Download
1 variant available

101
439
6.6K

Tencent Hunyuan is licensed under the Tencent Hunyuan Community License Agreement, Copyright © 2024 Tencent. All Rights Reserved. The trademark rights of “Tencent Hunyuan” are owned by Tencent or its affiliate.
Powered by Tencent Hunyuan
UPDATE: Improved notes and user experience. Let me know what you think.
Also I will be tipping Buzz to everyone who upload and tags the model, show me you beautiful work! :)
V1.5 720P is out: information on previous version right after.
I've added ComfyUI-MultiGPU, and it's a game-changer! This advancement allows you to run Hunyuan at resolutions that were previously impossible. Performance on my workflow was already solid, but with this addition and with sage anttention enabled I managed to get these generation times
3090 24 gb of ram. 97 frames, 24 fps, two LoRAs loaded.
720x480 217 secs ( 3.6 minutes )
960x544 362 secs (6 minutes)
1240x720 800 secs (13 minutes)
Credit to firemanbrakeneck for teaching me how to install sage, this is the guide you need but it is a pain in the ass.
Full credit to Silent-Adagio-444, the mastermind behind this plugin, who also helped me implement and fine-tune it for my workflow.
I'll keep the instructions as simple and brief as possible. You'll need to experiment with the node settings depending on your system.
Instructions:
Install ComfyUI-MultiGPU via Comfy Manager or Git.
install ComfyUI-GGUF (this is required!)
Download the GGUF version of the LLM from this link and place it in the Unet folder.
Set up UnetLoaderGGUFDisTorchMultiGPU. I have it set to 4.5, but if you have a lower VRAM card, you may need to increase this number. Experiment to find the best value for your system.
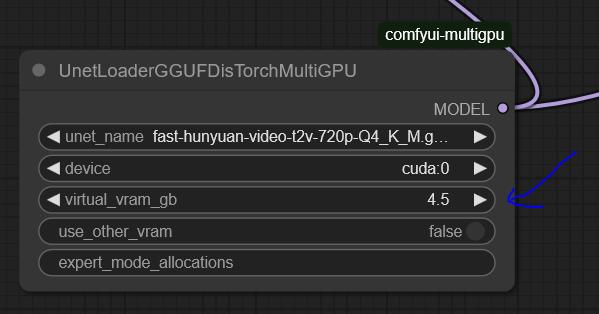
the settings here are optimized for my system: RTX 3090 (24GB VRAM) and 64GB RAM.
You'll need to tweak the settings to find the optimal configuration for your hardware.
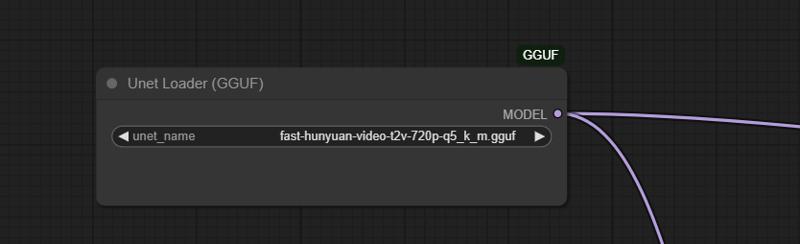
For 720p, I use Fast Hunyuan GGUF Q4_K_M.
The less VRAM you allocate, the slower it will be. No free lunch!
Find the optimal balance for your setup.
General info about the workflow and the previous version:
Hi everyone, Bizarro here after countless hours of optimization, I’m happy to share the workflow I’ve been using to extract maximum quality and performance from Hunyuan.
Credit where it's due, this workflow is based on This youtuber workflow I’ve been tweaking settings for weeks to get the best quality possible.
I’ve also finally solved the issues many had with multiple LoRAs! 🚀 You can mix up to three LoRAs without losing quality and even put several characters in the same scene. It works best with two, but I managed to do three in the example (Bizarro LoRA, Wonder Woman LoRA, and Thanos LoRA).
Clarification: I got a bit lucky with the example generation was the first attempt actually I have since discovered it is hard to juggle the LoRAs for consistent results. the Workflow is very fast and the results are pretty great. I will add more examples as I create them. The workflow is great for combining a Lora style with a Lora character as well.
You have to work properly with the prompt make sure you describe the characters, for instance "a Caucasian male" clothes, body size etc, where the character is situated in the frame.
This workflow is highly optimized for a 3090 and can generate 97 frames at 960x544 in less than eight minutes. If you’re using a card with less RAM, try using a different smaller GGUF version or and reduce quality to 480p.
[For more experiments follow me on X
I ramble all day about video generation and also create funny videos.]
This is the GGUF version I’m using, and you can get it here: here:
 I tried many LoRA nodes, but they were all really bad. The final breakthrough came when I found this node:
I tried many LoRA nodes, but they were all really bad. The final breakthrough came when I found this node:
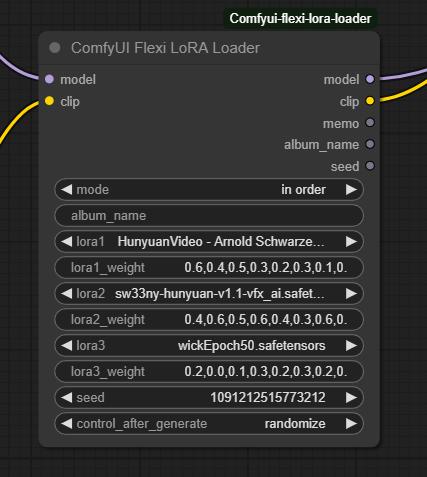 Make sure to set the mode to "In Order." Just select the LoRAs you want and describe each character in detail using the proper trigger words.
Make sure to set the mode to "In Order." Just select the LoRAs you want and describe each character in detail using the proper trigger words.
Multiple LoRA weight values correspond to different steps in the denoising process, controlling how much influence the LoRA has at each stage. Higher weights in early steps shape the overall structure, while later weights refine details. This allows for more nuanced blending, ensuring that a LoRA’s effect isn't applied uniformly but adapts dynamically throughout the image or video generation process.
It works really well with two characters, but if you’re patient, you can make it work with three as well.
This will work not only for characters but also for all kinds of loras.
This works not only for characters but for all kinds of LoRAs.
I’d love to see what you come up with!
Love,

Mr. Bizarro