
Etiquetar personajes y estilos en modelos de inteligencia artificial es una forma efectiva de mejorar la capacidad del modelo para comprender y generar imágenes específicas. A través de la etiquetación, se le proporciona al modelo información detallada sobre las características de los personajes y los estilos deseados. En esta guía, exploraremos cómo y cuándo etiquetar personajes y estilos, así como los beneficios y consideraciones clave al hacerlo.
¿Cuándo etiquetar?
La etiquetación de personajes y estilos no siempre es estrictamente necesaria, pero puede agregar una capa adicional de información para correlacionar un personaje con las etiquetas asociadas. A continuación, se presentan algunas situaciones en las que es recomendable etiquetar:
Entrenamiento de múltiples personajes: Si estás entrenando el modelo con más de un personaje, es recomendable etiquetar cada personaje individualmente. Esto ayuda al modelo a distinguir entre diferentes personajes y generar imágenes específicas para cada uno.
Especificar detalles clave: Etiqueta aquellos elementos que deseas que el modelo esté consciente de manera explícita. Si hay características o detalles particulares que deseas que el modelo aprenda a reconocer y generar, asegúrate de etiquetarlos. Por ejemplo, si un personaje tiene un sombrero, proporciona imágenes etiquetadas con y sin el sombrero para enseñarle al modelo a reconocer esta característica. Mas aun recuerda que la generación de dichos elementos no sera de forma automática debido a los tags.
Colores y tipos de cabello y ropa: Es recomendable etiquetar los colores y tipos de cabello, así como los colores y tipos de ropa de los personajes. Estos son elementos clave que el modelo puede aprender a generar de manera más coherente cuando se les etiqueta correctamente. En definitiva asigna un peinado a un color de pelo, y dicho peinado a un rostro, y dicho rostro forma un personaje, por lo cual un color de pelo se transforma en un elemento mas importante como la persona que lo porta.
Poses y expresiones: Las poses y expresiones también son importantes de etiquetar. Esto ayuda al modelo a generar imágenes con variaciones en las poses y expresiones de los personajes, en lugar de producir imágenes repetitivas y monótonas. Y ayuda muchísimo a aislar problemas con poses complicadas, al mismo tiempo dificultan el entendimiento del concepto, por dicha aislacion.
Elementos relevantes: Si hay otros elementos o características importantes que deseas que el modelo genere con mayor frecuencia, etiquétalos. Esto puede incluir detalles específicos como accesorios, objetos o características físicas distintivas. Es decir, si queremos que una manzana sea particularmente idéntica a la entrenada, es recomendable etiquetarla.
Etiquetación negativa: La conciencia de las etiquetas también puede ser utilizada para indicar elementos que deseas evitar en las generaciones. Si hay características que no deseas que aparezcan en las imágenes generadas, etiquétalas como negativas. Por ejemplo podes usar la etiqueta NoPerro y asignarle todo las cosas que no te gusten del modelo, luego podes poner esa etiqueta como un tag negativo para restar de forma muy como da un montón de atributos que te resulten molestos.
Como resumen el etiquetado de imágenes es esencial en el entrenamiento de modelos de Inteligencia Artificial para reconocer y clasificar objetos, personas y escenas. Proporciona información adicional y estructurada que ayuda a los modelos a aprender y generalizar patrones visuales. El etiquetado preciso y detallado de características como objetos, poses, colores y estilos permite a los modelos capturar las características esenciales de las imágenes. A medida que los modelos de IA se entrenan con conjuntos de datos etiquetados, aprenden a asociar las etiquetas con las características visuales correspondientes, lo que les permite realizar tareas de reconocimiento y generación de contenido visual con mayor precisión.
Para generalizar la idea formula la siguiente relación:
Fórmula para el etiquetado de información:
𝑇𝑎𝑝𝑝𝑖𝑛𝑔_𝐴𝑐𝑐 = 𝐾 × (1 − 𝐸𝑟𝑟𝑜𝑟_𝑅𝑎𝑡𝑖𝑜) × 𝐼𝑛𝑓𝑙𝑢𝑒𝑛𝑐𝑖𝑎_𝐷𝑖𝑠𝑐𝑜𝑣𝑒𝑟𝑦
Explicación:
𝑇𝑎𝑝𝑝𝑖𝑛𝑔_𝐴𝑐𝑐 representa el nivel de etiquetado necesario para una imagen específica en el conjunto de datos.
𝐾 es una constante que representa la complejidad del conjunto de datos, siendo k > 1 para modelos complejos y K <1 para modelos simples, recordando que la dificultad de un modelo a la fecha actual se mide en función de la interaccion entre objetos y comprensión de ideas abstractas.
𝐸𝑟𝑟𝑜𝑟_𝑅𝑎𝑡𝑖𝑜 es la tasa de error esperada en el etiquetado, la cual es propia de cada sitema de etiquetado, consideramos un 𝐸𝑟𝑟𝑜𝑟_𝑅𝑎𝑡𝑖𝑜 = 0 para los humanos y un 𝐸𝑟𝑟𝑜𝑟_𝑅𝑎𝑡𝑖𝑜 > 0 para etiquetados brindados por sistemas automáticos, entiéndase que la relacion es negativa dado que cuanto mas grande sea el error, mas "basura" aporta al entrenamiento, por lo que buscamos limitar el agregado de error.
𝐼𝑛𝑓𝑙𝑢𝑒𝑛𝑐𝑖𝑎_𝐷𝑖𝑠𝑐𝑜𝑣𝑒𝑟𝑦 es la información de la descripción de la imagen disponible. Cuanto mas dispongamos de información y tags verídicos, mas querremos usarlos.
Esta fórmula podría utilizarse para determinar el nivel de etiquetado necesario para cada imagen en un conjunto de datos, teniendo en cuenta la complejidad del concepto, la tasa de error esperada y la información disponible en la descripción de la imagen.
¿Qué no etiquetar?
Mientras que etiquetar ciertos elementos puede ser beneficioso, también es importante tener en cuenta qué no etiquetar:
Detalles obvios: No es necesario etiquetar elementos obvios, como la presencia de una cara o manos en un personaje humano. El modelo puede inferir estas características por sí mismo. Mas aun las aislaras y podrías producir que el modelo genere personas sin manos a no ser que se las muestres: Para que este fenómeno ocurra es necesario entrenar imágenes con manos y sin manos (guardadas en los bolsillos, fuera de imagen, no pintadas, ect), al targetiar las manos haces que estas se vuelvan optativas. (cosa muy útil y problemática)
Estilo/artista: No es estrictamente necesario etiquetar el estilo o el artista. A menos que haya características de estilo específicas que desees que el modelo aprenda a generar, no es necesario etiquetar este tipo de información. En caso de hacerlo el estilo se guardara en un tag, por ejemplo pixel art, retro, monocromatico, hay muchos tags de estilos. Aunque no son muy vistos.
Fondos simples: Si bien puedes etiquetar fondos simples para influir en las generaciones, ten en cuenta que esto puede hacer que el modelo genere imágenes con fondos simples de manera más consistente. Si deseas variedad en los fondos, es mejor evitar etiquetarlos. Esto no incluye etiquetados como fondo negro, blanco ,ect, . El punto es que es preferible no indicar los fondos a no ser que los mismos sean totalidades, ende no uses un tag como : ciudad, casa,campo. Por que no? Por que el programa tranquilamente puede asignarle campo a algo que no necesariamente es un campo y en su lugar es algo útil para el modelo: como los ojos del personaje. De todas formas esto no es un absoluto, mas adelante comprenderás porque.
Errores comunes y depuración de etiquetas:
A medida que pruebes tu modelo, es posible que encuentres ciertos elementos que se generan de manera persistente o resultan difíciles de eliminar. En esos casos, es probable que haya errores en las etiquetas. Aquí hay algunas estrategias para depurar y corregir las etiquetas:
Elimina etiquetas incorrectas: Si notas que ciertas etiquetas generan resultados incorrectos o no deseados, asegúrate de eliminar esas etiquetas del conjunto de datos de entrenamiento. Esto ayudará a mejorar la calidad de las generaciones.
Etiquetación específica: Si hay elementos que deseas que se generen de manera consistente, enfócate en etiquetar esos elementos de manera más específica. Proporciona ejemplos claros y detallados de cómo debería ser ese elemento en las imágenes generadas.
Consolidación de etiquetas: A menudo, el modelo proporcionará varias etiquetas relacionadas cuando detecte un elemento en una imagen. En lugar de mantener todas las etiquetas, trata de consolidarlas en una única etiqueta más descriptiva. Esto ayudará a simplificar la información para el modelo.
Prueba y ajuste: La depuración de etiquetas es un proceso iterativo. Realiza pruebas frecuentes con diferentes combinaciones de etiquetas y observa los resultados generados. Si sigues encontrando problemas persistentes, continúa ajustando las etiquetas y los ejemplos de entrenamiento hasta obtener los resultados deseados.
La etiquetación de personajes y estilos en modelos de inteligencia artificial es una herramienta poderosa para mejorar la capacidad del modelo para generar imágenes específicas. Al seguir las pautas de etiquetación y depuración mencionadas en esta guía, podrás entrenar y ajustar tu modelo de manera más efectiva, obteniendo resultados más coherentes y satisfactorios. Recuerda que la etiquetación es un proceso iterativo y requiere tiempo y ajustes para lograr los mejores resultados.
Opciones no tan usadas y posibles en entrenamiento comunes:
La etiquetación efectiva implica proporcionar información clara y relevante al modelo de IA. Aquí hay algunos aspectos adicionales a considerar al etiquetar personajes y estilos:
Detalles específicos del personaje: Además de etiquetar el color y el tipo de cabello, la ropa y los accesorios, es útil etiquetar características más específicas, como cicatrices, tatuajes o incluso expresiones faciales. Estos detalles permiten al modelo generar imágenes más detalladas y realistas de los personajes deseados.
Contexto y ambiente: La etiquetación no se limita solo a los personajes, sino también al entorno en el que se encuentran. Etiquetar elementos como paisajes, objetos o incluso la hora del día puede influir en la generación de imágenes coherentes y contextualmente adecuadas.
Etiquetación semántica: Además de etiquetar características visuales, considera etiquetar conceptos semánticos que describan la personalidad, la profesión o los roles de los personajes. Esto permite que el modelo comprenda mejor la naturaleza y el propósito de los personajes, generando imágenes más relevantes y coherentes.
~~~~~~~~~~~~~~~~~~~~~~~~
🏴☠️ Triggers y Pruning de Tags - Controlando el Rumbo de tus Loras
En este apasionante capítulo, exploraremos los triggers y el pruning de tags, dos técnicas fundamentales para el etiquetado de imágenes. ¡Prepárate para tomar el timón y tener el control total de tus etiquetas!
🗝️ Triggers: Activando las Etiquetas
Los triggers son poderosas herramientas que te permiten asignar etiquetas automáticamente a tus imágenes basándote en palabras clave o frases específicas. Estos activadores son como brújulas que guían a tu modelo hacia las características deseadas. Muy similar a un tag, al punto de decir que es exactamente lo mismo, la única diferencia es que son conceptos abstractos credos por uno mismo, todo el mundo sabe que un perro, pero pocos saben quien es Coco : mi perro, así que puedo usar tag: Coco, par identificar a mi fiel y gordo Coco sobre el resto de perros en el set de datos. De esa forma una vez entrenado el Lora solo tendría que usar el tag Coco y podría generar a mi perro en el dibujo, sobre el resto de perros que había en el set de datos.
Aquí te mostramos cómo utilizarlos mas detalladamente:
Define tus triggers: Identifica las palabras o frases clave que deseas utilizar para activar las etiquetas. Por ejemplo, si deseas etiquetar imágenes de personajes con cabello azul, podrías utilizar el trigger "cabello azul".
Implementa los triggers: Integra los triggers en tu código o en la configuración de tu modelo de inteligencia artificial, es decir coloca ese tag en todas las imagenes que cumplan la característica. Cuando el modelo encuentre el trigger en una imagen, automáticamente asignará la etiqueta correspondiente.
Ajusta los triggers: Experimenta con diferentes triggers y ajusta su sensibilidad para obtener los resultados deseados, manualmente el método burdo es ajustando la cantidad de imágenes en la que aparece tu triggers sobre el total de imágenes. Puedes modificar los triggers existentes o agregar nuevos triggers según tus necesidades.
Recuerda que los triggers son útiles cuando deseas asignar etiquetas específicas y evitar la asignación errónea de etiquetas. Sin embargo, debes tener cuidado de no sobrecargar tus triggers con palabras demasiado generales que puedan generar confusión o resultados imprecisos. Tambien recuerda que la utilizacion mas frecuente de esto es sobrecargar todo el modelo con un solo triggers , lo cual generalmente termina siendo inútil, ya que para eso invocas directamente al Lora, no obstante existe la manía de hacerlo impulsivamente en esta comunidad. Recuerden ejemplo de Coco, en ese caso si que tenia mas utilidad usar un "disparador/ Trigger".
🪓 Pruning de Tags: Recortando el Exceso
El pruning de tags es una técnica que te permite eliminar ciertas etiquetas para evitar variaciones no deseadas o redundancias en tus resultados. Es como recortar las velas de tu barco para navegar con mayor precisión. Y funcionan igual que la metáfora: es decir que si las recortas de mas, el barco pierde la vela y no navega ( valga la redundancia, los Loras son arrastrados por un buque de carga: el chekpoint, el cual es arrastrado por la marea: el modelo base, por lo que no necesariamente vas a quedarte frenado por no usar tags).
Aquí te mostramos cómo utilizarlo:
Identifica las etiquetas redundantes: Analiza las etiquetas asignadas a tus imágenes y determina si hay alguna que no aporte información relevante o que genere variaciones indeseadas.
Elimina las etiquetas redundantes: Ajusta tu modelo para que omita las etiquetas que consideras innecesarias. Esto puede lograrse modificando los triggers o los filtros utilizados en el proceso de etiquetado, y en general se hace de este ultimo modo, pero depende que programa uses. Tal vez encuentre que todos los tags incorrectos en realidad represente otra cosa y por tanto te gustaría usar una función de remplazo, es decir te doy un perro y en realidad es un lobo, y por tanto le pido al programa que me remplace todos los tags perros por lobos.
Código de Remplazo para Colab: #@markdown ¡Ahoy, valientes corsarios! Aquí es donde puedes saquear y cambiar los tesoros de los tags. import os def split_tags(tagstr): return [s.strip() for s in tagstr.split(",") if s.strip()] #@markdown Arrr, esos monos inquietos que se aferran a los tesoros. Tags_actuales = "monkey" #@param {type:"string"} search_tags = Tags_actuales #@markdown ¡Prepárate para reemplazar esos tags viejos por nuevos botines! reemplazar_con = "monkey" #@param {type:"string"} replace_with = reemplazar_con replace_count = 0 search_tags_list = split_tags(search_tags) replace_with_list = split_tags(replace_with) for txt in [f for f in os.listdir(images_folder) if f.lower().endswith(".txt")]: with open(os.path.join(images_folder, txt), 'r') as f: tags = [s.strip() for s in f.read().split(",")] for rem in search_tags_list: if rem in tags: replace_count += 1 tags.remove(rem) tags.extend(replace_with_list) with open(os.path.join(images_folder, txt), 'w') as f: f.write(", ".join(tags)) if search_tags: print("\n⚡️ ¡Aaaar! Hemos hecho", replace_count, "reemplazos en los tesoros de los archivos. ¡Los antiguos tags han sido saqueados y los nuevos botines han sido añadidos!") print("\n🏴☠️ ¡Listo para zarpar en busca de más aventuras, valiente pirata! ¡Que los vientos favorables te guíen hacia tesoros sin fin!")Ajusta el balance: Encuentra el equilibrio adecuado al eliminar las etiquetas. Recuerda mantener aquellas que son distintivas y relevantes para tus imágenes, pero elimina las que no agregan valor o generan confusión.
El pruning de tags es especialmente útil cuando deseas enfocar el etiquetado en características específicas y evitar la proliferación de etiquetas innecesarias. Sin embargo, ten en cuenta que eliminar demasiadas etiquetas puede limitar la capacidad de tu modelo para reconocer ciertas características importantes.
🏴☠️ Cuándo Usar Triggers y Pruning de Tags
Ahora que conoces estas poderosas técnicas, es importante comprender cuándo es adecuado utilizarlas y cuándo es mejor evitarlas. Aquí tienes algunas pautas para ayudarte a tomar decisiones informadas:
✅ Utiliza Triggers cuando:
Deseas asignar etiquetas específicas y controlar la precisión del etiquetado.
Tienes palabras clave o frases distintivas que te permiten identificar características particulares en tus imágenes.
❌ Evita Triggers cuando:
Las palabras clave son demasiado generales y pueden generar resultados imprecisos o confusos.
No tienes palabras clave o frases distintivas que te ayuden a activar etiquetas específicas.
✅ Utiliza Pruning de Tags cuando:
Deseas reducir la cantidad de etiquetas asignadas y enfocarte en características más relevantes y distintivas.
Identificas etiquetas redundantes que no aportan información adicional o que generan variaciones no deseadas.
❌ Evita Pruning de Tags cuando:
Eliminar etiquetas puede comprometer la capacidad de tu modelo para reconocer características importantes.
No identificas etiquetas redundantes o no tienes claridad sobre cuáles son las características más relevantes en tus imágenes.
Recuerda que el uso adecuado de triggers y pruning de tags requiere un análisis cuidadoso de tus datos y una comprensión profunda de tus objetivos de etiquetado. Experimenta, ajusta y encuentra el equilibrio perfecto para navegar hacia resultados precisos y significativos.
~~~~~~~~~~~~
Técnicas de etiquetados:
En los capítulos anteriores, exploramos la importancia del etiquetado de personajes y estilos en modelos de inteligencia artificial (IA). Ahora profundizaremos en nuevos conocimientos y enfoques relacionados con el etiquetado de información. Examinaremos cómo el etiquetado puede variar según el tipo de datos y cómo utilizar técnicas avanzadas puede mejorar la precisión y la eficiencia del etiquetado.
Etiquetado basado en metadatos:
Además de etiquetar directamente los elementos visuales en una imagen, también es posible utilizar metadatos para etiquetar información adicional. Los metadatos pueden incluir detalles sobre la ubicación geográfica, la fecha de creación, la resolución de la imagen, el tipo de cámara utilizado, entre otros. Estos metadatos proporcionan un contexto adicional que puede ser útil para la generación de imágenes o la organización de conjuntos de datos.
Etiquetado activo:
El etiquetado activo es un enfoque en el cual el modelo de IA participa activamente en el proceso de etiquetado. En lugar de etiquetar manualmente todas las imágenes, el modelo puede realizar predicciones iniciales y solicitar la confirmación o corrección del etiquetado humano. Esto puede ahorrar tiempo y esfuerzo en grandes conjuntos de datos, ya que el modelo aprende a medida que se etiquetan más ejemplos. Generalmente no se usa en SD, no obstante usamos una variante de esta idea al utilizar los programas para targetiar de forma automática.
Etiquetado colaborativo:
El etiquetado colaborativo involucra a múltiples etiquetadores humanos en el proceso. Cada etiquetador puede tener diferentes perspectivas y conocimientos, lo que enriquece la diversidad y la calidad de las etiquetas. Además, el etiquetado colaborativo puede ayudar a abordar posibles sesgos o errores individuales, ya que se obtiene una visión más equilibrada y consensuada. Lógicamente que esta opción nunca la veremos para nuestros trabajos hobistas, pero para trabajos profesionales la opción siempre esta. [sobre todo si queremos mejorar los softwares de etiquetados ya existentes con nuevos datos mas fiables]
Etiquetado débil o etiquetado distante:
El etiquetado débil implica etiquetar información a nivel de imagen en lugar de etiquetar objetos o elementos específicos en la imagen. Esto puede ser útil cuando no se dispone de etiquetas precisas o cuando el etiquetado a nivel de objeto es costoso o consume mucho tiempo. El etiquetado débil permite generar modelos de IA más rápidos y escalables, aunque con una menor granularidad en las etiquetas. [Suele ser muy útil para generar conceptos, estilos, o objetos fotorealistas en donde no querés tanta influencia por parte de los tags]
Transferencia de conocimiento y etiquetado de dominio cruzado:
La transferencia de conocimiento se refiere al uso de etiquetas de un dominio o conjunto de datos existente para mejorar el etiquetado en un nuevo dominio o conjunto de datos. Esto permite aprovechar el conocimiento previo y las etiquetas disponibles para acelerar y mejorar el proceso de etiquetado en nuevos escenarios. [Por ejemplo usar los tags dados por la comunidad de rule34 para las imágenes de esa fuente]
Profundizaremos aún más en los avances recientes y los desafíos asociados con el etiquetado de datos. Exploraremos nuevas técnicas, tecnologías emergentes y consideraciones éticas relacionadas con el etiquetado de información.
Aprendizaje activo y etiquetado selectivo:
El aprendizaje activo es una técnica en la que el modelo de IA selecciona de manera inteligente las instancias más informativas para etiquetar. En lugar de etiquetar aleatoriamente las imágenes, el modelo identifica las muestras que tienen mayor potencial para mejorar su rendimiento y solicita su etiquetado. Esto permite un uso más eficiente de los recursos humanos y una mejora continua del modelo a medida que se etiquetan más ejemplos relevantes. [No se usa o se usa pero no es muy popular, pero básicamente consiste en lanzar una corrida y obtener las imágenes mas nutritivas para el modelo. El uso que e visto en la practica es usando un filtro de similitud entre imágenes, hay muchísimos ya desarrollados , el programa descarta automáticamente las imagenes de poco valor y las descarta del set de base datos]
Transferencia de etiquetas y modelos preentrenados:
Los modelos preentrenados, como las redes neuronales convolucionales (CNN) entrenadas en grandes conjuntos de datos, se han convertido en una herramienta valiosa para el etiquetado de información. Estos modelos pueden transferir su conocimiento aprendido previamente a tareas de etiquetado específicas, lo que reduce la necesidad de etiquetado manual exhaustivo. La transferencia de etiquetas también permite utilizar etiquetas disponibles en otros dominios relacionados para mejorar la precisión y la eficiencia del etiquetado.
~~~~~~~~~~~~~~~~~~~
Herramienta para hacer Triggers
A continuacion presento el siguiente codigo para poder hacer Triggers a la vieja escuela, el programa permite de forma eficiente y comoda asginar tags para grandes set de datos. De ejemplo se da el siguiente utilidad: Usted descarga una base de datos en imagenes de una anime completo, en donde hay mas de 20 personajes principales y 500 imagenes, con este programa en unos pocos minutos podremos asignar a cada personaje un trigger, de esa forma se lograria crear un Lora que guarde todos los personajes de un anime y que ademas sean increiblemente facil de invocar, solo habria que escribir el Trigger el cual podria ser el nombre del personaje. El programa permite dos modos de funcionamiento, en uno de los modos de funcionamiento prendido: el programa creara nuevos archivos de texto con los tags de cada imagen, en el modo apagado el programa agregara los tags a un archivo txt (previamente exitente) por ejemplo los creados con programas de creasion de tags automaticos. Obiamente este programa no requiere el consumo de Gpu, por lo cual recuerda concetarte a un entorno sin Gpu para tener un uso ilimitado del programa.

Modo Prendido:
Modo Apagado:

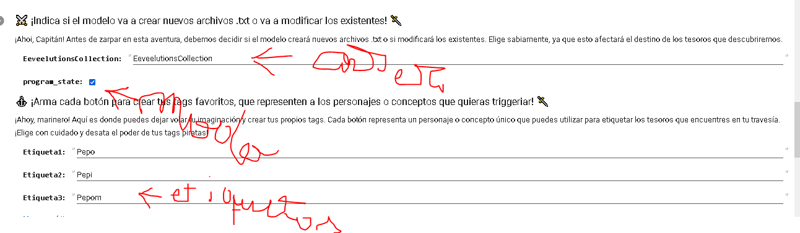
#@markdown ### ⚔️ ¡Indica si el modelo va a crear nuevos archivos .txt o va a modificar los existentes! 🗡️
#@markdown ¡Ahoi, Capitán! Antes de zarpar en esta aventura, debemos decidir si el modelo creará nuevos archivos .txt o si modificará los existentes. Elige sabiamente, ya que esto afectará el destino de los tesoros que descubriremos.
import os
from google.colab import files
from PIL import Image
from IPython.display import display, clear_output
from ipywidgets import widgets, VBox, HBox
# Ruta de la carpeta que contiene las imágenes
EeveelutionsCollection = "EeveelutionsCollection" #@param {type:"string"}
carpeta_imagenes = f"/content/drive/MyDrive/Dataset/{EeveelutionsCollection}"
# Crear una lista para almacenar las etiquetas de las imágenes
labels = []
# Estado del programa (True: prendido, False: apagado)
program_state = False #@param {type:"boolean"}
# Función para etiquetar la imagen actual
def label_image(label):
if program_state:
# Agregar la etiqueta a la lista
labels.append(label)
print(f"Etiqueta agregada: {label}")
# Ocultar la imagen etiquetada
clear_output(wait=True)
# Cargar la siguiente imagen
load_next_image()
else:
# Modo apagado, guardar la etiqueta en un archivo de texto existente
save_label_to_existing_file(label)
#@markdown ### ⚓️ ¡Arma cada botón para crear tus tags favoritos, que representen a los personajes o conceptos que quieras triggeriar! 🗡️
#@markdown ¡Ahoy, marinero! Aquí es donde puedes dejar volar tu imaginación y crear tus propios tags. Cada botón representa un personaje o concepto único que puedes utilizar para etiquetar los tesoros que encuentres en tu travesía. ¡Elige con cuidado y desata el poder de tus tags piratas!
# Función para guardar la etiqueta en un archivo de texto existente
def save_label_to_existing_file(label):
if current_image <= len(images):
image_path = images[current_image - 1]
image_filename = os.path.basename(image_path)
txt_filename = os.path.splitext(image_filename)[0] + ".txt"
txt_filepath = os.path.join(carpeta_imagenes, txt_filename)
if os.path.exists(txt_filepath):
# El archivo de texto existe, agregar la etiqueta
with open(txt_filepath, "r") as f:
content = f.read().strip()
if content:
content += ", " + label
else:
content += label
with open(txt_filepath, "w") as f:
f.write(content)
print(f"Etiqueta agregada al archivo existente: {txt_filename}")
else:
print(f"No existe un archivo de texto para la imagen: {image_filename}")
# Cargar la siguiente imagen
clear_output(wait=True)
load_next_image()
# Función para cargar la siguiente imagen
def load_next_image():
global current_image, buttons_layout
# Verificar si quedan imágenes por etiquetar
if current_image < len(images):
# Cargar la imagen actual
image_path = images[current_image]
image = Image.open(image_path).resize((200, 200))
# Mostrar la imagen utilizando el widget de IPython.display
display(image)
current_image += 1
# Imprimir el contador de imágenes restantes
print(f"Imágenes restantes: {len(images) - current_image}")
# Actualizar los botones
display(buttons_layout)
else:
# Se han etiquetado todas las imágenes
if program_state:
# Modo prendido, guardar las etiquetas en nuevos archivos de texto
save_labels()
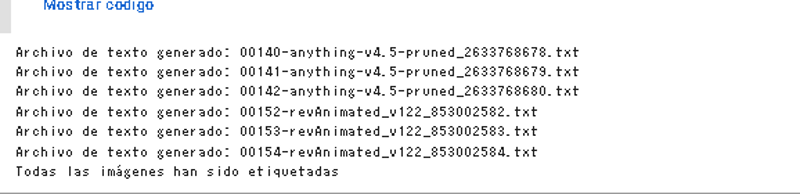
print("Todas las imágenes han sido etiquetadas")
# Función para guardar las etiquetas en nuevos archivos de texto
def save_labels():
for i, label in enumerate(labels):
image_path = images[i]
image_filename = os.path.basename(image_path)
txt_filename = os.path.splitext(image_filename)[0] + ".txt"
txt_filepath = os.path.join(carpeta_imagenes, txt_filename)
with open(txt_filepath, "w") as f:
f.write(label)
print(f"Archivo de texto generado: {txt_filename}")
# Obtener la lista de imágenes en la carpeta
images = [os.path.join(carpeta_imagenes, filename) for filename in os.listdir(carpeta_imagenes) if filename.endswith(".jpg") or filename.endswith(".png")]
# Inicializar variables
current_image = 0
buttons_layout = None
# Crear botones para las etiquetas (Para cerar otro botton agrege otro mas, recuerde que si o si debe asignar un tag a cada imagen, pero tambien recuerde que puede eliminar un tag con otras herramientas)
Etiqueta1 = "Pepo" #@param {type:"string"}
Etiqueta2 = "Pepi" #@param {type:"string"}
Etiqueta3 = "Pepom" #@param {type:"string"}
button1 = widgets.Button(description= Etiqueta1 )
button1.on_click(lambda x: label_image(Etiqueta1 ))
button2 = widgets.Button(description= Etiqueta2)
button2.on_click(lambda x: label_image( Etiqueta2))
button3 = widgets.Button(description= Etiqueta3)
button3.on_click(lambda x: label_image(Etiqueta3))
# Crear la disposición horizontal de los botones (Si crea otro botton verfique esto)
buttons_layout = HBox([button1, button2, button3])
# Cargar la primera imagen
load_next_image()
Ahora tenemos las imagenes etiquetadas:
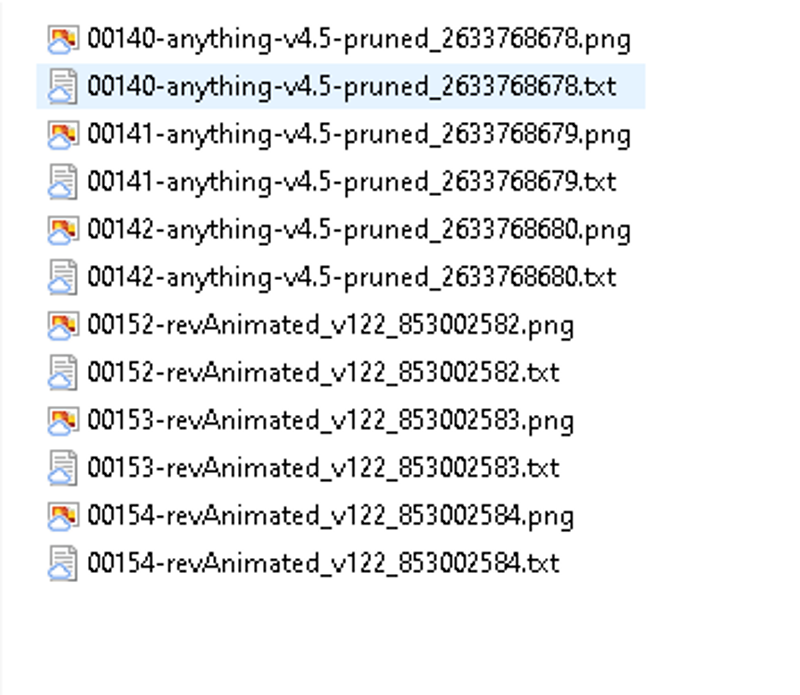
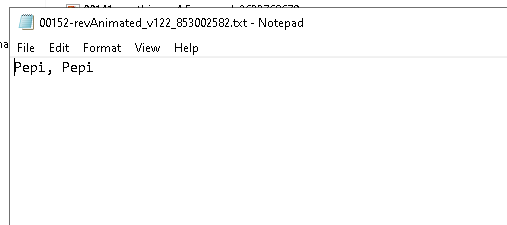
Ahora solo falta un detalle, generalmente el modo mas frecuente de trabajar es usando el modo apagado en donde usamos otro programa para clavar tags automaticos y luego ejecutamos el codigo para crear los triggers y en general estos triggers seran las palabras claves principales. No obstante el programa acomoda el ultimo tag agregado en la ultima ilera del tag y en general muchos codigos de maching learning mandan al primer tag como principal, por lo tanto se precenta el siguiente codigo, que manda el ultimo tag al primer lugar para todos los archivos de texto. (Tarda unos segundos largos en sicronizarse, no deseperen)
import os
#@markdown ### ⚔️ ¡Ordena a los borrachos! 🗡️
#@markdown 🏴☠️ **Ruta de la Carpeta de los Tesoros**: ¡Ingresa aquí la ruta de la carpeta que contiene los archivos a ordenar! ⚔️🏴☠️
# Ruta de la carpeta que contiene los archivos de texto
EeveelutionsCollection = "EeveelutionsCollection" #@param {type:"string"}
carpeta_txt = f"/content/drive/MyDrive/Dataset/{EeveelutionsCollection}"
# Obtener la lista de archivos de texto en la carpeta
txt_files = [os.path.join(carpeta_txt, filename) for filename in os.listdir(carpeta_txt) if filename.endswith(".txt")]
# Reordenar las etiquetas en cada archivo de texto
for txt_file in txt_files:
with open(txt_file, "r") as f:
content = f.read().strip()
if content:
# Obtener las etiquetas existentes y convertirlas en una lista
existing_labels = content.split(", ")
# Revertir el orden de las etiquetas
reversed_labels = existing_labels[::-1]
# Convertir la lista en una cadena de texto nuevamente
reversed_content = ", ".join(reversed_labels)
# Guardar el contenido con las etiquetas reordenadas
with open(txt_file, "w") as f:
f.write(reversed_content)
print("¡Los borrachos han sido ordenados como un verdadero pirata! ⚓️🏴☠️")~~~~~~~~~~~~~~~~A nivel empresa:
Consideraciones éticas y equidad en el etiquetado:
El etiquetado de información puede presentar desafíos éticos, especialmente en términos de sesgos y equidad. Los conjuntos de datos etiquetados pueden reflejar sesgos sociales existentes y perpetuar desigualdades en la generación de imágenes. Es fundamental abordar estos sesgos y garantizar la inclusión y representación equitativa en el etiquetado de información. Las prácticas de etiquetado colaborativo y la diversidad de los equipos de etiquetado pueden ayudar a mitigar estos problemas y promover la equidad en los resultados generados por los modelos de IA. [Ende, tené cuidado de no ser tan nabo de agrupar a los latinos con un determinado color de piel o ojos para tu modelo o sino podrías comerte terrible despido si esa información sale a la luz]
Privacidad y protección de datos:
El etiquetado de información implica el manejo de datos sensibles, como imágenes personales o información confidencial. Es crucial garantizar la privacidad y la protección de datos durante todo el proceso de etiquetado. Esto implica implementar medidas de seguridad adecuadas, como el anonimato de los datos y el consentimiento informado de los individuos cuyas imágenes se utilizan en el etiquetado. Además, es esencial cumplir con las regulaciones de protección de datos y garantizar la confidencialidad de la información. [Lógicamente los hobistas no hacemos esto, pero en principio recordá que el deepfake va a generar varios problemas en el futuro, por lo que enfáticamente es mejor evitarlo]
~~~~~~~~~~~~~~
Etiquetado automático y la eliminación de imágenes :
A continuación, me centraré en el proceso de etiquetado automático y la eliminación de imágenes con etiquetas incorrectas:
El etiquetado automático de imágenes es una técnica utilizada para asignar etiquetas a las imágenes de manera eficiente utilizando algoritmos de aprendizaje automático y procesamiento de imágenes. Sin embargo, es común que se produzcan errores en el etiquetado automático, ya sea por la falta de contexto semántico o por la variabilidad en las imágenes.
Después de etiquetar automáticamente las imágenes, es crucial verificar la precisión de las etiquetas generadas. Una estrategia útil es revisar una muestra aleatoria de imágenes etiquetadas y comparar las etiquetas generadas con las etiquetas esperadas. Durante este proceso de verificación, se pueden identificar etiquetas incorrectas o inconsistentes las cuales con frecuencia se repiten, dado que el software que realiza la etiquetan esta asignando mal uno de los atributos de la imagen.
Para simplificar esta tarea es recomendable utilizar herramientas de visualización de datos que permitan examinar las imágenes y las etiquetas de manera interactiva. Estas herramientas facilitan la detección de errores y la toma de decisiones basada en la visualización de los datos. Al visualizar las imágenes y las etiquetas, es posible identificar fácilmente aquellas imágenes que tienen etiquetas incorrectas o inconsistentes.
Una vez que se han verificado las etiquetas y se han identificado las imágenes con etiquetas incorrectas, es importante considerar la eliminación de dichas imágenes del conjunto de datos. Esta acción es necesaria para garantizar que el conjunto de datos utilizado en el entrenamiento de modelos de aprendizaje automático sea de alta calidad y esté libre de ruido o sesgos.
Por supuesto que la opción de eliminación de imágenes es la más radical, pero con frecuencia, en el uso de stable diffusion, la disposición de las imágenes y la obtención de muestras es ridículamente sencilla, por lo cual el problema del entrenamiento (con frecuencia) está en la calidad de las imágenes y no en su cantidad. En este contexto, los tags desempeñan un papel crucial, ya que nos permiten identificar aquellas imágenes que no alcanzan el nivel de calidad suficiente para ser reconocidas por el software generador de etiquetas. Por lo tanto, podemos suponer a groso modo que estas imágenes tampoco serán reconocidas adecuadamente por el software utilizado durante el proceso de entrenamiento.
Es importante destacar que al eliminar las imágenes con etiquetas incorrectas, estamos asegurando la integridad y confiabilidad de nuestro conjunto de datos. Al eliminar estas imágenes problemáticas, evitamos que influyan negativamente en el proceso de entrenamiento y, en consecuencia, en el rendimiento y la precisión del modelo final. Es fundamental abordar este paso con cautela y considerar cuidadosamente las implicaciones de la eliminación de imágenes.
A continuacion se proporciona el siguiente código para realizar esta tarea en colab, suponiendo que las imágenes (png o jpg) y los archivos de texto tienen el mismo nombre:
#@markdown ### ⚔️ ¡Elimina los tesoros malditos! 🗡️💣🏴☠️
#@markdown ¡Argh, marinero! Nos enfrentamos a una tarea peligrosa: encontrar y eliminar los tesoros malditos que contienen un tag prohibido. ¡Prepárate para hacer justicia pirata y deshacerte de esas imágenes y archivos txt corruptos! Aquí tienes el elemento clave para completar esta misión:
#@markdown 🏴☠️ **Tag Maldito**: ¡Ingresa aquí el tag que debe ser erradicado! Este tag ha corrompido los tesoros y debe ser destruido. Por ejemplo, "maldición", "prohibido", "malvado"...
tag_maldito = "Pon-aca-el-tag" #@param {type:"string"}
# Tag que se desea buscar y eliminar
# Recorrer todos los archivos y carpetas en la ruta
for root, dirs, files in os.walk(tags_folder):
for file_name in files:
if file_name.endswith(".txt"):
txt_file_path = os.path.join(root, file_name)
# Verificar si el archivo .txt contiene el tag buscado
with open(txt_file_path, 'r') as f:
tags = [s.strip() for s in f.read().split(",")]
if tag_buscado in tags:
# Eliminar la imagen correspondiente (jpg o png)
base_name = os.path.splitext(file_name)[0]
image_extensions = (".jpg", ".png")
for extension in image_extensions:
image_path = os.path.join(root, base_name + extension)
if os.path.exists(image_path):
os.remove(image_path)
print(f"Imagen eliminada: {base_name + extension}")
break # Solo se elimina una imagen si se encuentra
# Eliminar el archivo .txt
os.remove(txt_file_path)
print(f"Archivo eliminado: {file_name}")~~~~~~~~~~~~~~
Aislar las imágenes con un tag específico
Además de la revisión y eliminación de imágenes con etiquetas incorrectas, otra estrategia útil es aislar del conjunto de datos aquellas imágenes que tengan un determinado tag en particular. Esto permite analizarlas en detalle en el futuro y comprender por qué estas imágenes están generando esas etiquetas específicas.
Al aislar las imágenes con un tag específico, se crea un subconjunto más pequeño y enfocado que se puede utilizar para investigar y comprender mejor las características o patrones que llevan a la generación de ese tag en particular. Esto puede proporcionar información valiosa sobre el rendimiento del modelo de etiquetado automático y ayudar a identificar posibles errores o áreas de mejora.
Una vez que se ha identificado el subconjunto de imágenes con el tag de interés, se puede realizar un análisis más detallado. Esto puede incluir la revisión visual de las imágenes, la comparación de las etiquetas generadas con las características visuales presentes en las imágenes y la búsqueda de posibles causas o factores que podrían haber llevado a la generación del tag en cuestión.
Este enfoque de análisis detallado puede ayudar a mejorar el modelo de etiquetado automático al identificar posibles fuentes de error, como la falta de variabilidad en las imágenes etiquetadas o la presencia de características visuales ambiguas que podrían confundir al algoritmo de etiquetado automático.
Además, el análisis detallado de las imágenes con un tag específico puede proporcionar información adicional para refinar las reglas o los modelos utilizados en el proceso de etiquetado automático. Por ejemplo, si se encuentra que ciertas características visuales son consistentes en las imágenes con ese tag, se pueden incorporar criterios adicionales o ajustar los parámetros del modelo para mejorar la precisión y la consistencia en la generación de etiquetas.
A continuacion se proporciona el siguiente código para realizar esta tarea en colab, el codigo cambiara el nombre de las imagenes y los archivos de texto con un tag particular de forma de que sean facilmente identificables. Considerar que al cambiar el nombre del archivo puede ser necerario reiniciar colab para sincronizarlo con el drive.
#@markdown ### ⚡️ Cambio de Imágenes - ¡Despliega las velas y modifica los tesoros visuales!
#@markdown ¡Ahoy, valientes corsarios! Llegó el momento de hacer cambios audaces en nuestras imágenes. Desplegaremos nuestras velas y nos adentraremos en el vasto océano de los archivos gráficos. ¡Preparaos para cambiar los nombres de las imágenes y desatar todo su potencial pirata! Usaremos el poderoso código de abordaje para renombrar los tesoros visuales. ¡Que el viento sople a nuestro favor y la fortuna nos acompañe!
import os
import hashlib
import time
tags_folder = "/content/drive/MyDrive/Dataset/EeveelutionsCollection" # Ruta de la carpeta donde se guardan las imágenes
#@markdown 🏴☠️ **Tag de la Imagen**: ¡Ingresa aquí el nombre del tesoro que buscas! Por ejemplo, "calavera", "tesoro", "espada"...
Tags_Buscados = "Monkey" #@param {type:"string"}
#@markdown 📸 **Nombre de la Imagen**: ¡Dale un nombre único a tu tesoro! Ponle un nombre valiente y emocionante que refleje su esencia pirata.
new_file_name = "Cambio" #@param {type:"string"}
# Generar el contador único utilizando la función de hash
timestamp = str(time.time()).encode('utf-8')
hash_object = hashlib.md5(timestamp)
rename_count = int(hash_object.hexdigest(), 16) % (10**8)
for file_name in os.listdir(tags_folder):
if file_name.endswith(".txt"):
with open(os.path.join(tags_folder, file_name), 'r') as f:
tags = [s.strip() for s in f.read().split(",")]
if Tags_Buscados in tags:
new_file_path = os.path.join(tags_folder, f"{new_file_name} {rename_count}")
os.rename(os.path.join(tags_folder, file_name), new_file_path)
print(f"¡Arrr! El archivo {file_name} ha sido renombrado como {new_file_name} {rename_count}. ¡Tesoro asegurado!")
image_name = os.path.splitext(file_name)[0] + ".jpg"
image_path = os.path.join(tags_folder, image_name)
new_image_path = os.path.join(tags_folder, f"{new_file_name} {rename_count}.jpg")
if os.path.exists(image_path):
os.rename(image_path, new_image_path)
print(f"¡Arrr! La imagen {image_name} ha sido renombrada como {new_file_name} {rename_count}.jpg. ¡Tesoro asegurado!")
else:
image_name = os.path.splitext(file_name)[0] + ".png"
image_path = os.path.join(tags_folder, image_name)
new_image_path = os.path.join(tags_folder, f"{new_file_name} {rename_count}.png")
if os.path.exists(image_path):
os.rename(image_path, new_image_path)
print(f"¡Arrr! La imagen {image_name} ha sido renombrada como {new_file_name} {rename_count}.png. ¡Tesoro asegurado!")
else:
print(f"⚠️ La imagen {image_name} no existe. ¡Continuemos en busca de nuevos tesoros!")
rename_count += 1
# Actualizar la variable images_folder con los nuevos nombres de archivo
images_folder = os.path.join("/ruta/de/la/carpeta", project_name) # Reemplaza con la ruta correcta
~~~~~~~~~~~~~~
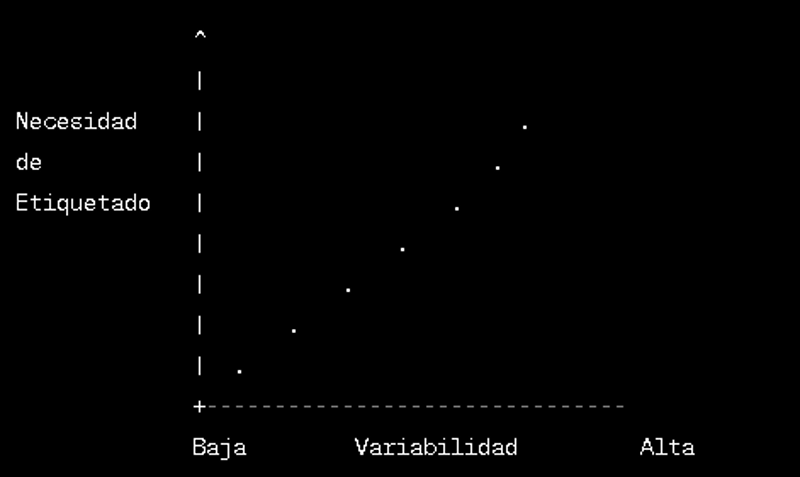
Alta varianza
En este capítulo, exploraremos la importancia de utilizar tags o etiquetas en conjuntos de datos con una alta varianza. Cuando los conjuntos de datos contienen una amplia diversidad de imágenes, el etiquetado adecuado se vuelve fundamental para garantizar la calidad y coherencia de los resultados generados por los modelos de inteligencia artificial. Analizaremos por qué el uso de tags es útil en este contexto y cómo contribuye a mejorar la comprensión y generación de imágenes por parte de los modelos de IA.
Organización y categorización de la información:
Los tags permiten organizar y categorizar las imágenes en conjuntos de datos con alta varianza. Al asignar etiquetas descriptivas a cada imagen, es posible clasificarlas en diferentes grupos o categorías en función de sus características visuales, contenido o contexto. Esto facilita la búsqueda y recuperación de imágenes específicas dentro del conjunto de datos y proporciona una estructura ordenada que ayuda a los modelos de IA a comprender y navegar por la información de manera más efectiva.
Contextualización y comprensión más precisa:
En conjuntos de datos con alta varianza, las etiquetas desempeñan un papel fundamental al proporcionar contexto y detalles adicionales sobre las imágenes. Al etiquetar características específicas, como objetos, colores, poses o estilos, se brinda información adicional que ayuda a los modelos de IA a comprender y representar de manera más precisa las imágenes. Esto les permite generar resultados más coherentes y relevantes al tener en cuenta las características etiquetadas durante el proceso de generación.
Mejora en la capacidad de generalización:
Los tags también contribuyen a mejorar la capacidad de generalización de los modelos de IA en conjuntos de datos con alta varianza. Al etiquetar imágenes con características comunes o representativas, los modelos pueden aprender patrones más generales y capturar la diversidad presente en el conjunto de datos. Esto les permite generar imágenes que se ajusten a diferentes variaciones y estilos, mejorando así su capacidad para adaptarse a nuevas imágenes no vistas previamente.
Selección y control de atributos específicos:
En conjuntos de datos con alta varianza, los tags permiten seleccionar y controlar atributos específicos que se desean destacar o enfatizar en las imágenes generadas. Al etiquetar características específicas, se puede influir en la generación de imágenes con esos atributos particulares presentes. Esto proporciona un mayor control sobre los resultados y permite a los usuarios obtener imágenes que cumplan con criterios específicos y deseados.
Enfoque en áreas de interés y eliminación de sesgos:
Al utilizar tags en conjuntos de datos con alta varianza, es posible centrarse en áreas de interés específicas y eliminar sesgos no deseados. Al etiquetar características relevantes y evitar etiquetas que generen sesgos indeseados, se puede mejorar la calidad y equidad de los resultados generados por los modelos de IA. Esto promueve una representación más justa y precisa de la diversidad presente en el conjunto de datos, evitando la generación de imágenes sesgadas o discriminatorias.
El uso de tags en conjuntos de datos con alta varianza es esencial para organizar, contextualizar y mejorar la comprensión de las imágenes por parte de los modelos de inteligencia artificial. Los tags permiten una mejor categorización, contextualización y generación de imágenes al proporcionar información descriptiva y relevante. Además, los tags ofrecen un mayor control sobre los atributos generados y ayudan a eliminar sesgos no deseados. En conjunto, el etiquetado adecuado mejora la calidad y coherencia de los resultados generados por los modelos de IA en conjuntos de datos con una alta diversidad visual.
Pese a ello, cabe destacar que a medida que aumenta la variabilidad en un conjunto de datos, se vuelve más difícil para el modelo de IA aprender y generalizar correctamente sin una etiquetación adecuada.
Por otro lado, en casos donde hay poca variabilidad y similitud entre las imágenes, la etiquetación puede generar desafíos adicionales. En estos casos, existe el riesgo de que el modelo se sobreajuste a los patrones específicos presentes en el conjunto de datos y tenga dificultades para generalizar a nuevos ejemplos fuera de ese contexto limitado.
Es importante tener en cuenta que el etiquetado debe realizarse con cuidado y considerando el equilibrio entre la variabilidad de los datos y la necesidad de etiquetas precisas. No obstante como regla general y siguiendo lo aprendido a través de la continua creación de modelos recomiendo imperiosamente crear un etiquetado abundante para set de datos pocos uniformes de modo de poder aislar las irregularidades del concepto base que buscamos capturar en nuestro modelo.
~~~~~~~~~~~~~
Poca varianza
En este capítulo, exploraremos los desafíos y problemas específicos que surgen al etiquetar imágenes en conjuntos de datos con poca varianza y alta similitud entre las imágenes. A diferencia de los conjuntos de datos con alta diversidad visual, estos conjuntos pueden presentar dificultades adicionales debido a la falta de variación en los atributos visuales. Analizaremos los problemas comunes asociados con este tipo de conjuntos de datos y las estrategias para abordarlos de manera efectiva.
Dificultad para asignar etiquetas distintivas:
En conjuntos de datos con poca varianza y alta similitud, puede ser difícil asignar etiquetas distintivas a las imágenes. Las características visuales pueden ser casi idénticas entre las imágenes, lo que dificulta la diferenciación y clasificación precisa. Esto puede generar ambigüedad y confusiones en el etiquetado, lo que afecta la calidad y la utilidad de los datos etiquetados.
Riesgo de etiquetado incorrecto:
La similitud entre las imágenes en conjuntos de datos con poca varianza aumenta el riesgo de etiquetado incorrecto. Los etiquetadores automáticos pueden confundirse o asignar etiquetas incorrectas debido a la falta de diferencias visuales significativas. Esto puede generar datos etiquetados inexactos y sesgar el entrenamiento de los modelos de IA, lo que resulta en resultados poco confiables y de baja calidad.
Escasa diversidad de atributos etiquetados:
La falta de variación en los atributos visuales de las imágenes puede resultar en una escasa diversidad de etiquetas. Los conjuntos de datos con poca varianza tienden a tener una cantidad limitada de atributos distintivos, lo que dificulta la representación de la diversidad presente en el mundo real. Esto puede afectar negativamente la capacidad de los modelos de IA para generalizar y adaptarse a nuevas imágenes fuera del conjunto de datos específico.
Necesidad de etiquetado más detallado:
Debido a la falta de varianza, puede ser necesario un etiquetado más detallado y preciso para capturar las sutilezas entre las imágenes. Las diferencias sutiles en las características visuales pueden tener un impacto significativo en la interpretación y generación de imágenes por parte de los modelos de IA.
El etiquetado de imágenes en conjuntos de datos con poca varianza y alta similitud presenta desafíos únicos que deben abordarse para garantizar la calidad y utilidad de los datos etiquetados. Es fundamental aplicar enfoques cuidadosos y estratégicos para asignar etiquetas precisas y capturar las diferencias sutiles entre las imágenes.
A continuación formularé una fórmula matemática relacionada con el etiquetado de imágenes en conjuntos de datos con poca varianza y alta similitud.
Fórmula: Σ(𝑝𝑖 × log(1/𝑝𝑖))
Explicación:
Σ representa la suma de los términos, considerando cada termino como las respectivas imágenes que conforman un set de datos.
𝑝𝑖 representa la probabilidad de asignar incorrectamente una etiqueta a una imagen en el conjunto de datos.
log(1/𝑝𝑖) es el logaritmo en base 10 de la inversa de la probabilidad 𝑝𝑖.
Esta fórmula podría utilizarse como medida de la pérdida o el error en el etiquetado de imágenes en conjuntos de datos con poca varianza. Cuanto mayor sea la probabilidad de asignar incorrectamente una etiqueta a una imagen, mayor será la contribución a la pérdida total.
Claramente la misma tiene poca importancia en el etiquetado de baja escala, pero para el etiquetado de set de datos con una gran cantidad de imágenes realizado de forma automática mediante software la formula puede a ayudar a detectar de forma rápida que tan probable es que el error generado por nuestras etiquetas sea mas grande que el aporte que dan al modelo.
~~~~~~~~~~~~~~~
Herramientas automáticas en el Etiquetado de Imágenes
En el emocionante mundo del etiquetado de imágenes, contar con herramientas efectivas y eficientes puede marcar la diferencia en la calidad y la productividad de tu proyecto. Afortunadamente, existen diversas herramientas disponibles que facilitan el proceso de etiquetado y anotación de imágenes, ofreciendo funcionalidades y características únicas. En este capítulo, exploraremos algunas de estas herramientas, centrándonos en dos destacadas: Waifu Diffusion y BLIP.
Estas herramientas han ganado popularidad debido a su capacidad para etiquetar imágenes de manera precisa y eficiente, incluso en entornos virtuales sin GPU. Aunque el procesamiento puede tomar más tiempo en comparación con el uso de GPU, siguen siendo opciones viables para conjuntos de datos con un número reducido de imágenes.
Es importante tener en cuenta que, si bien estas herramientas son capaces de ejecutarse en entornos sin GPU, el tiempo de procesamiento puede ser más prolongado en comparación con entornos con GPU activada. Tomando como ejemplo Waifu Diffusion, que procesa 100 imágenes en aproximadamente 14 minutos sin GPU, podemos observar que el tiempo de etiquetado puede extenderse en comparación con un entorno con GPU en donde tomaría a lo máximo 2 minutos. Por otro lado, BLIP, aunque tarda un poco más: alrededor de media hora sin GPU para procesar 100 imágenes, sigue siendo una opción viable para etiquetar imágenes en entornos gratuitos.
La razón detrás del tiempo de ejecución prolongado en entornos sin GPU se debe a que el procesamiento de imágenes requiere una gran cantidad de operaciones computacionales intensivas, como el análisis de características visuales y la clasificación de etiquetas. En entornos sin GPU, estas operaciones se ejecutan utilizando la potencia de procesamiento de la CPU, que es generalmente inferior a la de una GPU dedicada.
A continuación explicare las herramientas y donde encontrarlas:
Waifu Diffusion:
Waifu Diffusion es una herramienta de etiquetado de imágenes especializada en el ámbito del anime. Se basa en la arquitectura Swin Transformer v2 y es capaz de identificar y etiquetar varios elementos en imágenes de anime, como personajes, estilos, características físicas y poses. Puedes encontrar el modelo específico en el siguiente enlace: Waifu Diffusion ( Hugging Face )
Ejemplo de etiquetas (tags): 1girl, 1boy, day.
En este ejemplo, las etiquetas indican que hay una chica, un chico y la escena tiene lugar durante el día. Estas etiquetas proporcionan información útil sobre los elementos presentes en la imagen y pueden ser utilizadas para clasificar y organizar el conjunto de datos de imágenes de anime.
BLIP:
BLIP (Blind Light Image Parser) es una herramienta de etiquetado de imágenes diseñada para el fotorealismo. Se enfoca en generar subtítulos o captions descriptivos para las imágenes, lo que ayuda a comprender rápidamente el contenido visual de las mismas. Puedes acceder a BLIP en el siguiente enlace: BLIP ( Hugging Face )
Ejemplo de subtítulo (caption): "big house with a man sleeping in the door".
En este ejemplo, el subtítulo describe la imagen de una casa grande con un hombre durmiendo en la puerta. Estos subtítulos descriptivos pueden ser utilizados para mejorar la accesibilidad de las imágenes y para tareas de generación de texto relacionadas con imágenes.
Las herramientas de etiquetado de imágenes, como Waifu Diffusion y BLIP, ofrecen soluciones efectivas para el etiquetado y la anotación de imágenes en diferentes dominios. Aunque el procesamiento puede llevar más tiempo en entornos sin GPU, su capacidad para generar etiquetas y subtítulos precisos las convierte en opciones valiosas para conjuntos de datos con un número reducido de imágenes.
Es importante tener en cuenta que cada herramienta tiene sus propias características y funcionalidades específicas. La elección de la herramienta adecuada dependerá de los requisitos y las necesidades de tu proyecto. Sin embargo, tanto Waifu Diffusion como BLIP brindan una experiencia de etiquet
Ejecutar en Colab un etiquetador automatico
Creada apartir del codigo de hollowstrawberry , los invito a probar resumidamente lo aprendido usando el siguiente colab:
[Recordar que te va a pedir crear una copia en tu drive, cosa importante]
Se recuerda que no es necesario usar Gpu para realizar estas tareas, por lo que no hay absolutamente ningún limite de uso:
Tutorial de como cambiar los entornos de ejecución para no tener limites:

Recordad que este viaje es solo el comienzo de una gran aventura en busca de los tesoros visuales más asombrosos. Hoy hemos explorado dos herramientas poderosas, Waifu Diffusion y BLIP, que nos han permitido desvelar los secretos ocultos en nuestras imágenes.
Pero el océano de la inteligencia artificial es vasto y lleno de posibilidades. Invito a todos los miembros de esta intrépida comunidad a seguir explorando, descubriendo nuevas herramientas y creando colaboraciones para enriquecer nuestro arsenal de etiquetado automático.
¡Imaginad todas las herramientas que podríamos reunir, todos los tesoros que podríamos desenterrar! Juntos, podemos elevar nuestras habilidades y hacer de nuestros Loras una auténtica leyenda en los mares de la inteligencia artificial.
Que los vientos favorables os guíen en vuestros futuros proyectos, ¡y que los tesoros que descubráis iluminen vuestro camino! ¡Hasta la próxima travesía, valientes piratas! ⚓️🏴☠️💎
Financial assistance: Hello everyone!This is Tomas Agilar speaking, and I'm thrilled to have the opportunity to share my work and passion with all of you. If you enjoy what I do and would like to support me, there are a few ways you can do so:
Ko-fi (Dead)