


I'm frequently getting questions about how to use my lora and get the result you are looking for.
This article is supposed to be a short summary of what i found to be helpful. There are many other better articles on this site and on the web.
These hints work for any style and any desired result.
A note on my Lora specifically: these are mostly trained on realistic datasets: This means you'll have to prompt heavily against realism appropiately for the checkpoint you are using and / or use style Lora.)
Second Note: Pls don't use SDXL models for Pony (and the other way around): I have Pony Versions for most/all SDXL Variants.
Text to Image OR If you are stuck with online generators
If you can't get good results:
Start fresh: Clean up your prompt, your loras, everything. Start new with just the most important/most complicated subject of your image. Try to get it to work. Then add in details you want.
Lower your cfg , up your denoising steps, change your aspect ratio, try a different checkpoint
Reorder, emphasize (and deemphasize:0.1) your prompt. Some prompts can compete too heavily with each other. Try finding those and get rid of the worst offenders
If you are getting almost good result, just keep trying. Hit queue a few times, say a few prayers to the RNG-Gods and go for a walk. Come back and your result may be waiting for you.
(If you are using multiple Lora that burn your image: lower their influence to the lowest possible value at which they still have an effect!)
Image to Image OR How to get a complicated concept to work exactly how you imagined it
In my opinion simple image to image transformations are the way you can get the most out of Stable Diffusion. I'm not talking about redrawing existing images, but actually drawing yourself- But you don't need a graphics tablet or any drawing experience. Just any drawing program and a way to do image to image.
As of the time of writing the civitai online generator doesn't support image to image generation. There are however online generators that will do img2img. If you can run SD locally, thats obviously perferable.
I strongly recommend krita ai diffusion. Its an incredibly fast and intuitive workflow.
The process is the same for any img2img workflow you can run:
Draw the crude shapes of the image you want, describe the important parts of the image (leave details for later), use an denoising strength of around 0.7 (You can of course draw a better image and start with a lower denoising strength)
Take the output of the last step. Add in details into your prompt, redraw shapes that you don't want or seem wrong, lower your denoising strength (second step can be as low as 0.3 strength, depending on how much you want to adjust
Repeat step 2 as often as you want
Try some inpainting for problematic areas and outpainting if necessary.
Do upscale, face detailer, hand refiner etc to your liking.
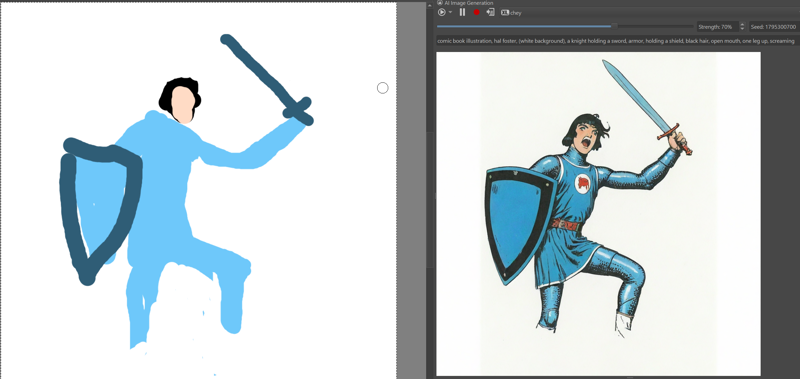
(pictured above: an incredibly crude drawing with a mouse in krita leads to a working pose, denoising strength 0.7)
That's it. If you have any questions or something you want me to expand on, comment below.
Good luck!