking the "Unload SD checkpoint to free VRAM" button in Settings > Actions. Yay! No more restarting! This is the ultimate solution that can handle everything. However, if you've correctly configured the above two steps, you probably won't need to manually release VRAM very often.
ex. How can we significantly improve generating speed and efficiency after fixing the VRAM overflow issue?
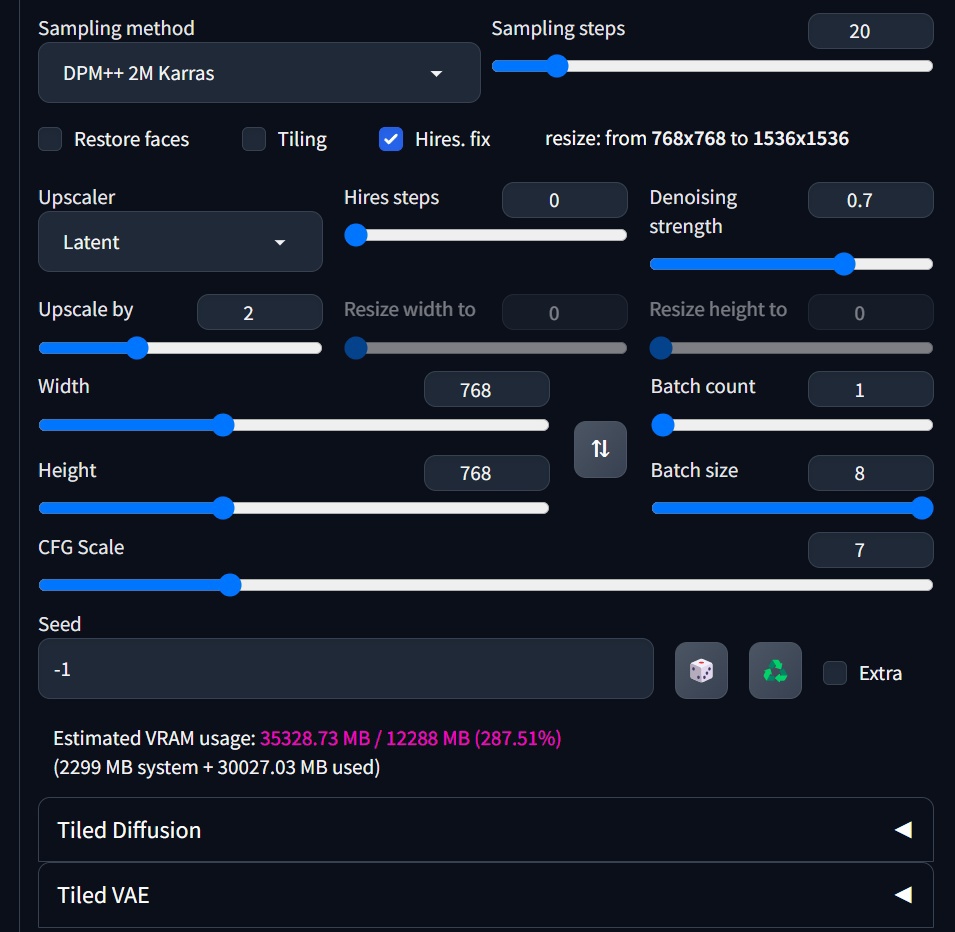
Let's go back to this screenshot. Once we can accurately estimate VRAM usage, we can safely use the Batch Size parameter. In situations where VRAM overflow is not an issue, we can increase the Batch Size as much as possible to significantly improve generating speed by several times. This estimation is also effective for tasks like HI-RES and INPAINT, and can cover most of the daily work applications. As for why it's Batch Size and not Batch Count, let's save that for next time.