

Now we can train Lora with Flux Dev on Civit, through the website trainer, it's time to dive in:
Live at 3pm GMT 18/08/24
we have used the same dataset to compare training runs with different settings on Cascade and SDXL, now we turn attention to FLUX.
dataset used: https://github.com/MushroomFleet/assassinKahb-1024/tree/mainAssasinKahb Test Loras: https://civitai.com/models/654919
V1
AssassinKahb-Flux-512x-adamw8bit-e5.safetensors
Trained with the Civit Flux defaults (17/08/24)
V2
AssassinKahb-Flux-1024x-adamw8bit-e5.safetensors
Changed resolution to 1024 only, Civit Flux defaults (17/08/24)
V3
AssassinKahb-flux-1024x-Kappa-Prodigy-e12.safetensors
Using Kappa Neuro's Prodigy Config
Ground Truth
dataset caption:
AssassinKahb style a demonic looking skeleton holding a sword with red hair 001
dataset example:

V1
The results were actually very close to the ground truth, training was fast and the style has been learned well.
https://civitai.com/images/24761670
V2
Again, with 1024x as the set training dimension, we have learned the source material well.
https://civitai.com/images/24761997
V3
When we used Kappa's Config, it seems to have included some unique stylization and detail
https://civitai.com/images/24760468
Kappa Neuro's Config
{
"engine": "kohya", "unetLR": 0.0005, "clipSkip": 1, "loraType": "lora", "keepTokens": 0, "networkDim": 2, "numRepeats": 20, "resolution": 1024, "lrScheduler": "cosine", "minSnrGamma": 5, "noiseOffset": 0.1, "targetSteps": ????, "enableBucket": true, "networkAlpha": 16, "optimizerType": "Prodigy", "textEncoderLR": 0, "maxTrainEpochs": 12, "shuffleCaption": false, "trainBatchSize": 6, "flipAugmentation": false, "lrSchedulerNumCycles": 3
}
you can adjust your repeats or epochs.
(Image Count * Repeats * Epochs / Batch Size) = Stepssteps max out on civit at 10,000
https://docs.google.com/spreadsheets/d/1e4lFBh7XfS814RIWEvbuy-A0KAkzrXqEDTw2Fg9yNDs/edit?usp=sharing
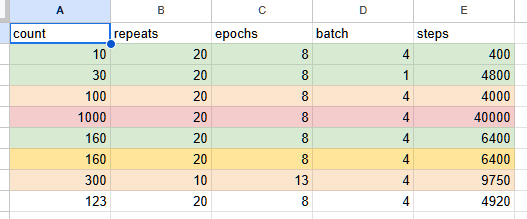
to give you an idea ^^ LR Increase might be in order if you lower repeats and/or eopchs
The jury is still undecided on the best settings. Time will reveal them I am sure.
For now i present these findings as a way to see which approach might suit you.
Being able to train on Flux right now on Civit is amazing and prevents a lot of stress for people unable to run this on an expensive GPU !
Note: V1 & V2 used "append tags" where V3 does not.
V4 will be trained to show the effect of the append tags feature.