
Video Dataset Preparation Tools:
A Fine tuning guide will be written up once i have more experience with this:
you should refer to my WIP rewritten guide or the official docs.
Mochi1 Video dataset Preprocessor (webUI)
https://github.com/MushroomFleet/Mochi1-Video-Dataset-Builder
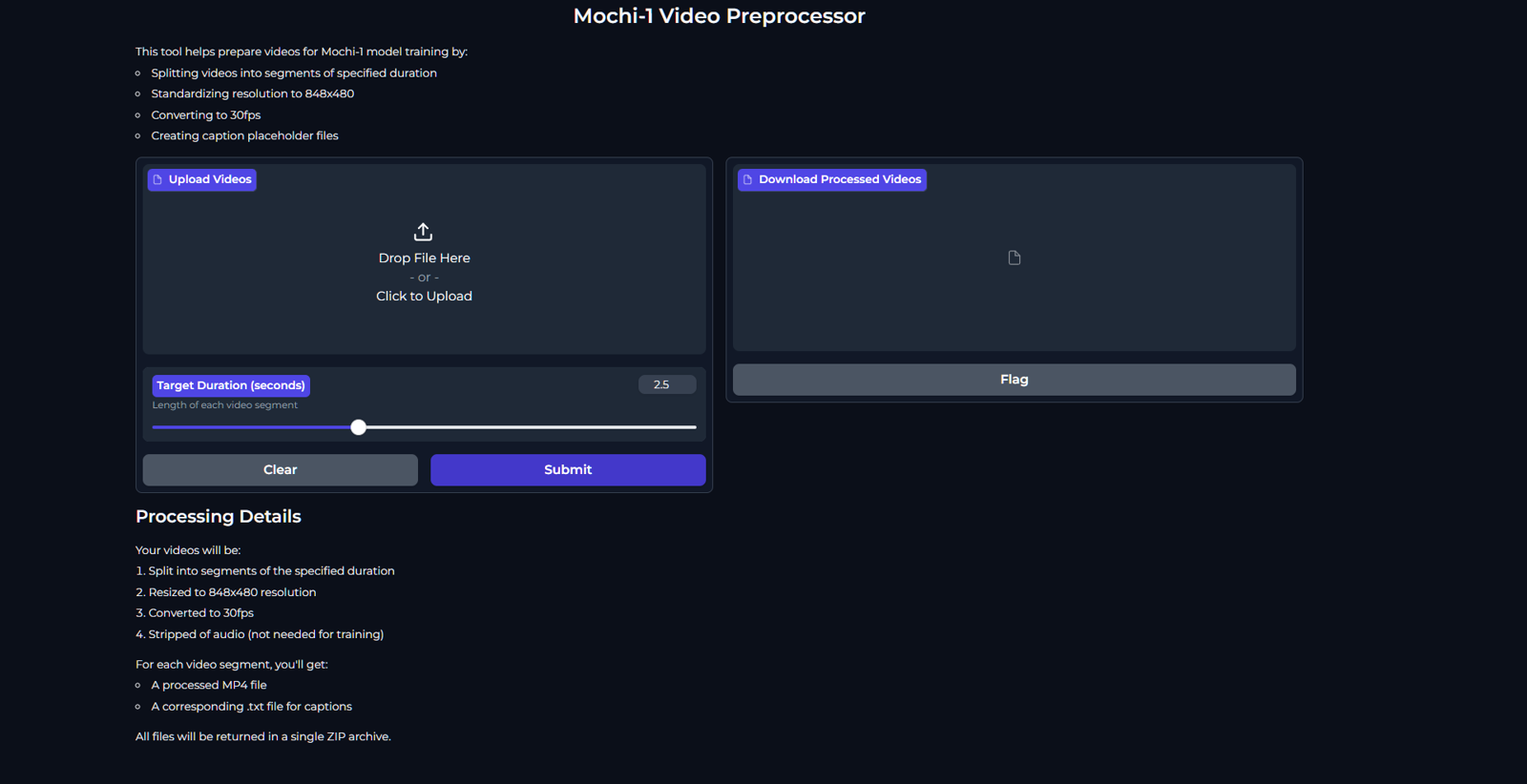
This article will give a brief explanation of my new Mochi1 dataset preparation process. Creating datasets can be a time sink so i have built some automations that can help you. We will use the webUI to convert videos into well captioned and properly formatted 2.5 second video segments. It will process long videos in sequence and retain the order in 848x640 at 30 FPS, as per the recommended specifications for training with Mochi1.
Captions will be empty as this tool only deals with the video segmentation and processing.
The readme on the github repo linked above has full instructions for the video dataset builder webUI.
For the Captioning side of things, I have created several workflows. The workflows are linked below on my github, but will be rolled into the next Foda Flux Pack update.
The first workflow is V30, this was made from nodes that were already existing and presented a few challenges in that the save text node was unable to create folders, so i had to make them myself manually. Also I wanted a better way to batch load videos from a folder and queue up the jobs so it can be done in silent/unattended mode, by adding a job queue of the same length as the number of videos in a folder.
I later created new nodes which are now released in my DJZ-Nodes pack. One is an updated version of the Save Text node, which can create directories, solving that first snag. The second is Load Video Batch Frame, which allowed an index for batch increment through videos in a folder location, while also allowing frame selection by number & the video filename to be passed easily to the text filename. This V50 workflow version does everything i needed for the "Full-Auto" video captioner.
While you can use Florence 2 to process the extracted Frame as an image (less overhead for smaller systems and much faster) I have used Llava-OneVision-Qwen2 in the example workflow, as my "image-to-video" LLM base prompt does well introducing temporal element using only the first Frame from a video segment. Feel free to remove OneVision and use Florence2 is you find that to work best for you.
I will likely add a Florence2 version for use by people unsure how to swap out OneVision.
Note, the OneVision prompt may include additional instructions from the template linked above
- 240 token limit
- Outputs must be a sinlge paragraph
Once you have created the Captions, they will have the same filenames as the video captions, copy and overwrite the empty once, now you should be ready to start training with the official training scripts
TLDR:
1. Use webui with video you want to train
2. Download segmented (prepared) video and empty text captions
3. Load the videos into my ComfyUI Captioner workflow
4. Overwrite the empty captions with your captioned text files.
> Start Training Lora with Mochi