I have been working on Stable Diffusion 1.5-based models’ fine-tuning for several days. I’ve done over 40 full SD 1.5-based model DreamBooth trainings (full fine-tuning with prior preservation).
Even though I was training empirically and meticulously, the model was either getting undertrained or overtrained.
I couldn’t find the reason.
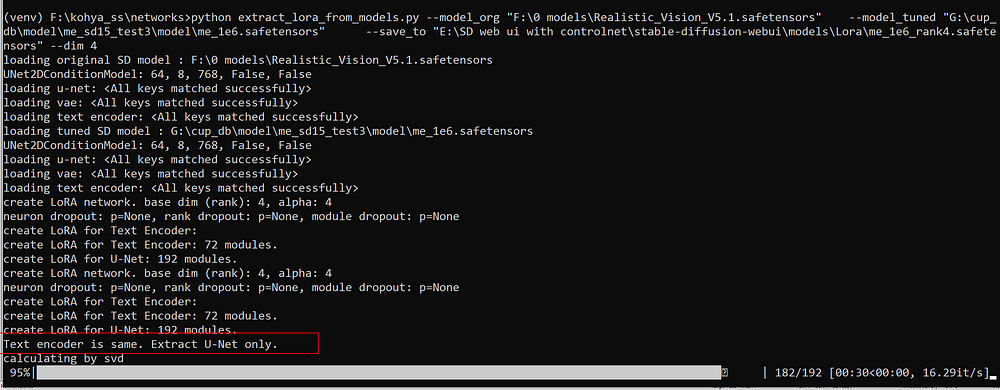
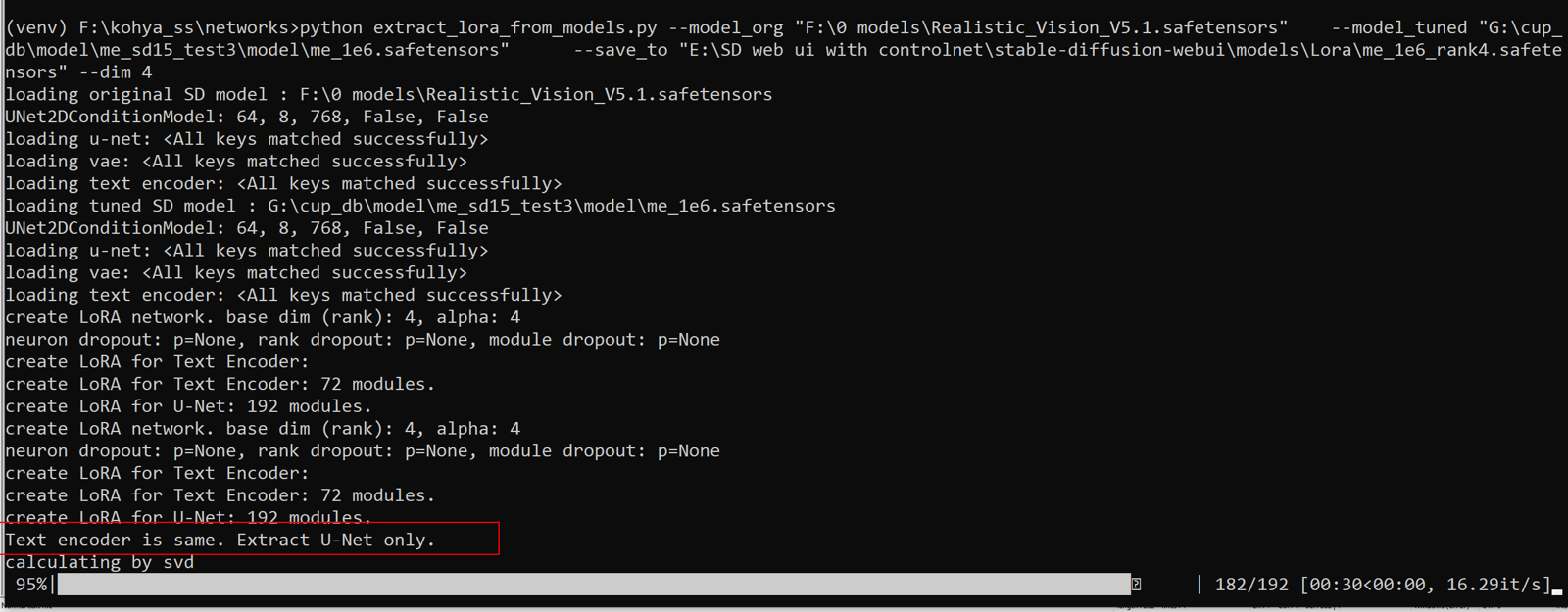
The client was requesting to save trainings as LoRA instead of full checkpoints.
So, when I tried to extract LoRA from the trained model for the first time, I found the reason. The extractor indicated that the text encoders were the same. This means that the whole time I only trained the U-NET, which led to extremely bad results compared to what I could have achieved.
So many hours, resources, and money were wasted.
This is also not the first time this has happened to me. Of course, I am extremely grateful to the open-source developers. They are doing this voluntarily.
I contacted the developer and he verified the issue. I hope he will fix it soon. The mistake was not caused by the developer.
This is very possibly caused by Diffusers or Transformers version upgrade, and possibly Accelerate. These three libraries are the most problematic ones that have zero backward compatibility.