Table of contents

ThinkDiffusionXL is the premier Stable Diffusion model
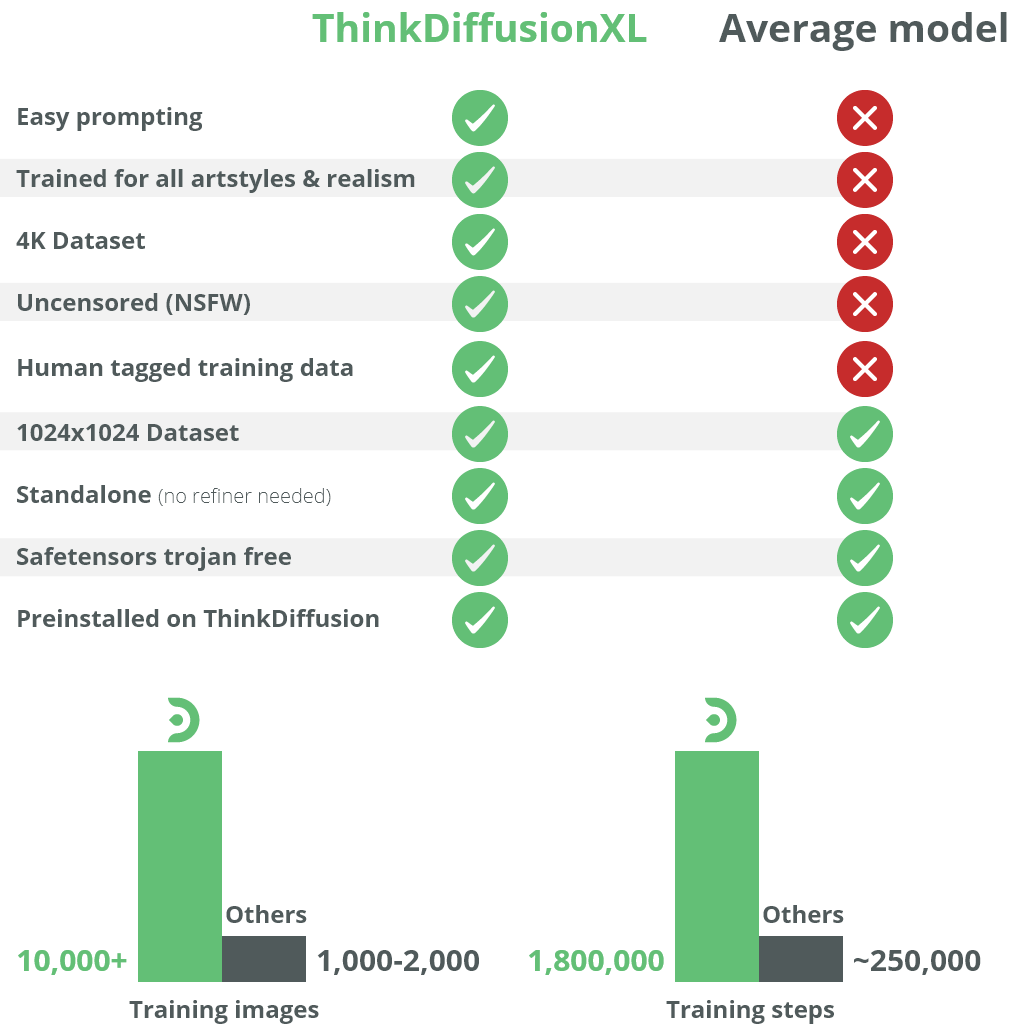
With over 10,000 training images split into multiple training categories, ThinkDiffusionXL is one of its kind. It has been meticulously crafted by veteran model creators to achieve the very best AI art and Stable Diffusion has to offer. The training time and capacity far surpass other custom models on the market and we're providing this model to you, 100% free of charge. You can use it preinstalled here on ThinkDiffusion or download it to use locally.
The model has been trained to work excellent without the SDXL refiner but works well with it if you prefer that workflow.

No limits! All artstyles + photorealism
We decided early on to not limit ourselves. ThinkDiffusionXL has been trained to manage both photorealism, digital art, anime and many other artstyles. We managed this by dividing the training set into categories which have been trained individually to achieve the best possible result.



Easy prompting
ThinkDiffusionXL has been trained to promote easy prompting. That means that you will get good looking images with fewer words than previously required. But you can still use your detailed prompts from before!




Training data manually tagged by humans
All 10,000+ images in our training data set have been manually tagged in great detail by our team. Where others might use automatic tools to tag the images in the training set, we wanted the best result possible with no potential computer errors from automatic tagging. This gives you much better control over the images while prompting.

manual labour
Model Comparisons - Cinematic Realism
cinematic food photography, burger and fries
If you look closely at the details, notice that ThinkDiffusionXL provides a very realistic experience without an overly saturated plastic feel which was prevalent in for example the SDXL base model. The colours are inherently more muted for realism but can still be prompted to provide high contrast vibrant coloured images. While using prompt word 'cinematic' you will truly get a more cinematic vibe to your images – an exquisite world of color graded film.

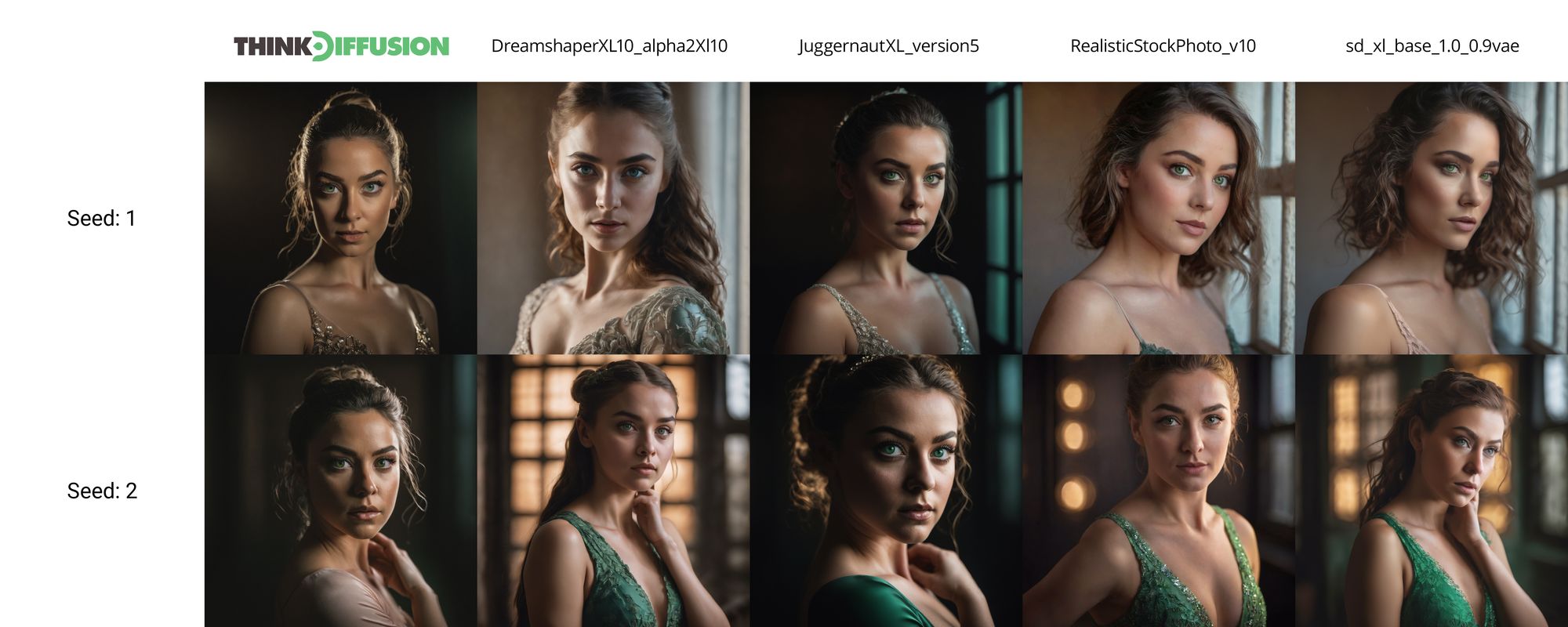
cinematic mid shot portrait, ballerina green eyes, dramatic lighting
In this example we're using dramatic lighting and a focus on the character's green eyes. We have painstakingly trained extra on eyes and other details which you will see while prompting for that. Whenever you create portraits, try including your choice of coloured eyes like 'blue eyes' or 'brown eyes'. You can also try other colours: 'red eyes', 'aquamarine eyes'.
We have also spent time trying to improve on skin texture in general. SDXL base model will give you a very smooth, almost airbrushed skin texture, especially for women. Our goal has been to provide a more realistic experience while still retaining the options for other artstyles.
hdr high contrast, lamborghini car photography, beautiful dramatic lighting, smoke
Try using the prompt 'car photography' and a full featured set of training data specific to cars will help you provide great looking images.

Uncensored (NSFW)
The model is uncensored and includes training data of over 1,000 tasteful uncensored images. Any training data used have characters that are 18+. The model is built to provide SFW images if you are not prompting for NSFW, so make sure you weight your NSFW prompts properly.


Try it out here: https://civitai.com/models/169868/thinkdiffusionxl
Original article can be found here: https://learn.thinkdiffusion.com/thinkdiffusionxl-model-draft/