Download
1 variant available
fp16 SafeTensor
Illustrious-XL-v1.0.safetensors
Half precision, best balance (pruned) • 6.46 GB
Verified: a year ago


License:
Illustrious License
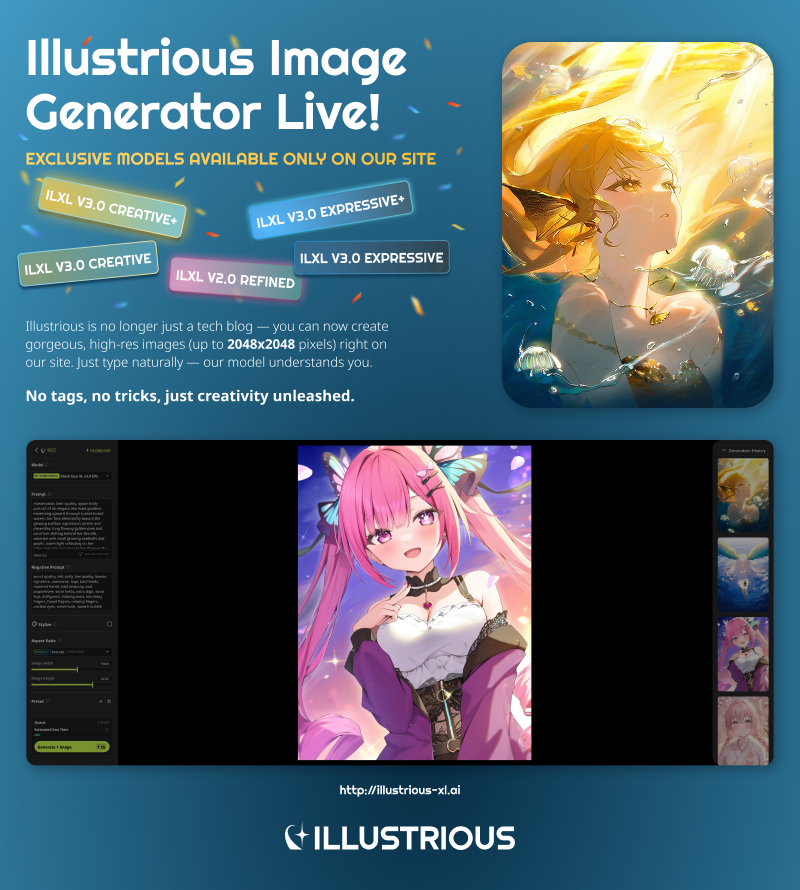 Check out our website to see what we’ve been working on and explore our latest model!
Check out our website to see what we’ve been working on and explore our latest model!
→https://www.illustrious-xl.ai/
We’re excited to share that you can now generate images directly with our Illustrious XL models on our official site: [illustrious-xl.ai]. We’ve launched a full image generation platform featuring high-res outputs, natural language prompting, and custom presets — plus, several exclusive models you won’t find on any other hub. Explore our updated model tiers and naming here: [Model Series]. Need help getting started? Check out our generation user guide: [ILXL Image Generation User Guide].
Illustrious XL v1.0 – High-Resolution focused Illustration Generative Model
Overview
Illustrious XL v1.0 is a cutting-edge generative model developed by OnomaAI, built on the Stable Diffusion XL architecture, trained from our previous checkpoint, Illustrious XL v0.1, designed to produce stunning high-resolution images. It achieves an unprecedented native resolution of 1536×1536 within the SDXL framework, pushing beyond previous limits in detail and clarity. The model seamlessly blends natural language understanding with tag-based prompting (Danbooru style), allowing both descriptive sentences and specific tags for flexible, robust prompt handling. As a result, Illustrious XL v1.0 is a powerful foundation for creators seeking versatility in content generation without sacrificing fidelity.
Knowledge Cutoff
Illustrious XL v1.0 is trained in 2024-July, with knowledge up to 2024-June.
However, due to its native support of v0.1 LoRA, you might not have to worry about knowledge limits!
Key Features
1536×1536 Native Resolution:
First-of-its-kind Stable Diffusion XL model to natively support 1536px resolution. Generates images with exceptional detail, sharpness, and clarity at high resolutions that were previously unattainable in SDXL. It supports wide range of resolution between 512x512 to 1536x1536 - resolution such as 1248x1824 is capable without any high-resolution modifications.
NLP + Tag-Based Prompting:
Integrates advanced natural language processing with Danbooru tag-based prompts. Still, tag-based approaches are more concise and accurate - but this hybrid prompt system means you can use plain English descriptions or precise tags (or both) – the model understands and leverages each, giving you greater control and nuance in image generation.
Extensive Compatibility:
Fully compatible with a wide range of extensions and add-ons. LoRA, ControlNet modules, and other adaptation methods trained on Illustrious v0.1 work seamlessly with v1.0. You can mix and match enhancements to fine-tune style, pose, or composition without breaking compatibility.
Pretrained Base Model:
Illustrious XL v1.0 is provided as a pretrained base checkpoint without any fine-tuning on specific aesthetics or biases. This "raw" model offers a robust foundation for further training – ideal for creators who want to apply their own fine-tuning (e.g. LoRA training) to achieve particular art styles or specialized outputs. It's a flexible starting point for new innovations.
Future Plans
Higher Resolutions in v2/v3:
Upcoming versions (Illustrious XL v2 and v3) are planned to be released, supporting even larger resolutions, targeting up to 2k resolution and beyond. Expect even more detail and scaling capability, enabling ultra-crisp large-format images.
v-parameterization Models & Color Control:
A specialized v-parameterization variant is ready, which breakthroughs SD XL's previously considered limit, both academically and practically. Alongside this, future releases will focus on enhanced color control, giving users finer adjustment over color balance and consistency in generated images.
Continuous Improvement:
The Illustrious roadmap is ambitious – each iteration will integrate community feedback and the latest research. We will continue high-resolution research with breaking previously considered walls, with careful and sophisticated approaches.
Illustrious v0.1 (huggingface) | OnomaAI TooToon | Terms of use