

D8 Dreambooth
Introduction
Welcome! Today we are going to talk about extension for training Dreambooth and LoRAs in your A1111(and forks). It is user-friendly, mostly stable, and provides you with some interesting settings to tweak in /dev branch :3
You can install it right from extension tab in your webui, or download manually here - https://github.com/d8ahazard/sd_dreambooth_extension
It is also available as a part of Gradio-free interface, developed by creator of that extension:
https://github.com/D8-Dreambooth/stable-diffusion-plus
I'll say from the start, as it's important:
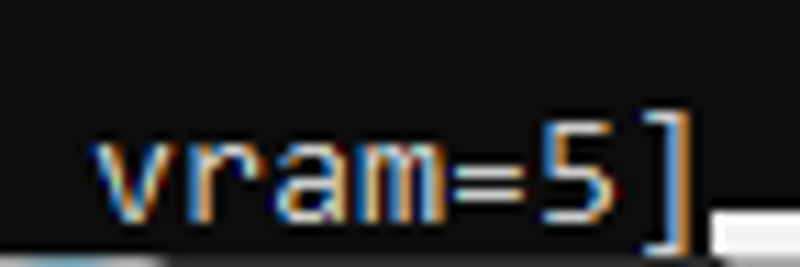
It probably is possible to train LoRA on 6 gig GPU with it, as it consumes 4.8-5(add ~0.75 of usage by other things) at rank 4/4, using Adan Optimizer, on Torch2, batch 1. Without xformers(default attention).
I should introduce myself - im Anzhc, fantasy cartographer and AI enthusiast just like you, you might've seen my style LoRAs, if you ever visited LyCORIS section. All of them are trained with D8 extension on /dev branch. I will introduce you to the ropes of this interface, and go over parameters that you need to know, including experimental features.
If you are interested in practical showcase of capabilities, you can head to my page and download my popular models, and then get back to reading article :D
https://civitai.com/user/Anzhc
Image for banner is one of the generations of S12 Technidrawing model.
https://civitai.com/images/815222?modelVersionId=73072&prioritizedUserIds=918424&period=AllTime&sort=Most+Reactions&limit=20 (If you want to get prompt for testing or just look at full image, because banner one is cut-off)
Choosing Branch
As i've mentioned, there are multiple branches accessible to users. If you want stable release, just install as usual. For /dev branch i would recommend using Fork, or other things you're comfortable with, as im pretty bad at stuff and need comfortable UI, i will go with Fork.
If you want to follow with me, you can download it here:
https://fork.dev/
(And no, it's free)
You will need to open repository:
Navigate to main folder of D8 extension that you've installed, and open that repository. It will create a new tab for it.
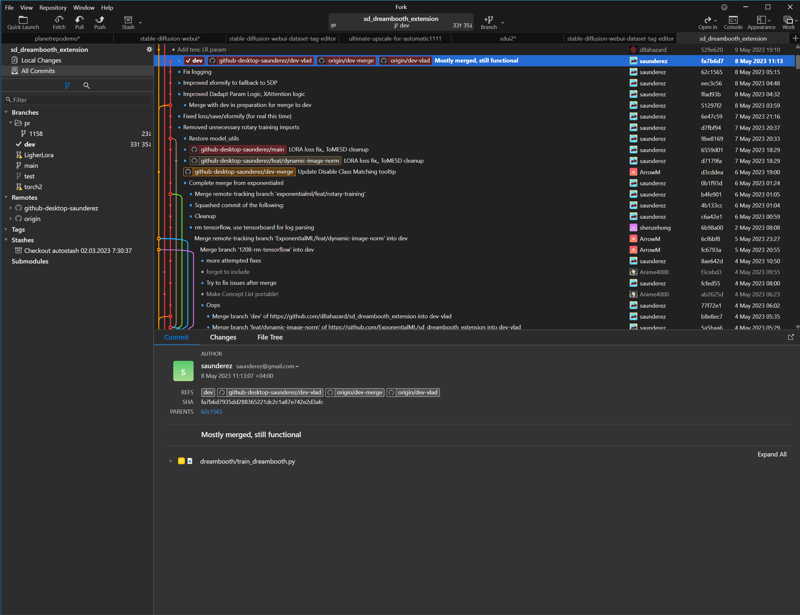
Scary for the first time, i know, but you really need to know only couple buttons:
Fetch - gets updated information about branches
Pull - for updates of your branch
You don't need Push
You don't need Stash
To get /dev branch, in this case we will get specifically /dev-vlad branch, as it is the one with the fixes to work with webui most people use, we need to Pull:
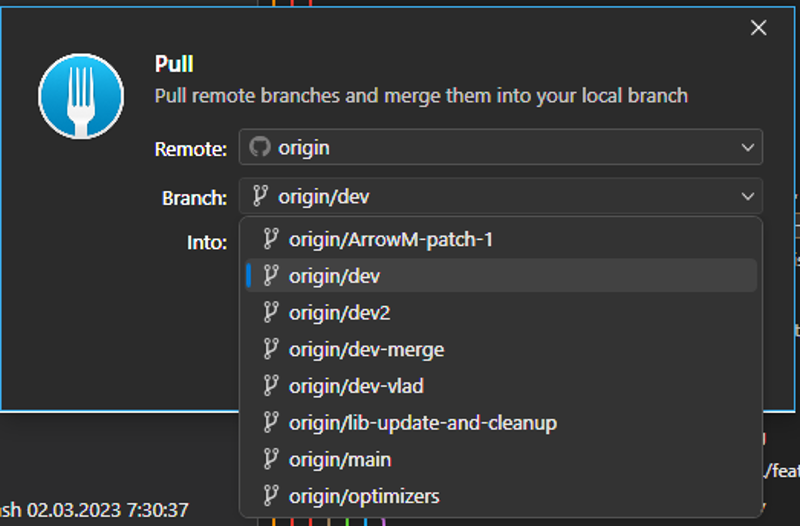
Choose origin/dev-vlad and click Pull. Current Main is more up to date than dev-vlad, so you might want to use that.
31/05 - I did test most recent dev, and it worked, but preview images are not working and will crash training, if you try to use them. If you don't look at images throughout training - feel free to use main /dev.
17/06 - Main branch was merged, so you better off using it, all dev features got merged in.
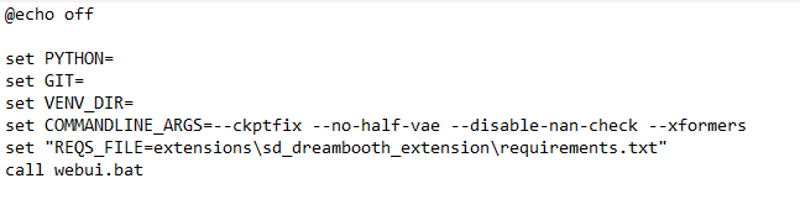
Relaunch your webui, if you had it open, and see if it works. If it doesn't - head over to webui-user, open it, paste line below after commandline_args:
set "REQS_FILE=extensions\sd_dreambooth_extension\requirements.txt"
This will ensure download of necessary components.
If you still have issues - head over to D8 discord server, and i, or any other competent enough being, would help you there.
I would also recommend to add --ckptfix flag to your arguments, if you have 8 or less gigs, as your model generation(if you would want to merge loras in model) will fail, most likely.
Getting Started
To see Dreambooth tab you would need to completely restart your webui, if you haven't done that already.
If you ask: "Why everything is grayed out?"
"Because you don't read" - i would answer.

We will need to head over to Create tab, which is second one in the first column:
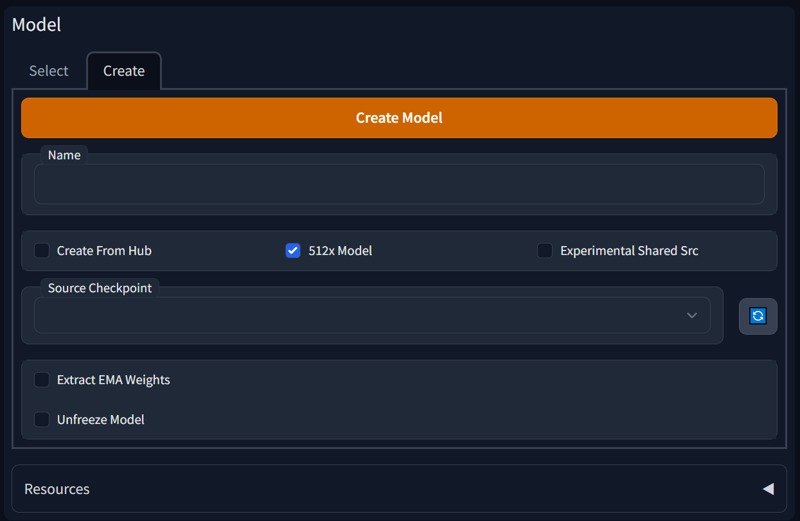
Choose your name for training model, pick a model to be your base.
You don't need to touch the rest, but if you want to follow exactly like i do - you will touch Unfreeze Model checkbox, so it's on. I do not have comparisons with on/off, but i trust the tooltip. All my released models are trained with that checked.
Experimental Shared Src is not an option i use, it lets model borrow the same diffusers instead of creating a new ones each time, to save space, but for LoRAs you don't need to create new models each time, as you will see in next screenshot.
I do not need EMA weights, as it' a VRAM intensive usage, which is not very available to even 16gb cards, im pretty sure, so i can't tell how it affects training.
Next we go back and pick our newly diffuserised model:
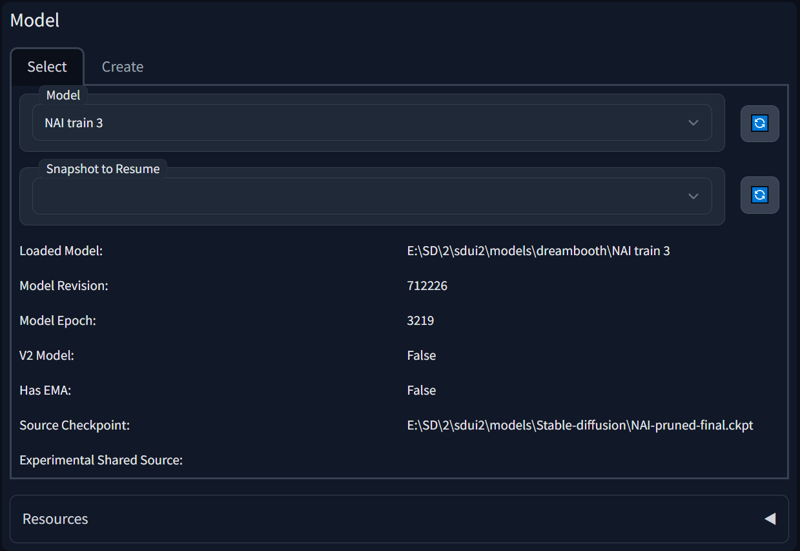
Not very new in my case...
Next steps would be parameters and what they do, so we will start with important disclaimers.
disclaimers
D8 is not directly comparable with Kohya_ss, as they use different training code and provide different customization options(If you use Lycoris code for training. Kohya/lora/locon seem to be very comparable, at least in my tests). Important to note, that even parameters that will work in one are not guaranteed to work in another(To a degree, and not on Lycoris trainihng code).
If you have good experience with Kohya, it is likely that you would prefer using Kohya, D8 is less, let's say, experimental, and will likely provide lower quality on the comparable parameters, all else equal, as Kohya uses more advanced code(?(*Likely im referring to Lycoris code*)). Users with over 8 gigs of memory are likely to benefit from Kohya interface more, but im unable to verify that, as im owner of 8gb card.
I will concentrate on parameters for Extended LoRA(LoCon(Probably, i think)), as this is what i'm training most. I will try to cover less experimental options, but my main training is always on /dev branch, so im most acustomed to features that are not available in /main(17/06 - dev was finally merged, so you'll get all those features).
Parameters will be looked at out of order, as the article structured in a top-down way, from high level parameters to lower.
I am a style trainer. I know how to train characters and concepts, but my expertise lies within style and fine-tune realms.(But i still can train 12 character loras just for lulz)
All my descriptions of how it affects model will be esoteric and abstract in nature, as im not an ML engineer, or even programmer, unless you consider programming with ChatGPT real programming.
I am using Torch2, which is significantly different in terms of training.
Settings that i remember(or think) are available only on /dev i will mark accordingly.
Grand Scheme of Things(Dreambooth|LoRA/Extended LoRA, [class], Optimizations)
So, here goes our sanity, we want to train models. What do we need to choose?
LoRA/Extended LoRA - 10 gigs and lower. Or want portability and compatibility with multiple models.
Dreambooth - 10 gigs and higher. And want to train something significant.
It is possible to train Dreambooth with 10 gigs by training single component(Tenc, U-net) at a time.
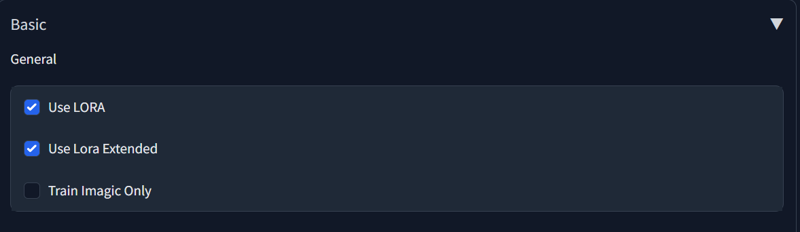
Don't pick LoRA options to train Dreambooth.
Lora Extended is an implementation of LoCon, as i understand, but im not very familiar with differences between all those. It's very old, so it's probably a LoCon.
Training time is easy. We want to train 50 epochs for LoRA, and 100 for Dreambooth.
Rest are up to you, they are not important and can be all set to 0, if we're doing things right, as we wont need to check progress.
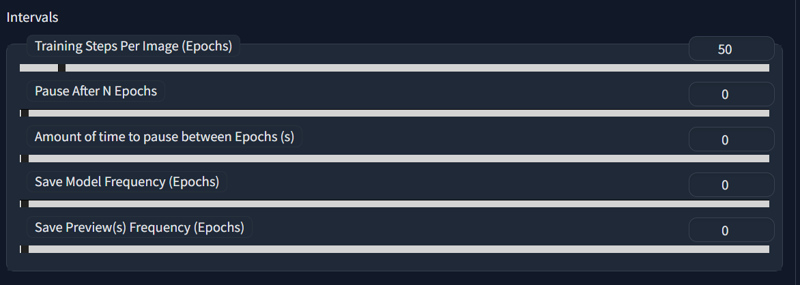
Next thing we need to determine - what do we train, and do we need class dataset for it?
Based on that answer we would need to fill out next screenshot:
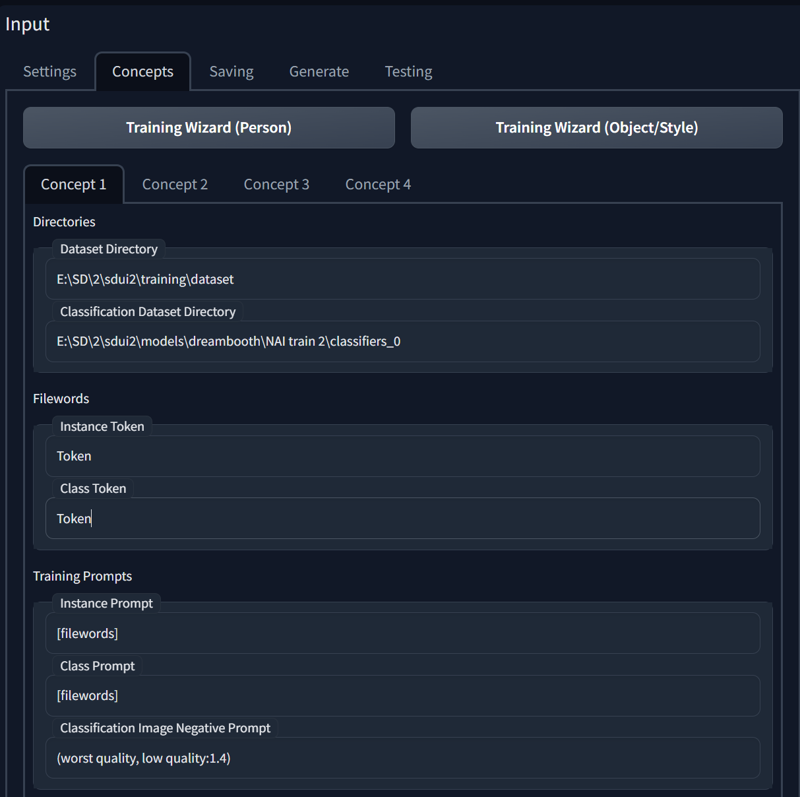
Generally, there are 3 categories that your training will fall into:
Concept-Character
This is most common case where you want to use instance tokenStyle
You can, or you can choose not to use instance token, as styles often apply on top with the goal of always using it, so you don't necesserily need it. - I don't use, usually.Fine-tune
Welcome to the big LoRAs. This is a way to train large multi-concept, or general datasets(that don't introduce new knowledge, strictly speaking, but rather improve existing wide areas of model knowledge)
Class token - i... I really don't know, i never use it, and people have reported better training without it, so i would suggest to not use it, unless you already know what you're doing.
Instance tokens are really not much different from your common image tag, only difference is how they are fed to class image generation(They are not) and tag shuffle(they are not shuffled), so, imagine fine-tune as a training with multi-concept that already has all classification images it needs in dataset.
Next we want to determine how much, and if, we need class.
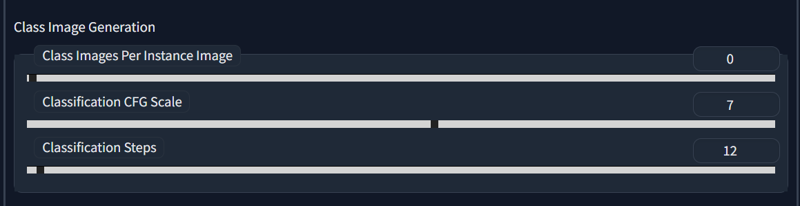
If you do fine-tune - you don't need class, as it will only hinder your progress.
If you're doing style - i would not advise, unless your style is big and surely can be discerned.(Of course you will need instance token(look way 2 of concept-character).
If your choice of training is concept-character, then you have 2 ways:
If you want your character to replace every other character - you don't use class and instance token, and just train with all tags, as you would in fine-tune. You don't need to use character name for that.
And second way - yes, we use class images and instance token. Preferrably 50(100 for Dreambooth), as it will cover need for unique image per each step of detaset. But it should be more than fine if you use less, but keep general number around 1000. For example you have 100 images, it will create 5000 class images, if we specify 50, so we can use 10 to strike balance and get 1000.
VRAM optimizations



If you're using Torch2, you want ot match those settings to comfortably train under 8 gigs.
If you're using Torch1, you also want to use xformers, which i do not recommend, upgrade to Torch2, by following instructions here:
https://github.com/d8ahazard/sd_dreambooth_extension/releases/tag/1.0.13
Strategical Thinking(Optimizers, LRs, Ranks, [prior loss])
Optimizers
Those are the backbone of our training. They determine how we learn. Generally, there are few, but all of them are interesting:

You are likely familiar with 8bit AdamW, as it's pretty much standard for all kinds of trainings.
Torch AdamW is 16bit AdamW(/dev), this is pretty much all the differences.
8bit Lion(/dev) is Lion, but 8 bit, more vram efficient.
All D-Adapt optimizers are /dev only.
Currently, on branch i suggested, you can train only with D-Adapt, as others are broken with some code error.
D-Adaptation optimizers are LR-independent(almost), and find what it will be automatically.
Currently i consider Adan to be the best. AdanIP is more agressive variation of Adan.
Each optimizer takes different values of Learning Rate and Weight Decay, which i will specify in according chapters
So, general TLDR about all of them:
Adamw(8/torch) - standard, you know it, you love it.
Lion(8/full) - Less known, more recent and better, according to papers.(+ ~2% accuracy)
D-Adaptation(all) - LR-free method of training.Adan/AdanIP
AdanIP is standard Adan starting from D-adaptation v3 code.
Keep in mind that all optimizers utilize different(and not insignificant) amount of VRAM
Ranks

More - better(or not, but generally - yes). Higher rank - more vram used.
I can comfortably train on 8 gigs with heavy Adan optimizer:
64/384 batch 2/2
48/256 batch 3/3
32/192 batch 4/4
...
Yes, i like to keep Tenc 6 times apart from Unet. Why? Don't ask, it's not justified by any knowledge, i just do. Don't try that, or do.
Learning Rate
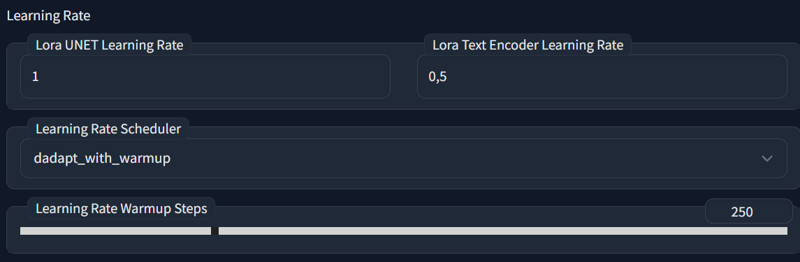
D8 supports separate LR for unet and tenc for both d-adapt and non d-adapt optimizers. Standard recommended Learning rates for them are(adjusted):
AdamW: Unet(0.0001) Tenc(0.00002)
Lion: Unet(0.00002) Tenc(0.000004)
D-Adapt: Unet(1) Tenc(0.5)
Warmup - keep it ~5% of total steps.
Prior Loss(Classification Dataset weight)
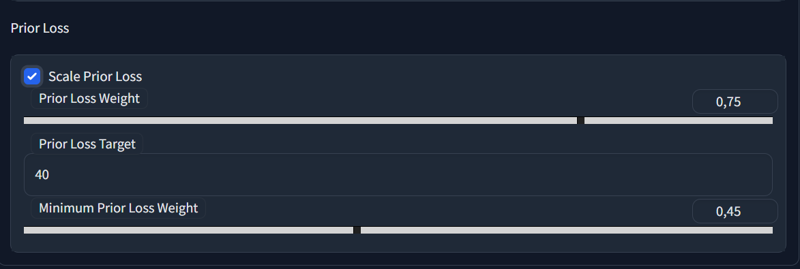
This is a hard topic, as different people would provide different information. It would be safe to stick with 0.4, i had success even with 1, so it really would depend on quality of your data. You'll have to experiment with it.
You start with high and scale lower during the training.
Tactical Approach(Weight Decay, Noise offset, tenc step ratio)
Weight Decay, Clip skip, Grad clipping

Same as with LR, different optimizers take different values.
AdamW: 0.01-0.1
Lion: 0.06-0.15
D-Adapt: 0.03 - 0.08
Tenc Weight Decay:
Generally i would recommend keeping it higher than unet decay, as it led to much better results based on experience, as tenc and unet train differently, they require separate parameters.
Adjust them by doing offset of main WD, you can start with +0.01, and go from there.
For D-Adapt i prefer to use offset of 0.02-0.025.
Tenc Grad Clipping Norm:
Another feature that prevent ovetraining and overfitting of Text Encoder. It basically limits very significant weights in addition to applying weight decay. There is no one size fits all, as i think different datasets will benefit from different value.
I prefer using 4, but you might want to be more conservative and use 1-2.
Clip Skip
As usual, 2 for anime, 1 for the rest, or whatever else info you got on that.
Noise Offset

Never experimented with negative, but safe positive range of usable will be ~0-0.08. More - darker.
I will advise against using offset noise for D-adapt optimizers, as it throws off their LR search, which cause LR to blow up, unless your growth rate is limited(to 1.02 for example).
Tenc step ratio

General recommendations:
Character - 0.75, style - 0.25-5, fine-tune - 0.75
D-Adapt - 0.75 for everything.
You can experiment with it, or leave at 1, but that might cause overtrain for text encoder, if you're not careful.
Saving
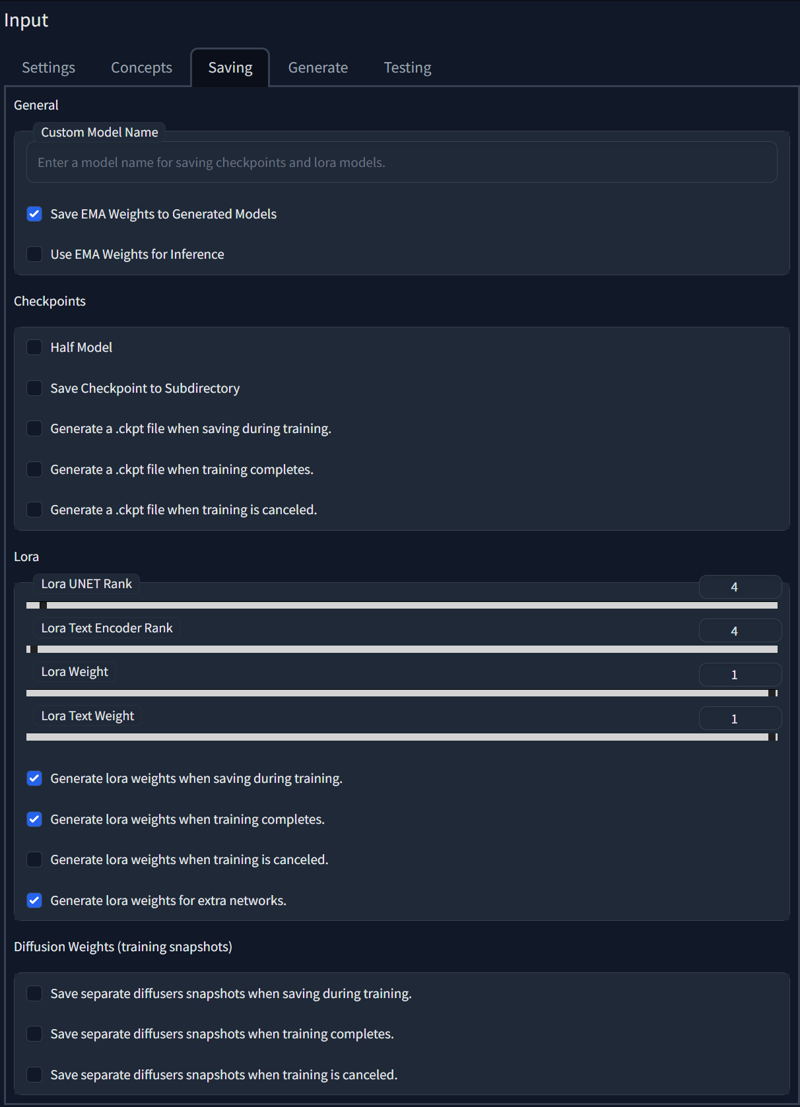
Most things are self-describing here, so lets just go over basic concepts and specific checkboxes that might not be apparent.
EMA weights - if you haven't trained with them, you don't need them pretty much.
Checkpoints - those are full models.
Half model - fp16(2 gig models).
Lora for extra networks - saves lora as dynamically usable model. You need Locon extension for that to trigger properly. If you don't have a locon folder in your extensions - it will not save.
Snapshots - checkpoint state mid-training of Dreambooth, so you could continue from previous points without creating new model.
Honourable mentions
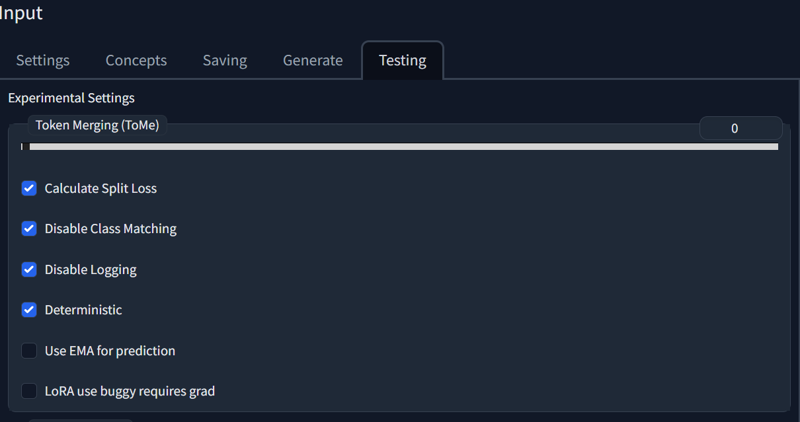
Bunch of stuff that you usually don't want to touch, but it just itches to tweak things, amirite?
Split loss - calculates separate loss graph for instance and class datasets.
Disable class matching - disables mathing of captions(i think) for classification dataset(they will be not matched to instance dataset images)
disable logging - no moar graphs, no more loss, blind training
deterministic - repeatable training seed. Mostly for comparisons. You might want to turn it off, it might give better results ,but only random will decide that.
Ema for prediction - no idea, as i can't use EMA.
LoRA use buggy requires grad - trains embedding layer in lora training, when it usually doesn't, when it shoudln't. Results can differ, but usually they are pretty similar. But it can differ significantly. This way of training applies for steps after tenc training was finished and you should train unet only(after tenc step ratio has been reached)
Noise Scheduler

You don't care. It has miniscule differences. They might accumulate for larger datasets(1000+), but otherwise too insignificant to care.
End
Well, that's it.
I will be expanding, fixing and improving this article based on feedback, so, feel free to ask for additions in comments - i'll deliver.
If that was of any help, well, you know...
https://www.patreon.com/anzhc
https://ko-fi.com/anzhc
wink wink