
,umamusume,finger_on_trigger,upper body,masterpiece,best quality,highres,.jpeg)
github:github.com/Koishi-Star/Euler-Smea-Dyn-Sampler/edit/main/README.md
# Euler Smea Dyn Sampler
Two sampling methods based on Euler's approach, designed to generate superior imagery.
The SMEA sampler can significantly mitigate the structural and limb collapse that occurs when generating large images, and to a great extent, it can produce superior hand depictions (not perfect, but better than existing sampling methods).
The SMEA sampler is designed to accommodate the majority of image sizes, with particularly outstanding performance on larger images. It also supports the generation of images in unconventional sizes that lack sufficient training data (for example, running 512x512 in SDXL, 823x1216 in SD1.5, as well as 640x960, etc.).
The SMEA sampler performs very well in SD1.5, but the effects are not as pronounced in SDXL.
In terms of computational resource consumption, the Euler dy is approximately equivalent to the Euler a, while the Euler SMEA Dy sampler will consume more computational resources, approximately 1.25 times more.
两种基于Euler的采样方法,旨在生成更好的图片
smea采样器可以很大程度上避免出大图时的结构、肢体崩坏,能很大程度得到更优秀的手部(不完美但比已有采样方法更好)
适配绝大多数图片尺寸,在大图的效果尤其优秀,支持缺乏训练的异种尺寸(例如在sdxl跑512x512,在sd1.5跑823x1216,以及640x960等)
在SD1.5效果很好,在SDXL效果不明显。
计算资源消耗:Euler dy将约等于euler a, 而euler smea dy将消耗更多计算资源(约1.25倍)
# Effect
SD1.5,测试模型AnythingV5-Prt-RE,测试姿势Heart Hand,一个容易出坏手的姿势
SD1.5: Testing the AnythingV5-Prt-RE model with the Heart Hand pose often results in distorted hand positions.
768x768,without Lora:

768x768,with Lora:

832x1216,without lora:

832x1216,with Lora:

SDXL,测试模型animagineXLV31,测试姿势也是手部姿势
SDXL: Testing animagineXLV31 model with hand poses.
768x768:

832x1216:


# how to use
step.1: 打开`sd-webui-aki-v4.6\repositories\k-diffusion\k_diffusion`文件夹,打开其中的`sampling.py`文件(可以用记事本打开,称为文件1)
Step 1: Navigate to the k_diffusion folder within the sd-webui-aki-v4.6\repositories\k-diffusion directory and open the sampling.py file within it (this can be done using a text editor like Notepad, which will be referred to as File 1).
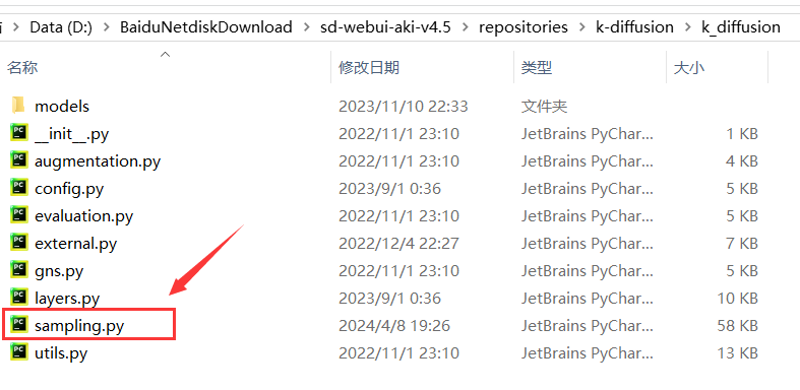
step.2: 复制本仓库中的`sampling.py`中的所有内容并粘贴到文件1末尾
Step 2: Copy the entire content from the sampling.py file in the current repository and paste it at the end of File 1.
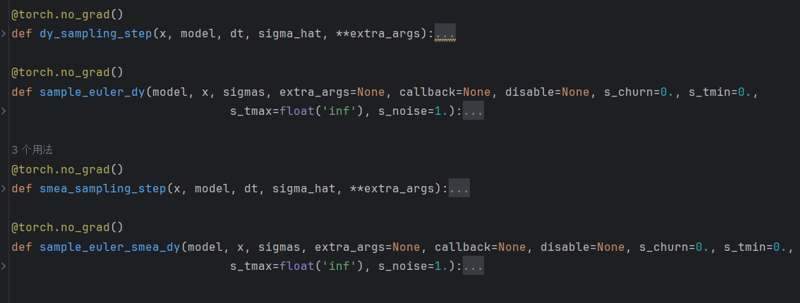
(To present the complete picture, I have utilized PyTorch's abbreviation feature.)
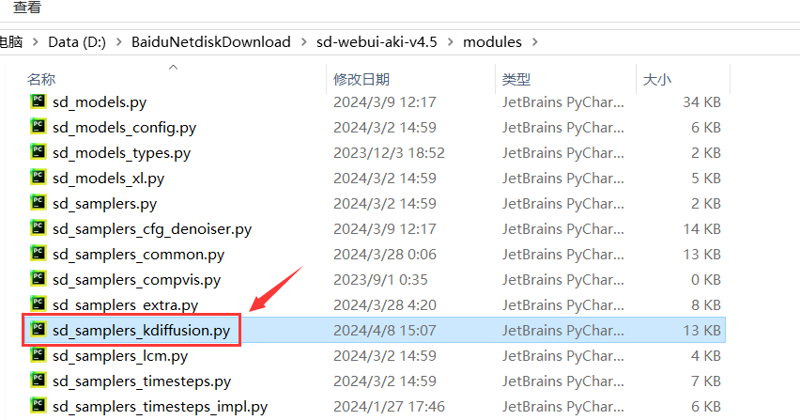
Step 3: Open the sd_samplers_kdiffusion.py file located in the sd-webui-aki-v4.6\modules directory (refer to this as File 2).
Step 4: Copy the following two lines from this repository:
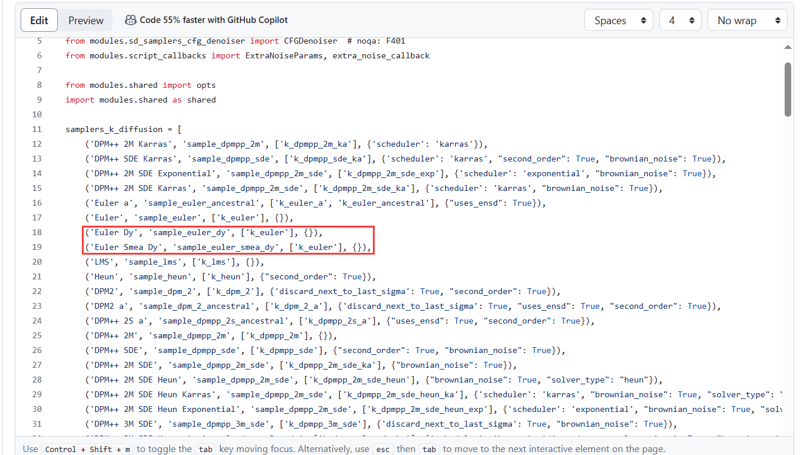
Paste them into File 2:
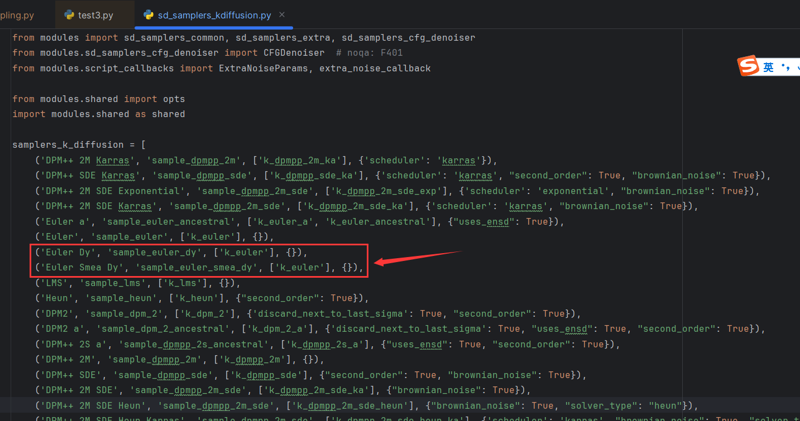
Step 5: Restart the webui, and you will see:
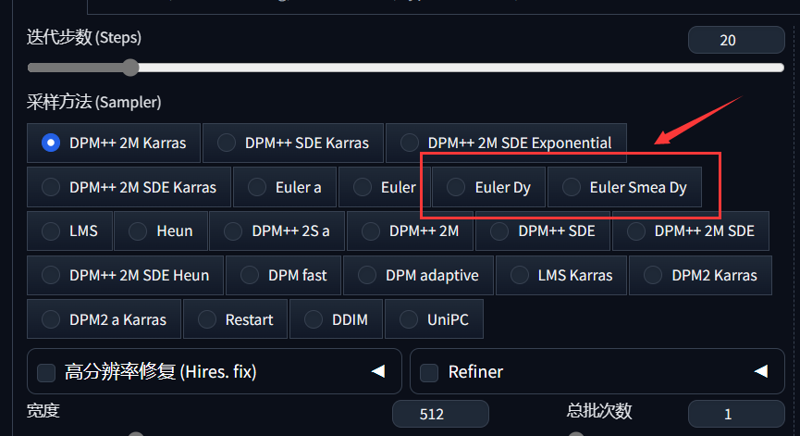
现在你就可以使用它们了。在图生图中可能有一些bug,欢迎向我汇报(请带上截图/报错声明)
Now you can start using them. There may be some bugs in the image generation process, and I welcome you to report any issues to me (please provide screenshots or error statements).
# The technical principles
简单地讲,dyn方法有规律地取出图片中的一部分,去噪后加回原图。在理论上这应当等同于euler a,但其加噪环节被替代为有引导的噪声。
而smea方法将图片潜空间放大再压缩回原本的大小,这增加了图片的可能性。很抱歉我没能实现Nai3中smea让图片微微发光的效果。
一点忠告:不要相信pytorch的插值放大和缩小方法,不会对改善图像带来任何帮助。同时用有条件引导取代随机噪声也是有希望的道路。
In simple terms, the dyn method regularly extracts a portion of the image, denoises it, and then adds it back to the original image. Theoretically, this should be equivalent to the Euler A method, but its noise addition step is replaced with guided noise.
The SMEA method enlarges the image's latent space and then compresses it back to its original dimensions, thereby increasing the range of possible image variations. I apologize that I was unable to achieve the subtle glowing effect in Nai3 with the SMEA method.
A piece of advice: Do not trust PyTorch's interpolation methods for enlarging and shrinking images; they will not contribute to improving image quality. Additionally, replacing random noise with conditional guidance is also a promising path forward.
# Contact the author
Email:[email protected]
Bilibili:星河主炮发射