

Introduction
Hi, welcome to this article that is going to be read by about ~10 people at most.
This page will try to tell you about wonders of regularization, why it's best thing that ever happened to neural networks and how to improve it in your lorers.
This article is a way for me to offset questions that i get a lot in discord... I really am tired of explaining basics over and over...
Also now that i checked, Civitai has a gaping hole on the spot where it should have some useful regularization articles... Guess i'll be first to actually explain them more thoroughly than just a process of doing this or that.
As you likely have noticed, i am not a professional in area, and do not claim that everything said in actual useful part down there necesserily true, but what i describe was experienced in practice.(yes, i drop literally any responsibility with this statement, kek)
But i do train loras for... A year at that point, and have trained embeddings and hypernetworks for much longer. So, if you needed something to trust me, here is your anchor.
P.S. I might use regularization and generalization interchangeably in text, you need to keep in mind what is being talked about in context.
What i mean by regularization: Process or state of model conditioning to be applicable to wide range of other concepts.
Generalization: general editability of content in question by applying it to other concepts.
Also such words as "reg", "class", "prior" can be used interchangeably, as ultimately they serve similar goal.
And i invite @Manityro to add anything he wants to this article.
DISCLAIMERS
Reg is not a checkbox that provide quality for free, and in some cases effects might be subtle. It will require a bit of effort to use, and quite a bit more of your brain power to understand it to better extent later. If you don't want to bother, just don't read further, really. Reg is double-edged sword, and if used incorrectly, will harm instead of providing benefits.
Im not using Kohya-based trainers 99% of the time, so all examples you'll see are trained with very different regularization system in place that allows me to utilize multitudes more regularization images, while in all, or most kohya-based trainers you could utilize only x1 worth of reg dataset. In trainer im using im able to do as much as needed, and usually that means im using x50. For example, if im training 50 image dataset, i usually would use 2500 reg images, instead of 50 that Kohya_ss would allow me.
Sometimes understanding me is not easy, and i often go on rambling about vaguely related stuff. Please excuse me for that.
YOU CAN'T JUST YOLO THIS. @wrench1815 tried and miserably failed.
What is regularization?
In simple terms, it's the... Behaviour, yes, i like that word. Behaviour of neural network that allows it to apply concepts to other concepts.
You are likely familiar with lots of bad, overbaked loras on Civitai that are trained on low quality and quantity data. Hardly editable, and sometimes even hardly working... Those are badly regularized models.
On other hand we could take memes, most of which are likely done by no one other than @FallenIncursio, which are meant to be utilized with wide range of characters, but most notably - Shrek. Those models are a good representation of average regularization.
Most regularized models are styles, if trained properly. They are meant to be applicable to virtually anything, be it characters, landscapes, or mix with other styles to create a unique combination.
Baseline
Majority of models are trained in a common way that most of you are familiar with.
1. You gather some amount of images, usually in range from 50 to 100
2. Let's say you are a smart boi, and you already have all captions. If not, you do good captioning yourself
3. You put it in one of many trainers that utilize Kohya scripts
4. You get yourself hopefully decent enough model
Those models are as regularized, as your datasets are. Usually not by much, have biases, and likely they introduce style bake. Style problem in particular is extremely strong in screencap models.
What is important to understand here, such model introduces strong connection to concepts and data specific to dataset used. For example, you can have too much shots from behind, and lots of images without prompting angle will be generated in some from behind variation. That also could happen due to unexpected weight overlaps on certain models and whatnot, but we're not going to discuss such cases.
What we aim to do with regularization, is to break, or at the very least loosen, those connections for data that we don't want, while keeping data that we want intact, or empowered and more editable than before.
How to regularize it?
First of all, we need to understand what we do with regularization dataset, and how to obtain one.
Setting a goal
What are we training? There are multiple categories that would benefit from reg.
Characters - Yes, reg with characters is beneficial, especially with small data. But not all characters are created equal. Furries, from experience of @Manityro are not very good with reg trained on NAI. All of characters i posted are trained with reg, except Kafka from Honkai Star Rail from cabal collab.
Concepts - Absolutely. Memes, poses, objects and other things like that are benefiting hard from reg.
As example just take any of my concept/meme loras. They are all trained with reg.
Clothing - I don't have concrete data, as i don't train much clothes, but there it is beneficial too, as it's generally same as with characters and concepts. Also can help you to take dress out of character, if 100% of your data is only single character with that particular clothing.

Owari in Elysia dress for example.(Dress is far from perfect though, and is baked a bit hard, it's my first ever clothing lora, don't judge it too much xd)

That girl. 100% of dataset was her, but lora itself is easily editable to apply to other characters, even hard baked ones.
Styles - I don't have exact conclusion on that one yet. It can be useful, but of class is closely following tagging of dataset, training is nearly halted and style becomes extremely weak. Random class doesn't do that, but im yet to determine benefits, as i didn't have time to do concrete tests on that yet.
Half-matched class did bring me benefit though, but... Let's just skip this and you will forget i ever said "half-matched class".
Multi-concept - You don't necesserily need reg for anything, especially if it's alot of concepts, as they will act as regularization dataset for each other.
That should cover most things. you could train.
But let me note just 1 more. If you are doing big dreambooth - you don't need class, as your goal is to finetune whole model. If you use dreambooth to then extract to loras - treat as common loras.
How to obtain your very own reg
You understood if you need to use it or not, or, rather, if you want to bother. Or maybe you didn't, and then i did a bad job writing that section above, oh well, what can i do now...
Anyways, This section is again going to be split in groups.
Characters, clothing, concepts - generally, you want reg to match your instance dataset with exception of trigger word(concept name, or whatever you're going to use to trigger it).
Here i must strongly emphasize, you might be used to trigger word not doing almost anything, but that's only because the way you train single concept loras, when whole dataset consistently has same tag, it doesn't learn anything specific most of the time, which makes even using it pointless. With reg this is not true, and trigger word becomes practically mandatory.
Style - you do not want to match your tags closely, or do, but not often. Random paintings in random styles will serve nicely. Or not using reg will do too, really.
Compose a list of your instance prompts(if you're not training style) excluding trigger word, and generate! You need them to be generated on the model you'll be using to train. It is good to match size of instance images(bucket size), so they are also matched in bucket size when counted, but it is likely you wont have easy way of doing it, so can ignore.
You don't need to cherrypick that data, you also don't need to hires fix it. Save yourself some nerves.
For styles just gen some random stuff, or even find reg datasets for your model on the internet.
Kohya trainers seem to not use text files alongside reg, so it's not needed.
to correct there, sd scripts can use captions as in derrian (bmaltais included cuz it just a sd scripts interface) but its not neccesarilly needed (actually helps in lots of cases without it [from testing only, not to be taken as true]) - @Shippy
NOTES ON REG GENERATION:
You do want tags like 1girl to be present when generating reg, as they provide stability to your images.
You do want captions to be quite long, similar to whole danbooru tag lines, if you were to filter out artist, meta tags, character names and character appearances. This creates a very solid base for specific, yet generalistic reg. I already have posted script to help with removing tags and whatnot.
"One things that might help make reg more stable in the "1girl" section might be mentioning location in tags like "beach, indoors, outdoors, forest, garden, city, etc etc" - @Manityro
Cheating your way out of tedium, through self-hate
Stuff above sure does sound tedious, right? You want a simple way to get as much reg as you need, right? Something that will just take your dataset, and create appropriate reg with appropriate size for each bucket to be just perfect...
I know of such thing... If you hate yourself, you'll try to use it. Go on.
https://github.com/d8ahazard/sd_dreambooth_extension
This has best class system i've seen, but will you make it out sane..?
Me and the bois love D8... You wont. Im not helping you out on that one. Im tired...
Training with reg
I can't belive you've made it this far...
I actually can't help you with lots of trainers out there in this part, but i can show you Bmaltais, and steal some screenshots from FallenIncursio from the time he used reg in Derrian. Also i'll show you D8... But you wont need that.
Bmaltais
I'll assume you already know how to train, otherwise, you wouldn't really be here.
You set folder with reg here, as you might expect:

But that's not all. Main thing that will determine how it would work is located in "Advanced" tab. Navigate there, you'll find this:

This is deceptively set to 1 as default, while in reality you want it much, much lower. In cases of bigger training can be required to be as low as 0.1
For NAI, i would suggest to start with 0.25
That value is direct multiplier of loss from reg dataset. You don't want it to be high, as you will train it like your instance, basically. We want it to pull back on concepts we don't want to change, but not overpower them and become very influential.
ADDITIONAL RESEARCH SECTION
Shippy and Fallen did their own tests on kohya-based trainers(Bmaltais and Derrian) to help me with data, this is solely their section.
SHIPPY:

It appears that using tagged(captioned) reg gives positive results with Kohya. Dampening is much stronger than without. It still messes with some things that you are training, but evidence that it actually helps is bigger.
First image is reg with tagging, second without tagging but matching repeats, and third is no tagging and 1 repeat.
All of them trained on constant to mitigate possible issues from cosine scheduler.Reworded Shippy message.
FALLENINCURSIO:
Okey it seems like i'm getting different results across all methods I've used. My Dataset is "head in Jar" mostly in futurama style. Dataset contains 29 images, set to 10 epochs, 8 repeats. Also cleaned Dataset before i started Training. Here are my settings to the different results:
1RegOn1R: 1 Reg Folder, the checkbox for reg is active, 1 repeat
1RegOn2R: 1 Reg Folder, the checkbox for reg is active, 2 repeats
1RegOff1R: 1 Reg Folder, the checkbox for reg is NOT active, 1 repeat
2RegOff1R: 2 Reg Folder, the checkbox for reg is NOT active, 1 repeat
5RegOff1R: 5 Reg Folder, the checkbox for reg is NOT active, 1 repeat
1RegOff2R: 1 Reg Folder, the checkbox for reg is NOT active, 2 repeats
Vanilla: No reg.





All of them work in some way to another (Image 1), but the difference begins, when a Char LoRA is included (Image 2, 3, 4, 5) The Style bleed without reg is def there.
Direct message snippets copy from Fallen
What can i say on that? All aligns with my experience.
Captioning tells model what it sees, which helps with attention and more precise training.
In Fallen's notes, reg does make concept a bit weaker, but strongly mitigates style bleed. This can be countered with more epochs bake, though, limited reg amount in Kohya-based trainers is not going to help with doing that.
Derrian(i think?)

Literally everything i have for you. (Fallen don't kill me for stealing your screenshot, lmao)
I never used it myself. Unlike Bmaltais, derrian does seem to use captions, so here you would need them. I don't know if prior loss is scalable in derrian.
But info that it's not used in Bmaltais comes from Shippy, so idk if it's true or not myself, but i trust him.
D8
Navigate to concepts, you'll see reg setup for each single concept you want to train.
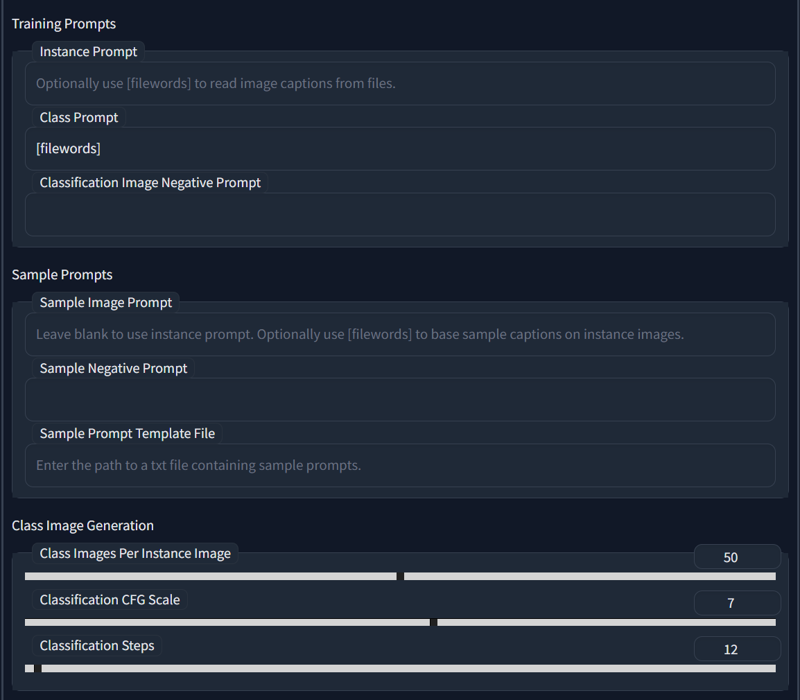
Obviously input your negative you want. That's it. They will be generated according to your dataset prompts and image size. In my particular example 50 per each image. And it will use all of them. Really easy.
Then you navigate to training settings and scroll to the bottom to modify weight
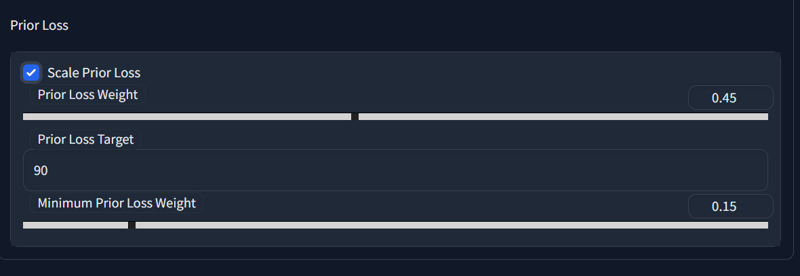
You set initial weight, target(epoch) and minimum weight that is achieved at target epoch.
Very useful controls.
Then after all that you hit train, and see how it burns in the fires of Hell how it trains, and then adjust accordingly. Or throw reg out because you don't want to bother with it after it didn't work first try. That works too.
But
Regularization is achieved not only by directly using reg datasets. Some features lead to better generalization of training through hyperparameters, but there are very few of them, like noise perturbation.
I can't tell you much about that, but if you know of such ways, please share in comments, i would love to hear about them. Especially if you also would link it with arxiv paper to read.
Not that i'll use that knowledge to do anything, but i love looking at graphs and then randomly talk about that shit, im really far from coding, so i can't utilize it, which is sadge
But why bother?
Good question. Short answer - you don't need to.
Longer answer - you don't need to, but it can lead to major improvement in your model performances in some cases. Including across checkpoints, and in combination with other models.
Regularization increases editability, lessens dataset bias and improves model compatibility with other things.
Basically, what we are trying to achieve is a very localized immitation of full checkpoint training, that uses millions, and even billions of images. We preserve prior knowledge to then have easier time editing our model.
In some cases they can extend possible training time(epoch-wise), which helps baking low data concept(<20 images).
You can also think of them as providing data to compare your dataset against, which makes it easier to pick up on details that are specific to your concept, if used correctly.
I'll provide some examples of trainings with reg, but don't expect to see something exceptional, so much different and whatnot. I don't keep examples of failed concepts that just didn't work otherwise, so i can't compare that. Or datasets were just too big for me to bother also retraining another version.
But anyway.
Here i have crazy eyes concept that i trained for work reasons. It's not supposed to be strong.

1 - no reg, ~3800 steps(50 epochs). 2 - with x25 reg, ~7500 steps(50 epochs). 3 - base.
This is an exaggerated example that i had time to retrain, in reality you wont be training that amount of steps, even with reg, for such relatively simple concept.
Despite image 2 having 2 times more steps, it deviates less from base model, while having better concept representation(i.e. eyes are a bit swirly, instead of being localized to dots). Hands are almost identical to base, etc. etc.

(not hiresd)
More apparent example, image 2 deviates much less.
In next small plot you'll be able to see how reg fights style bake:

You can see how even relatively short training based on checkpoint that is not anime leads to some style bake, which you can see in grainy image and appearance of much more bold lineart, which you wont notice in base model, as it's 2.5d. Training with reg, even if 2x longer and not ideal reg usage(x25, but ideal would be x50, as it was trained for 50 epochs) mitigates that almost entirely. Im not going to cope and say that it removes it, but difference is clear. Also less change to other things, like hai style and blah blah, you get the point.
Actual lora that is in use compares like that:

(Both are trained for same amount of steps)
On one with reg even hair strands are almost identical. Keep in mind that goal here is to change eyes, face at most. Though, that particular concept is often paired with specific lighting, so it changed alot too e-e
In some edge cases reg can even provide "slider" behaviour for your loras, when content deviates minimally, while trying to change only specific concept about image.

This is undersized clothes lora that i never released. Trained with reg. Has usable range of weight up to 3.0 in lots of cases.
@jelosus1 wont let me lie here, this is hard to achieve overall.P.S. All loras shown are trained on D8 and do not necesserily represent experience you'll have in other trainers, as all of them are a bit different
Epilogue
Don't you love that meme with Gandhi i made? Ehehe.
Please feel free to torture with questions anyone mentioned in this article with link, they'll love it, as suggested by @bluvoll :clueless:
People checking article before posting:
@Shippy - approved (He is the Kohya guy, i can't answer Kohya questions, ask him)
@Manityro - approved
@richyrich515 - lgtm ship it (I will still not use reg)