




.jpeg)
介绍
目前,很多 SD 模型无法有效生成亮度很暗或很亮的图像。您可以通过使用以下几段提示词来验证您所使用的模型是否具有此种能力(不要使用负面提示词):
solid black background:纯黑图像black dog with black background:黑色的狗和黑色的背景solid white background:纯白图像white dog with white background:白色的狗和白色的背景
如果您无法用如 solid black background 生成对应纯黑的图像,或是模型生成的图像无法与每段提示词的内容所描述的色彩和明暗匹配,那么很遗憾,您的模型就不具备此种能力,即模型遭遇到 “平均灰度问题”。
本文将介绍目前图像生成扩散模型所面临的平均灰度问题,并在之后逐一介绍解决该问题的几种方法。
平均灰度问题
平均灰度问题,也叫 平均亮度问题,指常规的图像生成扩散模型,如 Stable Diffusion,无法生成很暗或很亮的图像的问题。除了亮度,该问题还会导致图像色域受损和对数据的还原受阻等问题。
成因概括
平均灰度问题的成因是 生成和训练没有对齐 而引发的 蝴蝶效应。
训练时,图像被逐步加噪,直到变为纯噪声。可实际中,加噪步骤存在数学上的缺陷,这导致 加噪其实并不彻底,图像最终并没有完全变成纯噪声,而是残留了微小的信息。这些小信息包括多种内容,例如图片的灰度和饱和度。于是乎,模型学会了 利用带有微小信息的噪声开始逐步去噪来还原图像。
然而,在生成时,我们提供给模型的却是一个完全的纯噪声。可是,由于训练时的经历,模型会 尝试利用明明不带任何信息的纯噪声中寻找信息——这是它从训练中学习到的错误经验,模型本不应该这么做。纯噪声表示图像的灰度和饱和度都处在平均状态,这种信息被模型当成要求遵守,于是,最终生成出图像的灰度和饱和度都变得平均了。
由于这些残留的微小信息实际上是原本图像的片段,因此,平均灰度问题的影响范围远不止灰度和饱和度,而是 几乎所有的图像属性,构图、细节等等都无一例外会被篡改。而影响的大小不同,以灰度最为突出,饱和度其次,故以 “平均灰度” 命名。
原理概括
阅读该部分要求读者对扩散模型的原理有所了解。
主流的扩散模型采用噪声预测(epsilon prediction)。噪声预测是预测 图像对应的纯噪声 而不是图像本身。扩散模型在末端时间步 T 时获得均值为 0,方差为 1 的纯高斯噪声。然而,噪声预测的原理存在缺陷,在它的计算中会将噪声的均值作为分母,因此会在 T 时间步下出现分母为 0 的数值问题。
为了避免这一问题,许多噪声调度器(noise scheduler)都会退而求其次地稍微偏离在 T 时间步下的加噪结果,例如将加噪后噪声分布的均值从 0 改为 e,其中,e 是一个很小的数,以近似地渐进 0,进而近似纯噪声。
 图:不同调度器在末端时间步 T 下的具体信噪比 SNR(T)。没有任何一个调度器的末端信噪比等于 0。
图:不同调度器在末端时间步 T 下的具体信噪比 SNR(T)。没有任何一个调度器的末端信噪比等于 0。
这种不完全的加噪导致最终“纯噪声”中携带了少量低频信号。这些信号可能包含了图像的大致分布,例如整体明暗分布等。在此过程中,模型所学便是“根据一个近似纯噪声中的微小信息还原该噪声为图像”,而不是“还原纯噪声为图像”了。
 图:对整体明暗偏黑和偏白的两张图像加噪的结果,从加噪后的噪声中可以明显观察到其与原图明暗度的相关关系。
图:对整体明暗偏黑和偏白的两张图像加噪的结果,从加噪后的噪声中可以明显观察到其与原图明暗度的相关关系。
一个数值上的例子是,原先预期加噪 T 步后的图像是纯噪声 xT = 0*x0 + 1*ε,而实际加噪 T 步得到的图像是“近似”纯噪声 xT'=0.068265*x0 + 0.997667*ε,其中 ε 表示标准高斯噪声,x0 表示原始图像。
这种“近似”手段在推理时会引发问题。推理时,我们为采样器提供了一个纯高斯噪声,均值为 0,方差为 1,不带有任何细小的信息。而经过训练的模型却认为该纯噪声带有微小的信息,例如,均值为 0 可能表示该图像明度平均。在此基础上,推理出的图像便明度平均了。
解决方案
x 预测
x 预测即最原始的,在训练中预测原图而非噪声。x 预测最直观,但也最不稳定,几乎没有模型使用它。目前主流的预测方式仍然是噪声预测和 V 预测。
噪声偏移
噪声偏移是最早的解决方式,其本质是 以毒攻毒,即 通过在训练中二次添加微量随机噪声,来扰乱加噪后图像中残留的信息,从而妨碍模型去关联残留信息和原始图像。噪声偏移不需要设定很高的值。相反,噪声偏移值设置越高,对训练越不利。噪声偏移仅用于中和纯噪声中的残留信息,大约 0.03~0.04 就足够了(模型 Animagine XL V3.1 的推荐值为 0.0357)。
开启噪声偏移后,仅需很少的训练,就几乎能完全摧毁模型的错误观念,修复平均亮度问题,让模型生成很暗和很亮的图像了。因此,对于基础模型的训练和微调,仅需在训练的尾声部分加入推荐值的噪声偏移即可。
噪声偏移虽然在效果上成功生成了很亮和很暗的图像,但由于其原理是错误的,训练和推理仍然没有对齐,因此 并没有解决根本问题。一些经验实验表明,即便使用了噪声偏移,模型所生成的很暗或很亮的图像仍缺乏真正的光影和色彩表达。长期使用噪声偏移还可能会使模型带上噪声伪影,该现象在使用多分辨率噪声(或称金字塔噪声)时尤为严重。
V预测+零终端信噪比
V 预测 [1] (v prediction)是一种不同于噪声预测的预测方式,它将模型的预测目标转化为了 预测图像中噪声变化的速率(信噪比的变化速率)。V 预测经由数学推导而来,因此它的预测目标并不直观。但是,对预测目标的巧妙转换使得其拜托了噪声偏移不得不除 0 的操作,因此能够正确地处理终端时间步 T 下的信噪比。
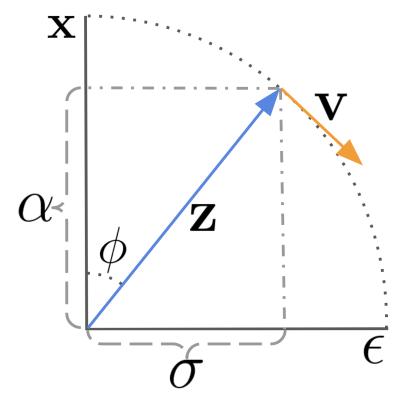 图:V 预测的预测目标可视化。途中坐标系的纵轴为图像,即 x 预测的目标;横轴为噪声,即噪声预测的目标。扩散是图像到噪声的转化过程,V 预测即预测该过程在特定时间步下的发生速率。
图:V 预测的预测目标可视化。途中坐标系的纵轴为图像,即 x 预测的目标;横轴为噪声,即噪声预测的目标。扩散是图像到噪声的转化过程,V 预测即预测该过程在特定时间步下的发生速率。
零终端信噪比 [2] (zero terminal SNR,简称 ZTSNR)是一个补丁,即在训练中,通过调整噪声调度器的参数,强制将末端信噪比归零,来将训练图像正确地加噪为纯噪声,以修复原先噪声调度器的缺陷。
 图:开关 ZTSNR 的效果对比。左侧 (a) 图为有缺陷的生成,右侧 (b) 图为开启 ZTSNR 后正确的生成。
图:开关 ZTSNR 的效果对比。左侧 (a) 图为有缺陷的生成,右侧 (b) 图为开启 ZTSNR 后正确的生成。
该方式确保了训练和推理维持相同的扩散轨迹,因此 几乎从根本上解决了问题。
V 预测与传统的噪声预测相比,只有预测目标不同,因此能通过微调预训练的噪声预测模型来将其转化为 V 预测模型,该过程成为烘焙(bake)。转化的具体方法可参考 NoobAI XL V-Pred Test。
SingDiffusion
SingDiffusion [3] 是一个在生成时即插即用的额外组件,它本质上是一个只执行一步推理的额外模型,负责在推理的第一步将纯噪声用 x 预测(不会产生平均亮度问题的预测方式)推理,后续步骤改用原本的模型和预测方式推理。
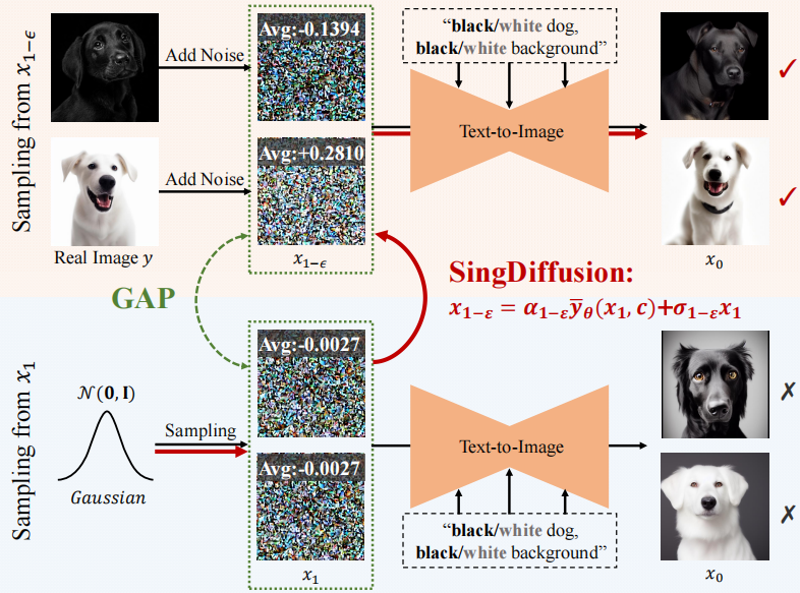 图:SingDiffusion 原理示意图。SingDiffusion 接管了第一步生成,在生成阶段修复了不完全训练加噪问题下,采样噪声和真实噪声之间的间隔。
图:SingDiffusion 原理示意图。SingDiffusion 接管了第一步生成,在生成阶段修复了不完全训练加噪问题下,采样噪声和真实噪声之间的间隔。
与噪声偏移和零终端信噪比方法相比,SingDiffusion 不需要额外的训练,但会稍微增加推理的计算量。另外,由于额外组件其实同样也是预训练模型,因此无法泛化到所有大模型。
参考资料
[1] Salimans, Tim, and Jonathan Ho. "Progressive distillation for fast sampling of diffusion models." arXiv preprint arXiv:2202.00512 (2022).
[2] Lin, Shanchuan, et al. "Common diffusion noise schedules and sample steps are flawed." Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2024.
[3] Zhang, Pengze, et al. "Tackling the Singularities at the Endpoints of Time Intervals in Diffusion Models." arXiv preprint arXiv:2403.08381 (2024).