

I recently forked ComfyUI to add support for LoRA for models using the NF4 format. This fork, available at ComfyUI_bitsandbytes_NF4-Lora.
These nodes are not yet available in ComfyUI Manager. Please download them manually from GitHub.
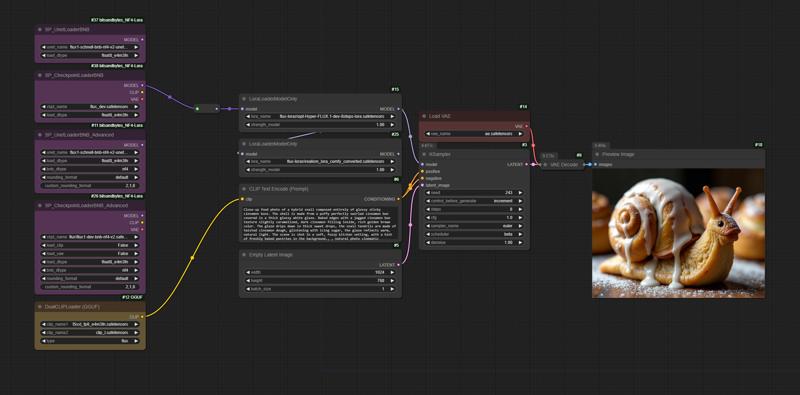
Workflow for Using These Nodes in Attachments
Comparison of NF4-FP8-GGUF_Q4_0 generations with two LoRA: HyperFlux+realism_lora at 8 steps:
Key Features of the Nodes
On-the-fly Conversion: The nodes allow conversion of FP8 models into NF4 format in real time. Generation speed does not drop with LoRA use.
Model Loading Optimizations: Improved model loading times by allowing users to specify the data type (load_dtype) of the model, avoiding unnecessary re-conversions.
Post-Generation Model Unloading Fixes: Ensures proper model partially unloading after generation, addressing previous issues that could affect memory management.
Tips for Best Quality
Use FP8 models: Although NF4 models are supported, the quality of applied LoRA is significantly higher if FP8 models are used.
Adjust the LoRA weight for NF4 models: When using NF4 models as inputs, you may need to increase the LoRA weight, otherwise the LoRA effect may not be noticeable. Also, in the Advanced Nodes section, try setting the rounding_format parameter to a preset of 2,1,7. Keep in mind, however, that using these settings may cause artifacts - experimenting with custom values may yield better results. Solutions I don't yet know how to effectively apply LoRA to nf4 models.
The node uses a modified rounding function from ComfyUI, which can be found https://github.com/comfyanonymous/ComfyUI/blob/203942c8b29dfbf59a7976dcee29e8ab44a1b32d/comfy/float.py#L14.
When the preset is set to 2, 1, 7, or custom, these three values determine the EXPONENT_BITS, MANTISSA_BITS, and EXPONENT_BIAS within the function, which control the precision of floating-point calculations.
Feel free to check out the project and contribute at the GitHub repository.