Download
1 variant available

关于AI生成PVC手办的风险提示
尊敬的用户:
感谢您对我AI生成PVC手办模型的关注。为了避免有不法分子利用本模型AI技术生成PVC手办,并通过虚假宣传、欺骗等手段骗取用户定金。对此我郑重声明如下:
本模型仅用于AI生成技术学术交流我手办模型的AI技术仅用于生成PVC手办的设计图稿,并不涉及实物生产和销售。
请勿相信任何未经授权的销售:任何声称销售由本模型AI生成技术制作的PVC手办的行为均未获得授权,请广大用户提高警惕,谨防受骗。
风险提示:PVC手办的制作涉及多个环节,包括3D建模、材质选择、模具制作、注塑成型、上色等,每个环节都可能存在质量问题。请用户在购买PVC手办时务必选择正规渠道,仔细核对产品信息,并保留相关凭证。
维权建议:如您发现有商家利用本模型的AI技术进行欺诈行为,请及时向相关部门举报,并保留证据,以便追究其法律责任。其可通过AI-Generated Content Detection | Hive (hivemoderation.com) 这个网站鉴定图片是否为ai 生成
温馨提示
为了保障您的权益,建议您在购买PVC手办时注意以下几点:
选择正规渠道:尽量选择知名厂商或有良好口碑的商家进行购买。
查看产品信息:仔细核对产品材质、尺寸、制作工艺等信息,并查看高清图片。
索要发票:要求商家提供正规发票,以便日后维权。
保留聊天记录:与商家沟通时,建议保留聊天记录,以备不时之需。
使用Ai技术判断:遇到没有见过可疑的手办 最好通过AI-Generated Content Detection | Hive (hivemoderation.com)这个网站上传图片进行鉴定
免责声明
对于本模型对任何未经授权的第三方利用本模型AI技术进行的商业活动不承担任何责任。请用户自行甄别,谨慎购买。
4.0版本对中近距离场景 质感效果最佳 在中近距离可以不用开启面部修复插件 4.0版本对手指手部略微优化
The 4.0 version has the best texture effect for medium and close range scenes, and there is no need to open the facial repair plugin. The 4.0 version slightly optimizes the hand and fingers
注意‼️一定要使用我推荐参数
take care ‼️ Be sure to use my recommended parameters
新版本推荐使用参数(The new version of the recommended use parameters)
推荐参数(Recommended parameter):
采样方法(Sampler):
Euler :20~30步
Euler a: 20~30步
提示词引导系数(CFG Scale):3-7
人像人物分辨率(Character resolution):512x768, 768x768,512x1024
高清修复(Hires.fix):
放大算法(Amplification algorithm):Latent,4x-UltraSharp,
负面提示推荐(Negative):(low quality,simple background,worst quality:1.4),(bad anatomy),(inaccurate limb:1.2),head out of frame,bad composition,inaccurate eyes,extra digit,fewer digits,(extra arms,grey background:1.2),(watermark,text,logo,username,multiple moles,mole on body:1.2),
使用Latent设置(Using Latent Settings)

使用4x-UltraSharp设置(Use the 4x-UltraSharp setting)
高分迭代步数(High number of iteration steps):10~15
推荐参数设置(Recommended parameter setting)
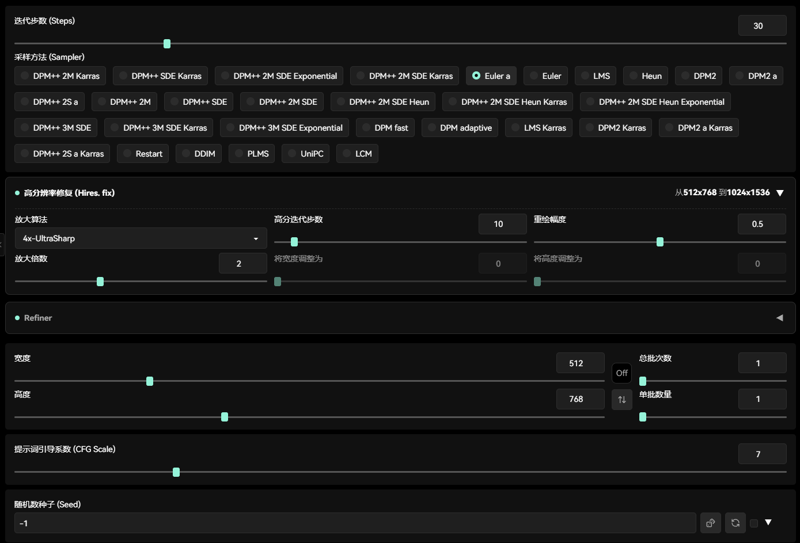
重绘幅度(Redraw amplitude):0.3~ 0.5
Clip Skip:2。
以上没提到的参数沿用上一个版本(The above mentioned parameters are used in a previous version)
-----------------------------------------------------------------------------------------
模型应用场景 Model application scenario
1.可以使用本模型可以搭配2d,2.5d,3d,风格lora直出PVC材质风格的 人物,物品 (这个和其他模型使用方法一致)
This model can be used with 2d, 2.5d, 3d, and style lora straight PVC material style characters and objects (this is the same as other models)
2.特定场景风格转换
本模型可以转换2d,2.5d,3d,的图片转换成PVC材质风格 这个可以应用于特定风格品牌设计及产品设计视觉设计的图片转换PVC材质画风
Style conversion of specific scenes
This model can convert 2d, 2.5d, 3d pictures into PVC material style. This model can be applied to the pictures of specific style brand design and product design visual design to convert PVC material painting style
2.0版本推荐使用参数(This parameter is recommended for version 2.0)
推荐参数(Recommended parameter):
采样方法(Sampler):
Euler :20~30步
Euler a: 20~30步
Restart:15~20步
DDIM:30步及以上
提示词引导系数(CFG Scale):3-7
人像人物分辨率(Character resolution):512x768, 768x768,512x1024
高清修复(Hires.fix):
放大算法(Amplification algorithm):R-ESRGAN 4x+Anime6b ,4x-UltraSharp,4x_SmolFace_200k
高分迭代步数(High number of iteration steps):10~15
重绘幅度(Redraw amplitude):0.3~ 0.5
Clip Skip:2。
负面提示推荐(Negative):(low quality, worst quality:1.4),(bad anatomy),(inaccurate limb:1.2),bad composition,inaccurate eyes,extra digit,fewer digits,(extra arms:1.2),(watermark,text,logo,username,multiple moles,mole on body,:1.2),
图像源和训练代码来自互联网,模型仅用于科研兴趣交流。如有侵权,请联系删除,谢谢。
The image source and training code are from the Internet, and the model is only used for scientific interest exchange. If there is infringement, please contact to delete, thank you.------------------------------------------------------------------------------------------
v1.0使用建议( v1.0 Recommendations of use):
建议用其他 lora 搭配这个模型使用的时候 lora权重建议在0.8左右 如果人物还没有PVC材质就把lora的权重在低一点
It is suggested that the weight of lora should be around 0.8 when using other LORAs with this model If the character does not have PVC material, put the weight of lora lower
建议起手提示词(Suggest a hand):
best quality,masterpiece,realistic,HDR,UHD,8K,best quality,masterpiece,Highly detailed,ultra-fine painting,physically-based rendering,extreme detail description,Professional,1girl,
如果画面输出比较糊 建议使用Ultimate SD upscale 放大进行放大
If the output is not very good, it is recommended to use Ultimate SD upscale amplification
------------------------------------------------------------------------------------------
推荐的参数(Recommended parameters):
采样方法(Sampler:):
Euler a: 20~30步。
DPM++ 2S a Karras:25~30步。
DPM++ SDE Karras:20~30步。
DPM++ 2M SDE Karras:20~40步。
提示词引导系数(CFG Scale):7
人像人物分辨率(Character resolution):512x768, 768x768,512x1024
高清修复(Hires.fix):
放大算法:R-ESRGAN 4x+Anime6b ,4x-UltraSharp,4x_SmolFace_200k
高分迭代步数:10~15
重绘幅度:0.3~ 0.5
Clip Skip:2。
负面(Negatives): (worst quality, low quality:2),monochrome, zombie, (interlocked fingers:1.2),
------------------------------------------------------------------------------------------
模型反馈请站内私信
图像源和训练代码来自互联网,模型仅用于科研兴趣交流。如有侵权,请联系删除,谢谢。
The image source and training code are from the Internet, and the model is only used for scientific interest exchange. If there is infringement, please contact to delete, thank you.