Hello there,
I'm AfterDarkPro. I've been in the 1girl image generation game for a few years now ever since SD1.5. Lately though, I've been wanting to generate 2girls images. A huge leap, I know. But then I even thought what about 3girls???
But as I found out, SDXL models can actually not do great when there is a complex composition or an image with multiple subjects in it. I don't want to move on just yet to flux or other models that are better at composition, so I have been iterating on a SDXL workflow that can generate complex images fast.
I'm finally ready to share version 8 of my Advanced Composition workflow. Here's why I think this workflow is the best.
No manual masking for area composition. Other multi-subject workflows require this. It's annoying and time consuming when it even works.
It lets you establish the composition via the Compositor node prior to doing the final render pass.
It theoretically can handle as many as 8 "subjects" i.e. inputs into the Compositor. I currently find 3 is enough. "Subjects" meaning an input area could have multiple subjects; i.e. A boy and a girl in one render.
No photoshop required. It can be used since inputs are saved to a folder first before inserted into the compositor.
It does advanced NSFW stuff well. (DM me for examples)
Here's what this workflow can output. These use Illustrious as the base model.



These are all made in 1 final render pass in 1 workflow. Lets talk about how:
There are two hearts of the workflow:
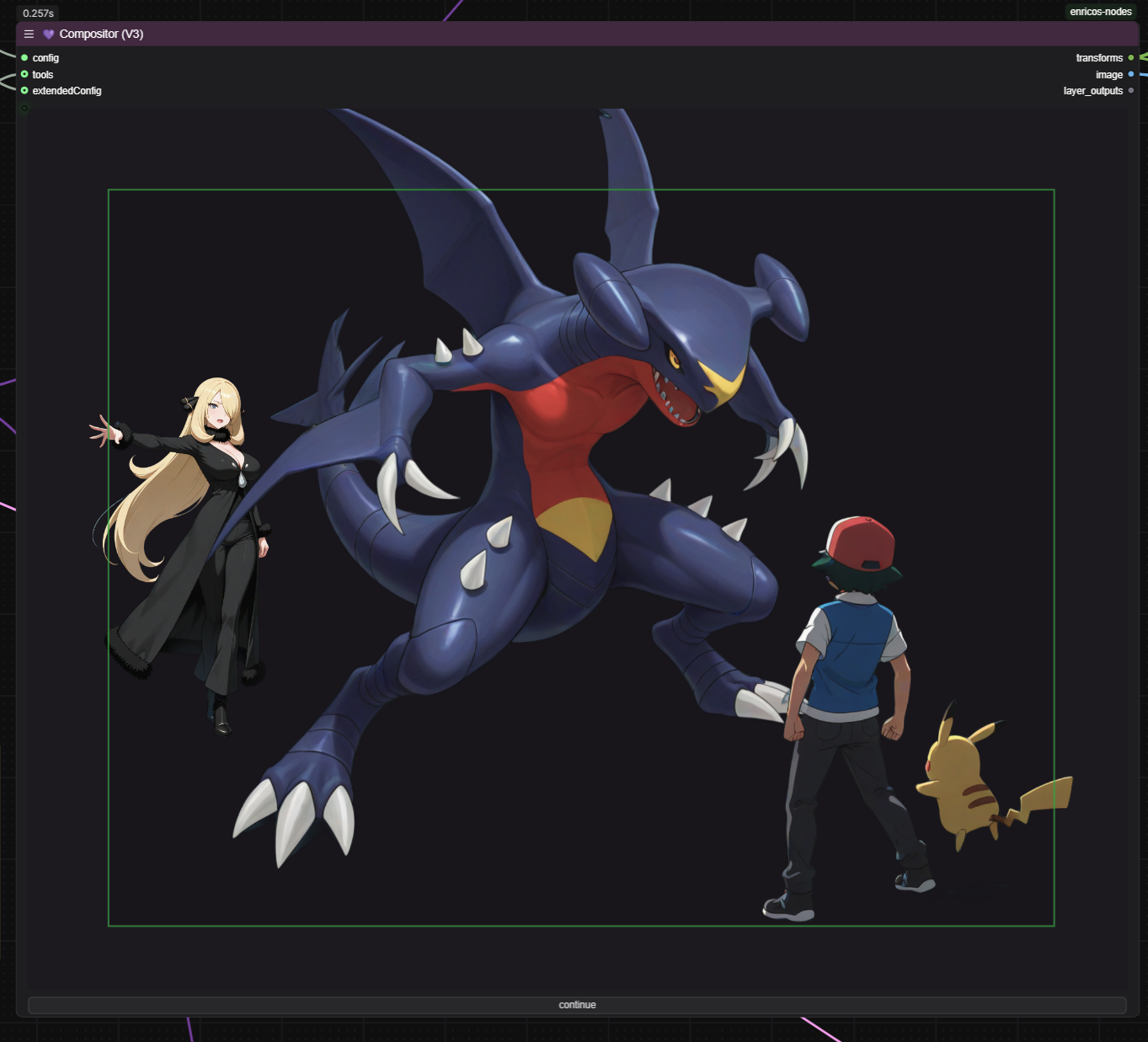
It lets you add input images and manipulate the size, placement and rotation of up to 8 inputs. I can then pull the mask of each subject for later use in the final render.
And the Attention Couple Node: https://github.com/laksjdjf/cgem156-ComfyUI
This lets you input conditionings and associate them with a mask. The workflow also has more traditional Conditioning (set mask) nodes from the comfy-core node pack as reinforcement, but the Attention Couple Node works a lot better.
Before anything else, setup the checkpoint, and folder locations to save your step 1 images, and final images
In order to make the input images, I start at the First Pass Ksampler area where I prompt images normally to get poses or actions that I want. The backgrounds of these images are prompted to always be simple blue backgrounds for easy removal later. The alpha channel images are saved to my hard drive to then load into the compositor. I do it this way so that I can close comfyui and come back later and the first pass images are still there.
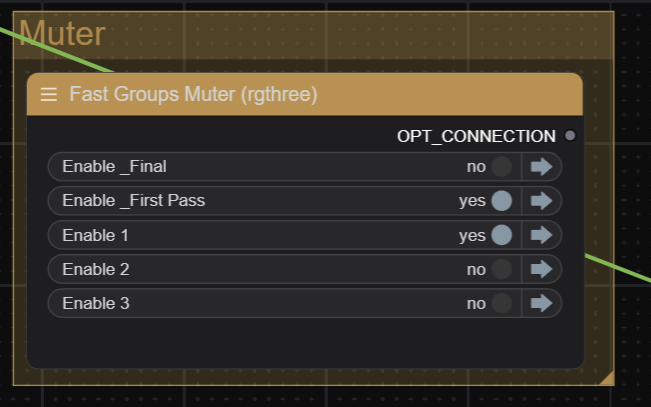
First pass is enabled by toggling on "First Pass" and the respective subject prompt. (1-3)
The second step is to toggle off the above and run the workflow to load in the images to the compositor. Then adjust the composition, final image aspect ratio (via the CR SDXL Aspect ratio node) to your liking and finally:
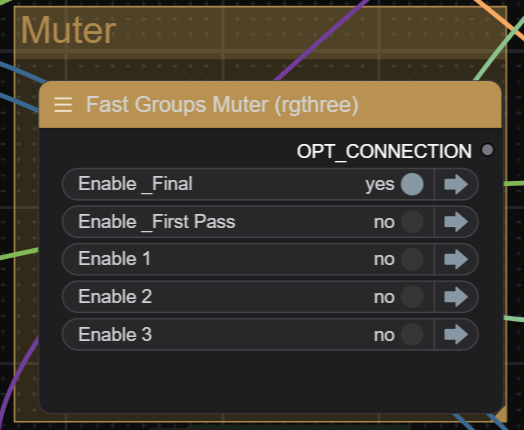
Toggle on the "_Final"
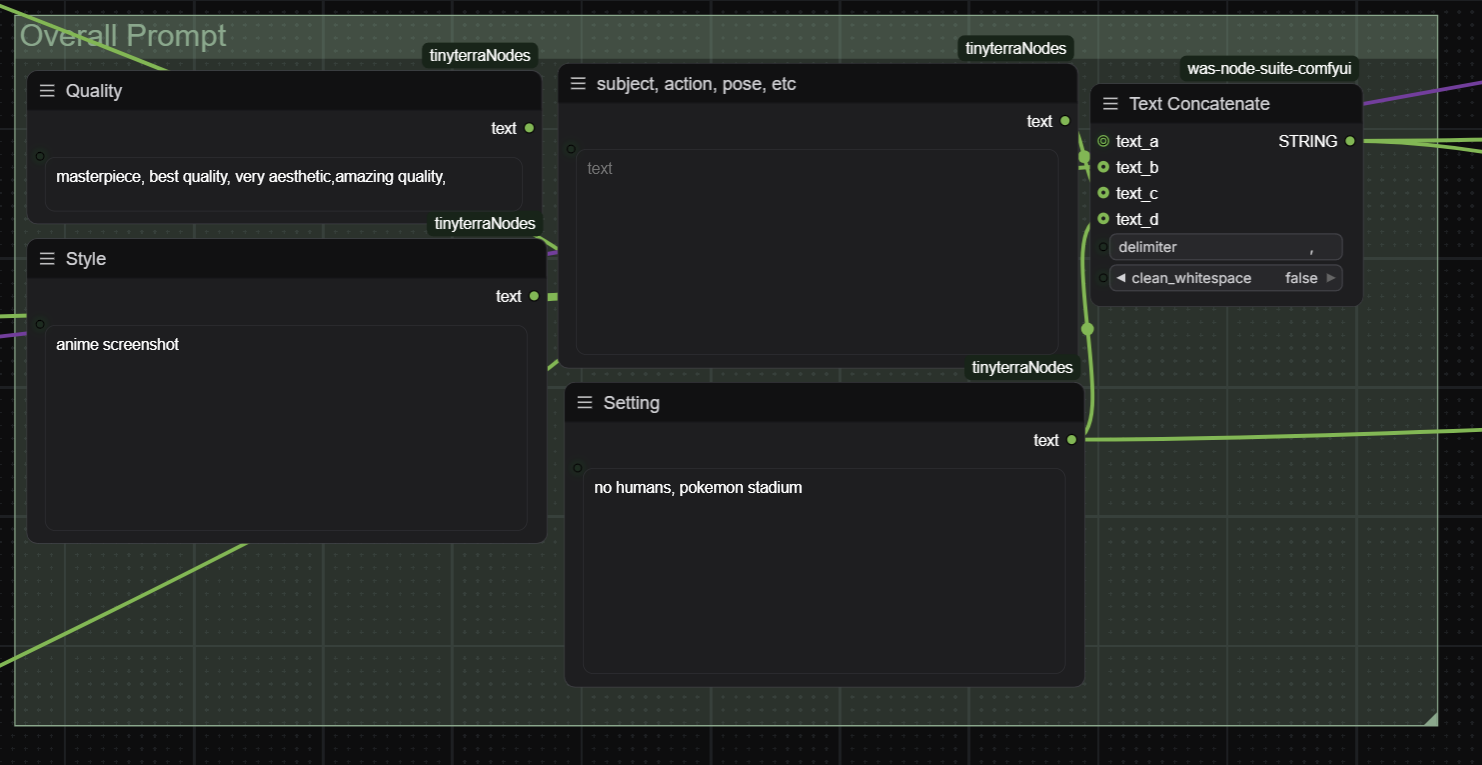
Write the final overall prompt
Run the workflow and it will be able to output similar images to the examples I provide above.
That's really it.
I can mess with the depth control net for the final render as well as the resolution, prompts and final denoise level (usually lowering it) if I run into prompt adherence issues like a character not showing up right.
Here are the downsides.
The final image is rendered at 1.5x the base SDXL standard resolution, so there is a base level of VRAM that may be used. I currently own a 16GB card, but was able to run earlier iterations of this workflow on a 12GB card about a 6 months ago before I upgraded.
Rendering under 1.5x Latent Upscale can work if your subjects are composed large enough. They can't be too small or the detail disappears completely.
Lora's can be used in the first-pass, but they tend to need to be low strength in the final render or there is bleed between subjects so there are a few nodes in placed to auto scale those down.
Adding inputs into the compositor can be a pain, which is why I don't have 4 at the moment.
I'm using a distilled Illustrious model with the DMD2 LORA, which assists greatly with speed. Not necessarily a downside, since I think the quality in the final output is very high.
It can be hard to get the prompting down in the first generation. I will often iterate on the final generation to find a good output. But generally, getting something I like takes 5-10 minutes from start to finish.
I hope some people test this version out. Let me know if there are questions, or DM me if you have a request for a render!