






有监督学习
有监督学习一般用于分类,图像识别等,表示x向y的映射关系(x表示数据,y表示标签)
无监督学习
聚类,降维,特征学习
隐藏在数据当中的数据结构进行学习
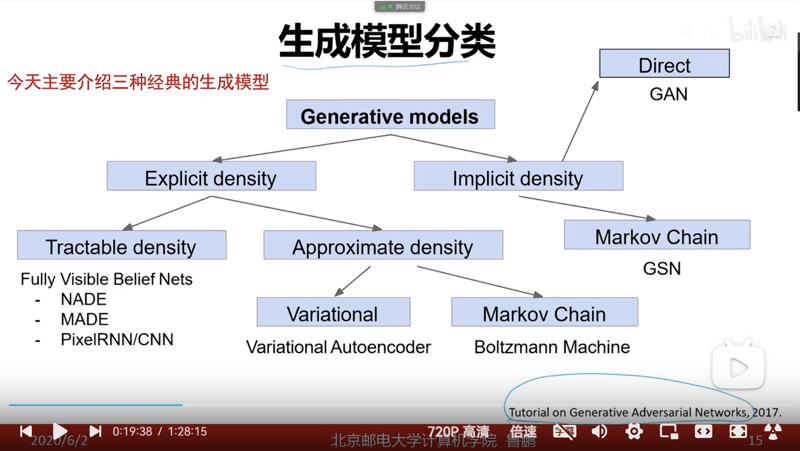
生成器
目标:训练集生成和训练集相似分分布的生成数据
生成器类型
生成器组成部分
各部分代原理
各部分代码实现含义
pixel rnn
将图像的像素分布看作转为序列化的表示,将像素生成转化为概率问题,定义了像素产生的顺序,但是根据这样的计算无法转化为并行计算,因为序列式的计算需要前一步的数据作为支持计算下一部的概率。
生成图像速度太慢
pixelCNN
PixelCNN通过堆叠多层卷积神经网络来建模图像的条件分布。它使用了几种技术来增强模型的性能,包括:
Masked Convolution(掩码卷积):PixelCNN中的卷积层通常会使用掩码(mask),以确保在每个像素预测时,只有当前像素之前的像素被视为输入。这样可以确保模型不会在生成像素时“看到”它所预测的像素之后的信息,从而使生成的图像更加真实。
Residual Connections(残差连接):为了缓解深度网络的训练问题,PixelCNN使用了残差连接,使得信息可以更好地在网络中流动。
Gated Activation Units(门控激活单元):PixelCNN中的激活函数通常采用门控激活单元,这种单元可以帮助网络更好地捕捉像素之间的复杂依赖关系。
生成速度依然比较慢
PIXELrnn和cnn的区别
PixelCNN和PixelRNN是两种相似但稍有不同的模型,都是用于生成图像数据的生成式模型。它们都是以像素为单位建模图像的条件分布,但它们之间的主要区别在于网络结构和训练方法。
PixelCNN:
PixelCNN的全称是"Pixel Conditional Neural Network"。
PixelCNN使用了卷积神经网络来建模图像的条件分布,因此它是一种卷积生成模型。
在PixelCNN中,通常使用了一种叫做Masked Convolution的技术,以确保在每个像素预测时,只有当前像素之前的像素被视为输入,这样可以避免模型在生成像素时“看到”它所预测的像素之后的信息。
PixelCNN通常可以分为两种结构:PixelCNN和PixelCNN++。PixelCNN++是对原始PixelCNN模型的改进,通过使用更深的网络结构和更多的技巧来提高生成图像的质量。
PixelRNN:
PixelRNN的全称是"Pixel Recurrent Neural Network"。
PixelRNN也是一种以像素为单位建模图像的条件分布的生成模型,但它使用了递归神经网络(RNN)来建模像素之间的依赖关系,而不是像PixelCNN一样使用卷积网络。
在PixelRNN中,像素的生成是通过递归地考虑图像中每个像素的条件概率来实现的。通常使用的是LSTM或者GRU等循环单元来建模这种递归结构。
PixelRNN的结构使得它可以在生成图像时考虑到整个图像的上下文信息,因此在一定程度上可以更好地捕捉像素之间的长程依赖关系。
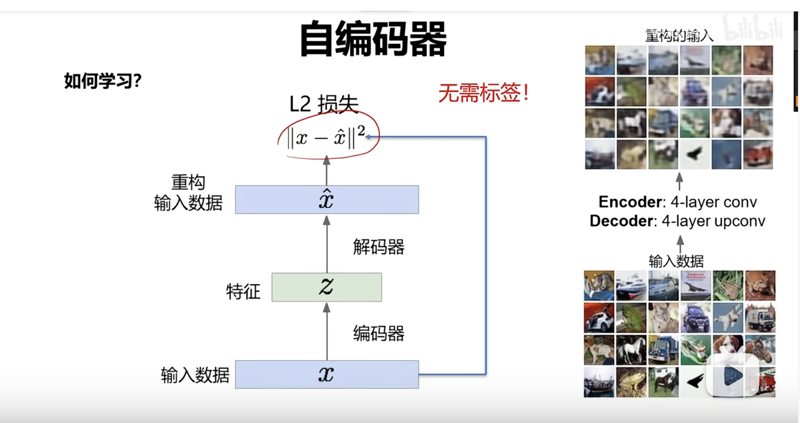
自编码器
自编码器是一种无监督学习的神经网络模型,它由两部分组成:编码器(Encoder)和解码器(Decoder)。编码器将输入数据映射到潜在空间中的低维表示,解码器则将这个低维表示映射回原始输入空间。自编码器的目标是最小化输入数据与解码器输出数据之间的重构误差,从而学习到数据的有效表示。
vae模型 变分自编码器
自编码器(Autoencoder):
自编码器是一种无监督学习的神经网络模型,由编码器和解码器两部分组成。
编码器将输入数据映射到潜在空间中的低维表示。
解码器将这个低维表示映射回原始输入空间,以重构原始输入数据。
自编码器的目标是最小化输入数据与解码器输出数据之间的重构误差。
变分推断(Variational Inference):
变分推断是一种用于近似推断概率模型后验分布的方法。
在变分推断中,我们假设后验分布是一个参数化分布,并且尝试最小化这个参数化分布与真实后验分布之间的差异,从而学习到模型中的参数。
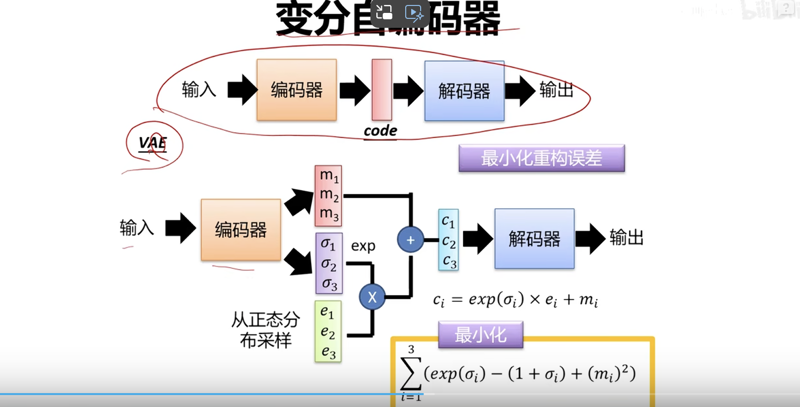
变分自编码器(Variational Autoencoder,VAE)的结合:
在变分自编码器中,编码器不再直接生成潜在表示,而是生成潜在空间中的分布参数,通常是均值和方差。
解码器则从这些分布参数中采样一个潜在表示,并将其映射回原始输入空间。
这种做法引入了潜在表示的概率性质,使得模型能够更好地捕捉数据的不确定性和多样性。
通过在编码器输出的分布参数上进行采样,我们可以得到不同的潜在表示,这使得模型能够生成多样化的数据样本。
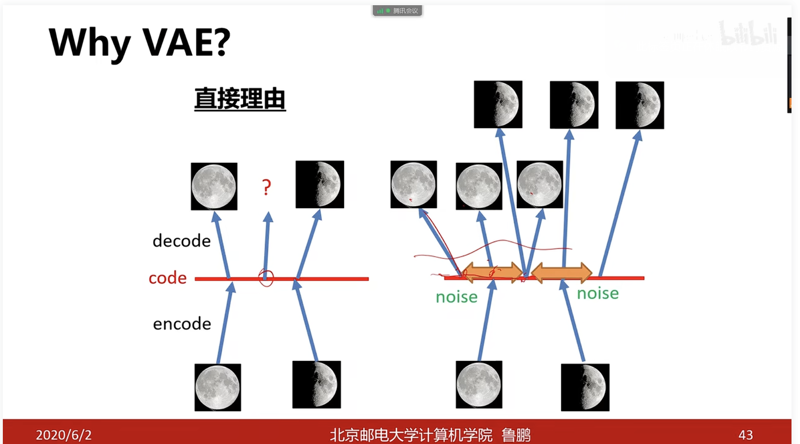
(变分自编码,自身理解,比如一组数据的参数分布其实式一个球,但是你只有尺子,然后你就尺子画了一个球,但是你尽可能画得像一个球,因为这样你比较方便。所以在后续过程中你直接使用这个你画的这个球去进行计算啊啥的,你要尽可能画得像,但是自己画得这个球肯定比真实的球要简单,这样才方便进行计算)
同时和自编码器相比,(加入标准差和超参数的部分?)原有数据上加入偏置,增强编码器得泛化能力,(增强像素分布的随机性?)
从单一编码扩散为一个范围得参数进行生成,使得模型的泛化能力增强。
变分自编码器推导
图片来源 鲁鹏老师的线上课程ppt,感谢鲁鹏老师在深度学习教学方面的贡献,
文献来源
13.生成模型VAE.1080P_哔哩哔哩_bilibili
runwayml/stable-diffusion-v1-5 ·拥抱脸 (huggingface.co)
代码来源
stablediffusion/scripts/streamlit/depth2img.py at main · Stability-AI/stablediffusion (github.com)