Download
1 variant available




License:

https://huggingface.co/deepseek-ai/Janus-Pro-1B
https://huggingface.co/deepseek-ai/Janus-Pro-7B
Note: The CY-CHENYUE/ComfyUI-Janus-Pro nodes doesn't support .safetensors.
So I updated/forked the model_loader.py to automatically download, and support .safetensors. It refused to let me rename the files, so you need to keep them named model.safetensors
For the 7B version, I could not get shard-merging to work. So they will be sharded in 3 parts.
Installation instructions
Install ComfyUI
Install the CY-CHENYUE/ComfyUI-Janus-Pro node-pack
Manually overwrite the
model_loader.pyinComfyUI\custom_nodes\ComfyUI-Janus-Pro\nodes\model_loader.pywith the one aboveYou can use the ComfyUI Workflow above
The updated model_loader script will automatically download the model and place it in the correct folder
To do it manually, unzip the files for your desired version in the model list above so that the folder structure looks something like the screenshot below.
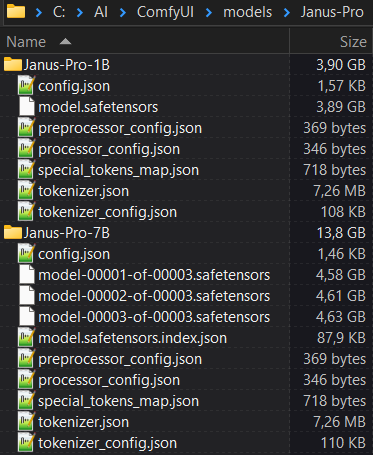 So the model path for the 1B version should be:
So the model path for the 1B version should be:
ComfyUI/models/Janus-Pro/Janus-Pro-1B/model.safetensors
But remember that you also need the config and the rest of the files, which is why it's uploaded as a .zip
There's also a version that is just the support-files, if you would rather combine that with the original .bin checkpoint models.
Congratulations!
With a 3090, 24gb, you can enjoy speedy 8-minute generations for a 384x384 image that looks much worse than anything Stable Diffusion 1.5 spits out in 0.5 second.
Janus-Pro is a novel autoregressive framework that unifies multimodal understanding and generation. It addresses the limitations of previous approaches by decoupling visual encoding into separate pathways, while still utilizing a single, unified transformer architecture for processing. The decoupling not only alleviates the conflict between the visual encoder’s roles in understanding and generation, but also enhances the framework’s flexibility. Janus-Pro surpasses previous unified model and matches or exceeds the performance of task-specific models. The simplicity, high flexibility, and effectiveness of Janus-Pro make it a strong candidate for next-generation unified multimodal models.Janus-Pro is a unified understanding and generation MLLM, which decouples visual encoding for multimodal understanding and generation. Janus-Pro is constructed based on the DeepSeek-LLM-1.5b-base/DeepSeek-LLM-7b-base.For multimodal understanding, it uses the SigLIP-L as the vision encoder, which supports 384 x 384 image input. For image generation, Janus-Pro uses the tokenizer from here with a downsample rate of 16.This is the converted .safetensors version of the model.
The original 7B ones can be found here: https://huggingface.co/deepseek-ai/Janus-Pro-7B/tree/e6ac502c7931490e5b56b0ff2d30413f2a21b887