Download
1 variant available


2.5K
33.5K
545.4K

.jpeg)
Model Introduction (英文部分)
I Contents
In this introduction, you'll learn about:
Model information (see Section II);
Instructions for use (see Section III);
Training parameters (see Section IV);
List of Trigger Words (see Appendix Part A)
II AIDXL
Anime Illustration Diffusion XL, or AIDXL, is a model dedicated to generating stylized anime illustrations. It has over 800 (with more and more updates) built-in illustration styles, which are triggered by specific trigger words (see Appendix A).
Advantages:
Flexible composition rather than traditional AI posing.
Skillful details rather than messy chaos.
Knows anime characters better.
III User Guide
1 Basic usage
1.1 Prompt
Trigger words: Add the trigger words provided in Appendix A to stylize the image. Suitable trigger words will greatly improve the quality;
It's recommended to reduce weight to artist style trigger words, e.g. (by xxx:0.6).
Semantic sorting: Sorting your prompt tags or sentences will help the model understand your meaning.
Recommended tag order: Trigger word (by xxx) -> character (a girl named frieren from sousou no frieren series) -> race (elf) -> composition (cowboy shot) -> style (impasto style) -> theme (fantasy theme) -> main environment (in the forest, at day) -> background (gradient background) -> action (sitting on ground) -> expression (is expressionless) -> main characteristics (white hair) -> body characteristics (twintails, green eyes, parted lip) -> clothing (wearing a white dress) -> clothing accessories (frills) -> other items (a cat) -> secondary environment (grass, sunshine) -> aesthetics (beautiful color, detailed, aesthetic) -> quality ((best quality:1.3))
Negative prompts: (worst quality:1.3), low quality, lowres, messy, abstract, ugly, disfigured, bad anatomy, draft, deformed hands, fused fingers, signature, text, multi views
1.2 Generation Parameters
Resolution: Ensure the total number of pixels (=width * height) to be around 1024*1024 and the width and height to be the division of 32, in which case AIDXL will produce the best result. For example, 832x1216 (2:3), 1216x832 (3:2), and 1024x1024 (1:1), etc.
Sampler and steps: Use the "Euler Ancester" sampler, which is called Euler A in webui. Sampled around ~28 steps on 7 to 9 CFG Scale.
'Refine': The image generated from text2image is sometimes blurry, in which case you need to 'refine' it using image2image or inpainting etc.
For simple scaling up, you may refer to: Upscale to huge sizes and add detail with SD Upscale, it's easy! : r/StableDiffusion (reddit.com)
Other components: No need to use any refiner model. Use VAE of the model itself or the
sdxl-vae.
Q: How to reproduce the model cover? Why cannot I reproduce a same picture as the cover using the same generation parameters?
A: Because the generation parameters shown in the cover are NOT its text2image parameter, but the image2image (to scale up) parameter. The base image is mostly generated from the Euler Ancester sampler rather than the DPM sampler.
2 Special usage
2.1 Generalized Styles
From version 0.7, AIDXL summarizes several similar styles and introduces generalized-style trigger words. These trigger words each represent a common animation illustration style category. Please note that general style trigger words do not necessarily conform to the artistic meaning that their word meaning refers to but are special trigger words that have been redefined.
2.2 Characters
From version 0.7, AIDXL has enhanced training for characters. The effect of some character trigger words can already achieve the effect of Lora, and can well separate the character concept from its own clothing.
The character triggering method is: {character} \({copyright}\). For example, to trigger the heroine Lucy in the animation "Cyberpunk: Edgerunners", use lucy \(cyberpunk\); to trigger the character Gan Yu in the game "Genshin Impact", use ganyu \(genshin impact\). Here, "lucy" and "ganyu" are character names, "\(cyberpunk\)" and "\(genshin impact\)" are the origins of the corresponding characters, and the brackets are escaped with slashes "\" to prevent them from being interpreted as weighted tags. For some characters, copyright part is not necessary.
From version v0.8, there's another easier triggering method: a {girl/boy} named {character} from {copyright} series.
For the list of character trigger words, please refer to: selected_tags.csv · SmilingWolf/wd-v1-4-convnext-tagger-v2 at main (huggingface.co). Also, some extra trigger words that are not mentioned in this document may also be included.
Some character requires extra triggering step. When using, if the character cannot be completely restored with a single character trigger word, the main characteristics of the character need to be added to the prompt.
AIDXL supports character dressing up. Character trigger words usually do not carry the clothing characteristics concept of the character itself. If you want to add character clothing, you need to add the clothing tag in the prompt word. For example, silver evening gown, plunging neckline gives the dress of character St. Louis (Luxurious Wheels) from game Azur Lane. Similarly, you can add any character's clothing tags to those of other characters.
2.3 Quality Tags
Quality and aesthetic tags are formally trained. Trailing them in prompts will affect the quality of the generated image.
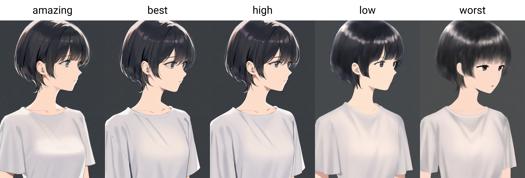
From version 0.7, AIDXL officially trains and introduces quality tags. Qualities are divided into six levels, from best to worst: amazing quality, best quality, high quality, normal quality, low quality and worst quality.
It's recommended to add extra weight to quality tags, e.g. (amazing quality:1.5).
2.4 Aesthetic Tags
Since version 0.7, aesthetic tags have been introduced to describe the special aesthetic characteristics of images.
2.5 Style Merging
You are able to merge some styles into your customized style. 'Merging' actually means use multiple style trigger words at one time. For example, chun-li, amazing quality, (by yoneyama mai:0.9), (by chi4:0.8), by ask, by modare, (by ikky:0.9).
Some tips:
Control the weight and order of the styles to adjust the style.
Append rather than prepend to your prompt.
IV Training Strategy & Parameters
AIDXLv0.1
Using SDXL1.0 as the base model, using about 22k labeled images to train about 100 epochs on a cosine scheduler with a learning rate of 5e-6 and a number of cycles = 1 to obtain model A. Then, using a learning rate of 2e-7 and the same other parameters to obtain model B. The AIDXLv0.1 model is obtained by merging model A and B.
AIDXLv0.51
Training Strategy
Resume training from AIDXLv0.5, there are three runs of training pipelined one by one:
Long caption training: Use the whole dataset, with some images captioned manually. Start training both the U-Net and the text encoder with the AdamW8bit optimizer, a high learning rate (around 1.5e-6) with cosine scheduler. Stop training when the learning rate decays below a threshold (around 5e-7).
Short caption training: Restart training from the output of step 1. with the same parameters and strategy but a dataset with a shorter caption length.
Refining step: Prepare a subset of the dataset in step 1. that contains manually picked images of high quality. Restart training from the output of step 2. with a low learning (around 7.5e-7), with cosine scheduler with restarts 5 to 10 turns. Train until the result is aesthetically good.
Fixed Training Parameters
No extra noise like noise offset.
Min snr gamma = 5: speed up training.
Full bf16 precision.
AdamW8bit optimizer: a balance between efficiency and performance.
Dataset
Resolution: 1024x1024 total resolution (= height time width) with a modified SDXL officially bucketing strategy.
Captioning: Captioned by WD14-Swinv2 model with 0.35 threshold.
Close-up cropping: Crop images into several close-ups. It's very useful when the training images are large or rare.
Trigger words: Keep the first tag of images as their trigger words.
AIDXLv0.6
Training Strategy
Resume training from AIDXLv0.52, but with an adaptive repeating strategy - For each captioned image in the dataset, increase its number of repeats in training subject to the following rules:
Rule 1: The higher the image's quality, the more its number of repeats;
Rule 2: If the image belongs to a style class:
If the class is not yet fitted or underfitted, then manually increase the number of repeats of the class, or automatically boost its number of repeats such that the total number of repeats of the data in the class reaches a certain preset value, which is around 100.
If the class is already fitted or overfitted, then manually decrease the number of repeats of the class by forcing its number of repeats to 1 and drop it if its quality is low.
Rule 3: Its number of repeats limit its final number of repeats to not exceed a certain threshold, which is around 10.
This strategy has the following advantages:
It protects the model's original information from new training, which holds the same idea to the regularized image;
It makes the impact of training data more controllable;
It balances the training between different classes by motivating those not yet fitted classes and preventing overfitting to those already fitted classes;
It significantly saves computation resources, and make it much easier to add new styles into the model.
Fixed Training Parameters
Same as AIDXLv0.51.
Dataset
The dataset of AIDXLv0.6 is based on AIDXLv0.51. Furthermore, the following optimization strategies are applied:
Caption semantic sorting: Sort caption tags by semantic order, e.g. "gun, 1boy, holding, short hair" -> "1boy, short hair, holding, gun".
Caption deduplicating: Remove duplicate tags, keep the one that retains the most information. Duplicate tags means tags with similar meaning such as "long hair" and "very long hair".
Extra tags: Manually add additional tags to all images, e.g. "high quality", "impasto" etc. This can be quickly done with some tools.
V Special thanks
Computing power sponsorship: Thanks to @NieTa community (捏Ta (nieta.art)) for providing computing power support;
Data support: Thanks to @KirinTea_Aki (KirinTea_Aki Creator Profile | Civitai) and @Chenkin (Civitai | Share your models) for providing a large amount of data support;
There would be no version 0.7 without them.
VI AIDXL vs AID
2023/08/08. AIDXL is trained on the same training set as AIDv2.10, but outperforms AIDv2.10. AIDXL is smarter and can do many things that SD1.5-based models cannot. It also does a really good job of distinguishing between concepts, learning image detail, handling compositions that are difficult or even impossible for SD1.5 and AID. Overall, it is absolute potential. I'll keep updating AIDXL.
VII Sponsorship
If you like our work, you are welcome to sponsor us through Ko-fi(https://ko-fi.com/eugeai) to support our research and development. Thank you for your support~
模型介绍(Chinese Part)
I 目录
在本介绍中,您将了解:
模型介绍(见 II 部分);
使用指南(见 III 部分);
训练参数(见 IV 部分);
触发词列表(见附录 A 部分)
II 模型介绍
动漫插画设计XL,或称 AIDXL 是一款专用于生成二次元插图的模型。它内置了 800 种以上(随着更新越来越多)的插画风格,依靠特定触发词(见附录 A 部分)触发。
优点:构图大胆,没有摆拍感,主体突出,没有过多繁杂的细节,认识很多动漫人物(依靠角色日文名拼音触发,例如,“ayanami rei”对应角色“绫波丽”,“kamado nezuko”对应角色“祢豆子”)。
III 使用指南(将与时俱进)
1 基本用法
1.1 提示词书写
使用触发词:使用附录 A 所提供的触发词来风格化图像。适合的触发词将 极大地 提高生成质量;
提示词标签化:使用标签化的提示词描述生成对象;
提示词排序:排序您的提示词将有助于模型理解词义。推荐的标签顺序:
触发词(by xxx)->主角(1girl)->角色(frieren)->种族(elf)->构图(cowboy shot)->风格(impasto)->主题(fantasy)->主要环境(forest, day)->背景(gradient background)->动作(sitting)->表情(expressionless)->主要人物特征(white hair)->人体特征(twintails, green eyes, parted lip)->服饰(white dress)->服装配件(frills)->其他物品(magic wand)->次要环境(grass, sunshine)->美学(beautiful color, detailed, aesthetic)->质量(best quality)
负面提示词:worst quality, low quality, lowres, messy, abstract, ugly, disfigured, bad anatomy, deformed hands, fused fingers, signature, text, multi views
1.2 生成参数
分辨率:确保图像总分辨率(总分辨率=高度x宽度)围绕1024*1024且宽和高均为32的倍数。例如,832x1216 (3:2), 1216x832 (3:2), 以及 1024x1024 (1:1)。
不进行“Clip Skip”操作,即 Clip Skip = 1。
采样器和步数:采用 “euler_ancester” 采样器(sampler),该组合在 webui 里称为 Euler A。在 7 CFG Scale 上采样 28 步。
仅需要使用模型本身,而不使用精炼器(Refiner)。
使用基底模型 vae 或 sdxl-vae。
2 特殊用法
2.1 泛风格化
0.7 版本归纳了若干相似插画画风,引入了泛风格触发词。泛风格触发词各代表一种常见动漫插画画风类别。
请注意,泛风格触发词并不一定符合其词义指代的美术含义,而是经过重新定义的特殊触发词。
2.2 角色
0.7 版本对强化训练了角色。部分角色触发词的还原度已经能够达到 lora 的效果,且能够很好地将角色概念与其本身的着装分离。
角色触发方式为 角色名 \(作品\)。例如,触发动画《赛博朋克:边缘行者》的女主角露西则使用 lucy \(cyberpunk\);触发游戏《原神》中的角色甘雨则使用 ganyu \(genshin impact\)。这里,“lucy” 和 “ganyu” 为角色名,“\(cyberpunk\)” 和 “\(genshin impact\)” 则为对应角色的作品出处,括号使用斜杠"\"转义以防止被解释为提示词加权。对于部分角色,出处并非必要。
角色触发词请参照 selected_tags.csv · SmilingWolf/wd-v1-4-convnext-tagger-v2 at main (huggingface.co)。
在使用中,若仅靠单个角色触发词无法完全还原角色,则需要在提示词中添加该角色的主要特征。
角色触发词通常不会携带角色本身的着装特征,若要添加角色着装,则需要在提示词中添加衣物名。例如,游戏《碧蓝航线》中角色圣路易斯 ( st. louis \(luxurious wheels\) \(azur lane\) ) 的衣装触发可使用 silver evening gown, plunging neckline。类似地,您也能对任何角色添加其他角色的衣装标签。
2.3 质量标签
0.7 版本的质量和美学标签经过正式训练,在提示词中尾随它们将影响生成图像的质量。
0.7 版本正式训练并引入了质量标签,质量标签分为六个等级,由好到坏分别为:amazing quality, best quality, high quality, normal quality, low quality 和 worst quality.
2.4 美学标签
0.7 版本起引入了美学标签,描述图像的特殊美学特征。
2.5 风格融合
您可以将一些样式合并到您的自定义样式中。 “合并”实际上意味着一次使用多种风格触发词。 例如,chun-li, amazing quality, (by yoneyama mai:0.9), (by chi4:0.8), by ask, by modare, (by ikky:0.9).
一些技巧:
控制风格的权重和顺序来调整最终风格。
尾随而非前置到提示词上。
3 注意事项
使用 SDXL 支持的 VAE 模型、文本嵌入(embeddings)模型和 Lora 模型。注意:sd-vae-ft-mse-original 不是支持 SDXL 的 vae;EasyNegative、badhandv4 等负面文本嵌入也不是支持 SDXL 的 embeddings;
对于 0.61 及以下版本:生成图像时,强烈推荐使用模型专用的负面文本嵌入(下载参见 Suggested Resources 栏),因其为模型特制,故对模型几乎仅有正面效果;
每个版本新增触发词将在当前版本效果相对较弱或不稳定。
IV 训练参数
以 SDXL1.0 为底模,使用大约 2w 张自己标注的图像在 5e-6 学习率,循环次数为 1 的余弦调度器上训练了约 100 期得到模型 A。之后在 2e-7 学习率,其余参数相同的条件下,训练得到模型 B。将模型 A 与 B 混合后得到 AIDXLv0.1 模型。
其他训练参数请参照英文版本的介绍。
V 特别鸣谢
算力赞助:感谢 @捏Ta 社区(捏Ta (nieta.art))提供的算力支持;
数据支持:感谢 @秋麒麟热茶(KirinTea_Aki Creator Profile | Civitai) 和 @风吟(Chenkin Creator Profile | Civitai)提供的大量数据支持;
没有它们就不会有 0.7 版本。
VI 更新日志
2023/08/08:AIDXL 使用与 AIDv2.10 完全相同的训练集进行训练,但表现优于 AIDv2.10。AIDXL 更聪明,能做到很多以 SD1.5 为底模型无法做到的事。它还能很好地区分不同概念,学习图像细节,处理对 SD1.5 来说难于登天的构图,几近完美地学习旧版 AID 无法完全掌握的风格。总的来说,它拥有比 SD1.5 更高的上限,我会继续更新 AIDXL。
2024/01/27:0.7 版本新增了大量内容,数据集大小是上一版本的两倍以上。
为了得到令人满意的标注,我尝试了很多新的标签处理算法,例如标签排序、标签分层随机化、角色特征分离等等。项目地址:Eugeoter/sd-dataset-manager (github.com);
为了使训练可控,且更加服从我的意愿,我基于 Kohya-ss 制作了特制的训练脚本;
为了掌控不同世代的模型的融合过程,我开发了一些启发式的模型融合算法;为了使模型达到足够的风格化,我放弃了通过融合文本编码器和UNET的OUT层来提高模型的稳定和美学,因为这会伤害模型的风格。
为了筛选和过滤数据,我训练了一个水印检测模型、一个图像分类模型、一个美学评分模型,来帮助我清洗数据。
VII 赞助我们
如果您喜欢我们的工作,欢迎通过 Ko-fi(https://ko-fi.com/eugeai) 赞助我们,以支持我们的研究和开发,感谢您的支持!
Appendix / 附录
A. Special Trigger Words List / 特殊触发词列表
Art style trigger words: Click me
Painting style trigger words: flat color, clean color, celluloid, flat-pasto, thin-pasto, pseudo-impasto, impasto, realistic, photorealistic, cel shading, 3d
flat color: Flat colors, using lines to describe light and shadow
平涂:平面色彩,使用线条和色块描述光影和层次
clean color: Style between flat color and flat-pasto. Simple and tidy coloring.
具有简洁色彩的平涂,介于 flat color 和 flat-pasto 之间
celluloid: Anime coloring
平涂赛璐璐:动漫着色
flat-pasto: Nearly flat color, using gradient color to describe lighting and shadow
接近平面的色彩,使用渐变描述光影和层次
thin-pasto: Thin contour, using gradient and paint thickness to describe light, shadow and layers
细轮廓勾线,使用渐变和颜料厚度描述光影和层次
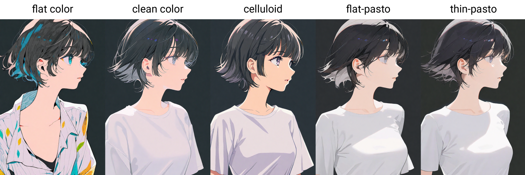
pseudo-impasto:Use gradients and paint thickness to describe light, shadow and layers
伪厚涂 / 半厚涂:使用渐变和颜料厚度描述光影和层次
impasto:Use paint thickness to describe light, shadow and gradation
厚涂:使用颜料厚度描述光影和层次
realistic
写实
photorealistic:Redefined to a style closer to the real world
相片写实主义:重定义为接近真实世界的风格
cel shading: Anime 3D modeling style
卡通渲染:二次元三维建模风格
3d

Aesthetic trigger words:
beautiful
美丽
aesthetic: slightly abstract artistic sense
唯美:稍微抽象的艺术感
detailed
细致
beautiful color: subtle use of color
协调的色彩:精妙的用色
lowres
messy: messy composition or details
杂乱:杂乱的构图或细节
Quality trigger words: amazing quality, best quality, high quality, low quality, worst quality