
Hi Everyone,
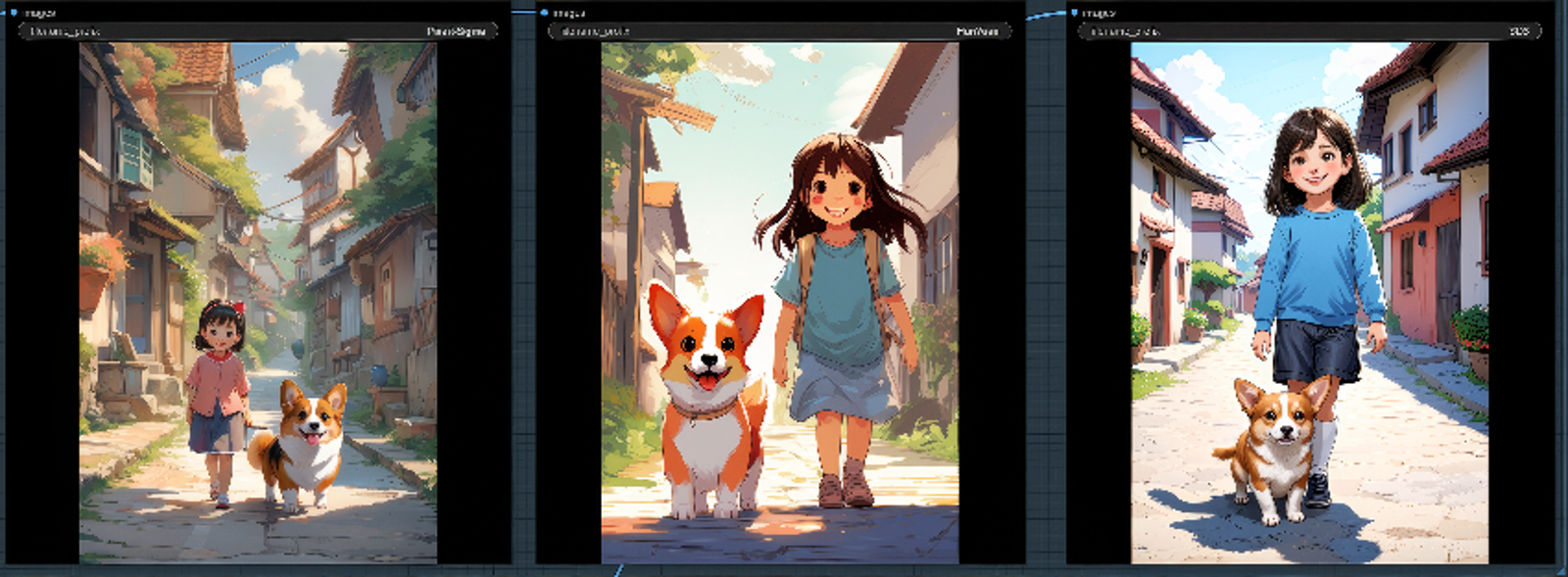
With the recent release of the SD3 Medium weights and the public response to some of the issues, I decided to take some time and compare four models I've become more recently acquainted with. PixArt Sigma, Hunyuan DiT, Lumina-Next-T2I, and of course SD3 Medium.
This comparison is not scientific and was merely created so people could see various prompts used for each of the three aforementioned models. My goal was to get a feel for which models I felt had the best prompt adherence and also which were the most aesthetically pleasing. The first goal is pretty objective, but the second is subjective. I would also like to spread some more awareness about open source alternatives for fine tuning since SAI's licensing model isn't great to say the least.
I modified a workflow that was created by the fantastic YouTuber, Nerdy Rodent so that all three models generated the same prompt in a row within a single workflow. He offers the workflow on his Patreon, so if you don't want to create it from hand, you can support him and download it. The modification I made was that I added an SDXL pipeline after the PixArt Sigma portion. I did this because the changes the refinement does is pretty minimal since I set the denoise to .40, and also because I find that PixArt Sigma tends to create artifacts, especially with people's faces. For Lumina-Next-T2I I used their Gradio web demo here.
Here is an example of two images. The first is PixArt Sigma with no refinement and the second is after a .40 denoise using Zavy's excellent ZavyChromaXL v7.0 model. As you can see the difference is an improvement but the image retains nearly everything.


The main reason why I chose to do this is a selfish one. I've been really enjoying the output of the PixArt Sigma model, especially after refinement. I've been fortunate enough to have a couple of my images here and here featured here on CivitAI that were created using PixArt Sigma and an SDXL refiner.
I was going to include the images directly in this post, but I used 31 prompts and a total of 93 images. I have everything listed in a Google Sheet here. I should add that I chose prompts that were longer than you'd expect. The reason being was that I've read that SD3 responded better to more natural language prompting. I even included a huge prompt as part of the test and lets just say the results weren't great for any of the models.
I tried to include a variety of different styles including photo realistic, anime, illustration, some recognizable characters as well as a couple of prompts with text. Spoiler alert, PixArt and Hunyuan are terrible at generating text.
I'd love to get any feedback you have and please leave a review and/or save the article if you find it useful at all.
Thanks!