
Update 3/1:
Haven't touched V1.0/1.1, besides a few test gens, so all following information is verified against 0.1 and derivative base models, including NoobAI, only. However, my test gens indicate that most, if not all, of the tips laid out here work on those as well.
Great point mentioned by @ronaldmikhailp236 in the comments:
check out these Danbooru tag group pages for worthwhile tags on image composition, focus of image, backgrounds, lighting and color
https://danbooru.donmai.us/wiki_pages/tag_group%3Aimage_composition
https://danbooru.donmai.us/wiki_pages/tag_group%3Afocus_tags
https://danbooru.donmai.us/wiki_pages/tag_group%3Abackgrounds
https://danbooru.donmai.us/wiki_pages/tag_group%3Alighting
https://danbooru.donmai.us/wiki_pages/tag_group%3Acolors
Update 11/13 (multiple characters):
Because I've been asked by a few people:
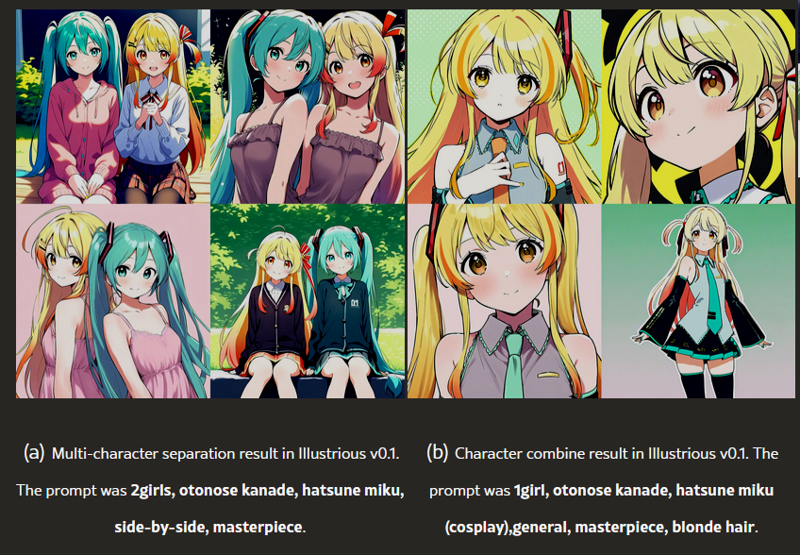
you can prompt multiple characters:
char count, character names, position of the characters, quality or even combine multiple characters into one:
1girl/1boy, character names (one with cosplay keyword), quality, physical attributes to preserve Update 11/3 (from Illustrious paper):
Complicated desired outputs = Complex prompts with mix of natural language and tags
Complex prompt structure and order:
char count (1girl, 2girls), characters' names (if an existing character like hatsune miku)
natural language describing the output, with periods separating sentences
list of tags
quality tags at the very end (usually just "masterpiece")
Simple Prompt Example:
1girl, hatsune miku, angel, masterpiece, generalResult: Basic, but creative interpretation
Complex/Upsampled Prompt (using TIPO):
1girl, hatsune miku.
An illustration of a girl with long white hair and wings. she is wearing a school uniform with a red bow on her head and a pair of headphones on her ears. the wings are spread out behind her, creating a sense of movement and energy. the overall style of the illustration is anime-inspired.
solo, skirt, feathered wings, necktie, smile, very long hair, collared shirt, long hair, headset, blue eyes, aqua necktie, looking at viewer, black footwear, black skirt, twintails, grey shirt, bare shoulders, detached sleeves, full body, zettai ryouiki, closed mouth, miniskirt, sleeveless, boots, thighhighs, shirt, standing, wing collar, aqua hair, sleeveless shirt, pleated skirt, angel wings, absurdly long hair, wings, black thighhighs,
masterpiece, general.Result: More detailed, consistent results with specific elements (wings, uniform details, etc.) being more precisely rendered
with this negative prompt:
worst quality, comic, multiple views, bad quality, low quality, lowres, displeasing, very displeasing, bad anatomy, bad hands, scan artifacts, monochrome, greyscale, twitter username, jpeg artifacts, 2koma, 4koma, guro, extra digits, fewer digits, jaggy lines, unclear 
UPDATE 11/2: potential helper at the beginning (or maybe end!) of your prompt!
(masterwork, x, y, z, masterpiece, best quality, hyper-detailed, 8k uhd::1.4), x = image type, i.e. sketch, photo, portrait, manga page, etc.
y = character name(s)
z = artist (if specified)
(followed by character count (1girl, 2girls), character description, location, action, other details)
Example:

(masterwork, portrait, princess midna, fan no hitori, award-winning, masterpiece, best quality, hyper-detailed, 8k uhd::1.4), 1girl, large breasts, blue eyes, skinny, slim, sexy, gaunt, smile, blue textured bodysuit, cleavage, fur trim, outdoors, castle, looking at viewer, anime coloring, shiny skin,Cinematic Light,
Negative prompt: lowres, worst quality, bad quality, bad anatomy, sketch, jpeg artifacts, signature, watermark, artist name, old, oldest
Steps: 26, baseModel: SDXL, quantity: 4, width: 832, height: 1216, Seed: 2455922073, draft: false, nsfw: true, workflow: txt2img, Clip skip: 2, CFG scale: 6, Sampler: Euler a, fluxMode: undefinedOkay so, Illustrious XL.
Been messing with it a ton lately and thought I'd share some stuff I've learned.
Overview
My testing has revealed several key differences from other model types like Pony:
Text generation is usually cleaner
backgrounds show better coherence
concept recognition = surprisingly robust
significant reduction in watermarks
importantly, negative prompts tend to behave better
though, as a trade-off, they are much more necessary
additionally, I can confirm, as others have found, both style and character training seem to produce more reliable results
On a subjective note, I've found that I just tend to like the images produced more versus something like Pony. Also, I find that it's just easier to work with and to get better images quickly.
Optimal Settings
Based on both testing and official documentation:
CFG Range: 4.5-7.5 (sweet spot around 5.5)
Recommended Sampler: Euler A
Steps: 20+ (24 recommended)
Working Prompt Structure
As I mentioned above, you definitely need to massage the prompt a bit more than most other models, at least at this point in time (Illustrious XL v0.1). As a result, you need to have quality tags in your positive prompt and a pretty extensive negative prompt to get it to work well.
Prompt Structure
Core Structure
Character count (1girl, 2girls, etc.)
Character names (if any)
Quality tags
Physical features & clothing
Pose & anatomical details
Environment/background
Additional quality/style tags
Positive prompt tags (put at end or beginning)
From the paper, their actual example quality tags are much simpler:
"masterpiece"
"general" (as an optional rating tag for safe for work images)
"absurdres"
"newest"
Technically these are all you need to produce a good image, according to the Illustrious paper. I've also corroborated this in my own testing.
However, I've found that these prompt tags can produce fairly consistent results when used in combination with those tags above:
perfect quality, best quality, absolutely eye-catching, and with more realistic/detailed imagery:
perfect quality, best quality, absolutely eye-catching, ambient occlusion, raytracing, ambient occlusion/raytracing help with 2.5d/semi-real style especially
Negative prompt
After a lot of experimentation, I found this works the best, on average, pretty much every time:
lowres, (bad), bad anatomy, bad hands, extra digits, multiple views,fewer, extra, missing, text, error, worst quality, jpeg artifacts, low quality, watermark, unfinished, displeasing, oldest, early,chromatic aberration, signature,artistic error, username, scanor as a shorter alternative:
lowres, worst quality, bad quality, bad anatomy, sketch, jpeg artifacts, signature, watermark, artist name, old, oldestFull prompt examples/gen data
Here's a couple examples to show how 90% of my prompts look:
Black Cat / Felicia Hardy (Spiderman) Lora example use:
1girl, felici4, anatomically correct, proper proportions,
long white hair, large breasts, domino mask, black lips, athletic build,
well-defined standing pose, dynamic pose,
detailed urban environment, night scene, city lights,
glowing blonde hair, blue eyes, looking at viewer, shining skin,
from below angle, professional lighting,
masterpiece, best quality, absurdres, newest
-or-
perfect quality, high quality, masterpiece, absolutely eye-catching, ambient occlusion, raytracing, felici4, 1girl, long hair, white hair, large breasts, (mask), domino mask, blue eyes, black lips, skinny, glowing blonde hair, rainbow inner hair, looking at viewer, shining glossy skin, perfect huge breast, (goosebumps:1.1), solo, excessive sweat, ((from below))
lowres, (bad), bad anatomy, bad hands, extra digits, multiple views,fewer, extra, missing, error, worst quality, jpeg artifacts, low quality, watermark, unfinished, displeasing, oldest, early,chromatic aberration, signature,artistic error, username, scan
Steps: 24, baseModel: SDXL, quantity: 4, width: 832, height: 1216, Seed: 1934634232, draft: false, nsfw: true, workflow: txt2img, Clip skip: 2, CFG scale: 5.5, Sampler: Euler a, Ashley Graham (Resident Evil 4 Remake) Lora example use:
1girl, ashley_grah4m, anatomically correct, proper proportions,
neon lighting, glowing blonde hair, rainbow inner hair, blue eyes,
well-defined pose, standing pose, balanced pose,
detailed environment, professional lighting, clear composition,
looking at viewer, seductive expression,
masterpiece, best quality, absurdres, newest
-or-
masterpiece, best quality, ashley_grah4m, 1girl, neon, glowing blonde hair, rainbow inner hair, blue eyes,looking at viewer, seductive
lowres, (bad), bad anatomy, bad hands, extra digits, multiple views,fewer, extra, missing, text, error, worst quality, jpeg artifacts, low quality, watermark, unfinished, displeasing, oldest, early,chromatic aberration, signature,artistic error, username, scan
Steps: 24, baseModel: SDXL, quantity: 4, width: 832, height: 1216, Seed: 1115576560, draft: false, nsfw: true, workflow: txt2img, Clip skip: 2, CFG scale: 5.5, Sampler: Euler a, Creating Effective Backgrounds
Based on paper findings and testing, backgrounds require specific attention:
Structure for Background Prompts:
Environment Base:
detailed environment, [location type], clear compositionArchitectural Elements:
[material types], [structural elements], [decorative elements]Lighting and Atmosphere:
[time of day], [lighting type], [atmosphere effects]Example Background Combinations:
Indoor Scenes:
luxurious room, detailed architecture, marble floor, ornate furniture,
crystal chandeliers, tall windows, decorative columns,
warm ambient lighting, soft shadows, volumetric lightingOutdoor Urban:
detailed cityscape, modern architecture, glass buildings,
city streets, urban details, store fronts,
night scene, neon lighting, street lamps, ambient occlusionNatural Settings:
detailed landscape, rolling hills, dense forest,
rocky outcrops, flowing water, detailed foliage,
golden hour lighting, atmospheric haze, dynamic cloudsFull Example:
1girl, sprThja, anatomically correct, proper proportions, full body, toned figure, large breasts, black hair, long flowing hair, rabbit ears, dark alluring eyes, confident smile, standing pose, well-defined pose, balanced pose, looking at viewer, purple leotard, deep cleavage, purple leggings, purple gloves, yellow cape, detached collar, luxurious detailed room, marble floor, ornate furniture, detailed architecture, night scene, professional lighting, warm ambient lighting, soft shadows, clear composition, masterpiece, best quality, absurdres, newest Background Best Practices:
Start with broad environment definition
Add specific architectural or natural elements
Include material descriptions
Define lighting and atmosphere
Maintain consistency with character lighting
Use environmental quality tags
Tips for Better Backgrounds:
Add depth indicators (foreground, midground, background)
Include atmospheric effects
Specify clear lighting sources
Use architectural details for indoor scenes
Add environmental context
Keep perspective consistent with character pose
Common Background Issues:
Inconsistent lighting between character and background
Perspective mismatches
Lack of detail in middle ground
Poor integration with character
Missing environmental context
Solutions:
Use consistent lighting descriptors
Add specific perspective tags
Include depth and distance markers
Specify material and texture details
Use architectural or natural anchoring elements
Known Issues
Multiple competing style tags tend to produce inconsistent results
Needs specific prompting to work well
Best Practices
Use those prompts from above!
Start with minimal parameters
Pay particular attention to lighting descriptors
Monitor CFG impact on output quality
My Own Training Examples
If you want to give them a try, here's some of my own models that I've trained on various Illustrious merges as well as Illustrious itself:
CicaLust: A style implementation focusing on anime/shiny skin, much like my CicaStyle style Lora for Pony
Additional help re: Angles/Lighting
angles, use/mix these after quality tags at beginning of prompt:
from above,
from below,
close-up,
portrait,
POV,
birds-eye,
wide shot,
isometric,
(+ view, depending)
lighting, after angle tags, beginning or very end of prompt:
Cinematic Light,
Hollywood Lighting,
Backlighting,
Rim lighting,
Soft lighting,
harsh lighting,
Dramatic light,
film-style contrast,
soft shadows,
harsh shadows,
(you may have to fiddle with the position and wording of those, but they should mostly work as is)
Conclusion
Since this is a very new model, expect ongoing discoveries about optimal usage patterns.
Feel free to ask questions or share your own findings and experiments!