

Part 2 followup (Work in progress)
This is a slightly more distilled continuation of
https://civitai.com/articles/8690/xlsd-creation-saga
where I take the base SD1.5 model, slap the SDXL vae on the front, and then retrain to make them compatible.
No adjustment of model parameters on either side is neccessary. sdxl vae is drop-in replaceable for the sd1.5 vae. It just doesnt give compatible values out of the box.
Currently, the banner for this article, shows out-of-the-box output, vs a few hours of training.
(using fp32, effective batch size 256, on a 4090)
Mysteries of initial training
I was originally planning to do an initial round of high-LR value training, to get the combination of "new" vae and old unet at least outputting sane colors. Then I was going to tune for more details.
I had spent a lot of time refining a clean mini dataset out of the huge CC12m public dataset for this purpose.
However, after running the phase1 and phase 2 training, I happened to compare the loss graphs, and found something shocking:
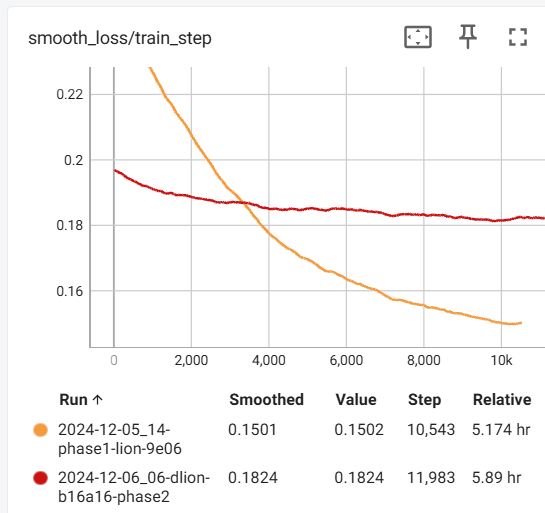
I expected the "phase 2" training to have lower loss numbers.. especially since I was training on literally the same data. But it had HIGHER loss. What???
I thought perhaps this was because phase2 was at a lower LR than phase 1. So I ran it again, and forced an equal learning rate.
The loss curve did not change.
Presumed EMA-like values for LION
I had previously experimented with smaller scale training, and so was familar with the idea of EMA: the concept of training keeping a special "moving average" of how training was going, that is seperate from, yet guides, the regular training.
I was not using EMA. However, It appears that in some ways, LION keeps its own hidden gradient momentum of some kind (at least for large scale training?) And unlike EMA values, that information is not saved in the checkpoint to potentially be picked up by subsequent training
This means that if you restart the training after saving a checkpoint... a lot of important information is lost.
The path forward
Because of the above information, I am now restructuring my training plans (at least for THIS dataset), to start it at high LR, then use decay of some sort for a long run.
I am currently testing to see if a start value for LR is best at 2e-05 or 1.5e-05
This is with a dataset of around 140,000 images, using LION, Cosine scheduler, 6 epochs.
Batchsize 16, accum 16 (for effective batchsize of 256)
The path backward
I was enjoying seeing much improved variety.. although a lack of fine detail.
Based on my reading, I thought that using the scheduler to gradually drop the LR back to lower rates I was using previously, would then improve the detail on the more interesting samples I had been getting.
Instead, to my horror, I observed that when the LR finally dropped back to the "normal" ranges, like 6e-06... I see a very familiar one-armed figure I have seen uncountable times before.
What's the point of all this high-LR training, if it is not going to train OUT this monster??

left is an example of high-LR results. Right side is after 20k steps, when it has dropped back down to 9e-06.. and the same horror appears, like a cursed "bad penny" :(
The path through
I decided to continue the training.
"Peggy" went away.
The model from that run, WITH ye olde sd1.5 negative prompts, gives results like this:

Prompt:
a woman enjoying a coffee in a cafe,best quality,masterpiece,4kNegatives:
low quality,blurry,lowres, error, cropped, worst quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, out of frame, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry,Oddly, during-training-samples with OneTrainer are somehow giving me better results in some areas than the final model at the moment.

But this is still a work in progress.
Phase 1 current model settings
My base of "phase 1" was generated with:
LION, Effective batch size 256 (b16,accum16), LR 2e-05, const
4 epochs, 38,000 total steps, 150k images
Phase 2 choices
I didnt seem to be getting the detail level that I wanted with larger batch sizes after my "phase 1" training.
So I gave up on large batch, and instead focused on a very small select dataset, and small batch: b=4
I also decided to push it out to 50 epochs. But.. I accidentally set Linear as the scheduler.
Needle in the haystack
So, for this phase 2 run, LION, b=4, LR 2e06, Linear, e=50, running over a small carefully filtered high quality "woman" dataset of around 9k images.
Around 8 epochs, I got this:

What? Something decent, in the middle of mediocre and mediocre.
So now I get to rerun the training from the start, picking the random super low loss point that happened near this sampling point. Near but not at 18k steps.
And the results are in!
Cherry picking, but no negative prompt (on an SD1.5 model!!), gives me this:

( "woman,cafe, drinking coffee,long hair,beautiful face")
(euler, cfg 7 steps 20)
(Note to self: this image was from the point mentioned above: phase2, LION, b=4, LR 2e06, Linear, e=50, but actually checkpointed at 17780 steps in that training run)
Further experiments
Currently rerunning with const instead of linear to compare.
.. its kinda better... but turns out, switching to D-LION is even better, usually
Dataset adjustments
I have been trying to do the phase2 stuffs with a mixture of hand-selected images from Pexels, and hand-selected images from CC12m (well, actually, from the specific subset at https://huggingface.co/datasets/opendiffusionai/cc12m-a_woman )
I think that going forward, I will concentrate on only 1-megapixel-and-larger images from CC12m, even though I am currently only training at 512x512
This will make the dataset more generally usable, and also give me more of a hope of maybe finishing the selecting-out process in my lifetime.
If I was going super-crazy, I might instead, or also, create a 4mp-only dataset. The quality of training I'm getting from JUST the pexel images, is awesome. Only trouble is, there are much fewer of them.
That's probably a combination of higher res, but also the quality of pexels photograph is just plain better anyway.
More dataset adjustments
Turns out, if I just filter out everything under 4megapixels from the CC12M set... what is left, is pretty impressive!
Still needs a little cleanup.. but its more like 3% bad instead of 20% bad.
Work in progress, at https://huggingface.co/datasets/opendiffusionai/cc12m-4mp
No ultra-wide
I am also filtering out everything with a larger aspect rato of 1.77
Basically anything more stretched than 16:9 will be skipped. I dont think little baby SD1.5 will do well training on data that is ultra-wide. It just gets wasted for the majority of uses. Save the parameter count for more useful things!
2024-12-20 Update
I have determined that it was a mistake to train on the CC12M 4Mp images just yet, because they are too complex for optimal learning for a dumb-stage model.
So, I am retraining "phase2" to use DLION, b4, fp32, over the
https://huggingface.co/datasets/opendiffusionai/pexels-photos-janpf
dataset (but I additionally strip out all black and white photos, because I'm tired of output randomly going monochrome). I am also changing the Loss Function from the default "constant" to "Debiased Estimation", because supposedly thats the state of the art now.
My plan is to get the model trained up for quality on humans, then run it with the CC12M stuff for wider knowledge base.
Trouble is, I'm averaging around 7 hours per epoch. And I'm seeing what happens when I train it all the way out to 50 epochs.
Sigh.
Cherrypick around 12,000 steps (4 epochs)

Remember aspect ratios
My prior samples were terrible because I was using the default 512x512 size. However, virtually none of my training images are square. So, changing sample size to 3:4 showed me more interesting output, like the above.
Gradient checkpointing
Reminder: when using batchsize 4 or less on 24gigs VRAM and 512x res, UNset gradient checkpointing, for a 10% speed boost.
Note on Dadapt-LION vs LION
Tradeoffs involved when choosing between these two optimizers.
Yes they are mostly similar. However:
LION uses a little less memory. So sometimes you can squeeze things into LION, but not D-LION
D-LION sometimes gives a little better quality
OneTrainer seems to have a bug for backups. If you resume from a backup, LION will give you identical results. However, a backup from D-LION will be slightly inferior. Some context is lost somewhere.
Part 3
https://civitai.com/articles/10292/xlsd-sd15-sdxl-vae-part-3