El programa básicamente copia el código fuente de las imágenes, filtrando los caracteres que no interesan y de tal forma permite obtener los promps de las imágenes de forma bastante sencilla y rápida, sin tener que ir al weibu. El programa solo permite ver el código fuente, por lo que podrás ver los tags solo si fueron salvados en la imagen al momento de su creación, igual que como hace civitai.
Ahora puede subir varios archivos a la vez y indica el progreso de una forma mas interesante
import re
from google.colab import files
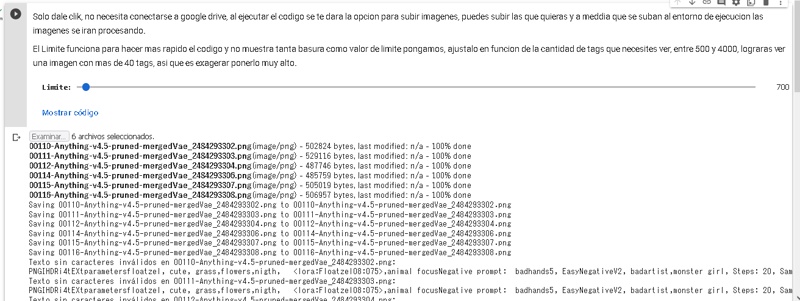
#@markdown Solo dale clik, no necesita conectarse a google drive, al ejecutar el codigo se te dara la opcion para subir imagenes, puedes subir las que quieras y a meddia que se suban al entorno de ejecucion las imagenes se iran procesando.
#@markdown
#@markdown El Limite funciona para hacer mas rapido el codigo y no muestra tanta basura como valor de limite pongamos, ajustalo en funcion de la cantidad de tags que necesites ver, entre 500 y 4000, lograras ver una imagen con mas de 40 tags, asi que es exagerar ponerlo muy alto.
import ipywidgets as widgets
def eliminar_caracteres_invalidos(texto):
texto_limpio = re.sub(r'[^a-zA-Z0-9,:<> ]', '', texto)
return texto_limpio
def extraer_primeros_500_bytes(imagen_bytes):
Limite = 700 #@param {type:"slider", min:500, max:25000, step:100}
primeros_500_bytes = imagen_bytes[:Limite] # Limitar a los primeros 500 bytes
try:
texto_sin_caracter = eliminar_caracteres_invalidos(primeros_500_bytes.decode('utf-8'))
except UnicodeDecodeError:
texto_sin_caracter = eliminar_caracteres_invalidos(primeros_500_bytes.decode('latin-1'))
return texto_sin_caracter
# Función para subir archivos a Colab
def cargar_archivos():
archivos = files.upload()
return archivos
# Código principal
archivos = cargar_archivos()
for nombre_archivo, contenido_archivo in archivos.items():
imagen_bytes = contenido_archivo
texto_sin_caracter = extraer_primeros_500_bytes(imagen_bytes)
print(f"Texto sin caracteres inválidos en {nombre_archivo}:")
print(texto_sin_caracter)