Download
1 variant available

This is the sharpest setting at 768*768 when using CUDA. I hope you guys also share your findings. I can't do extensive testing myself. F**k all those big bitc digger. I bought a 1660s when graphics cards were at their most expensive
and If anyone is interested, this is how I use it
https://github.com/WASasquatch/PPF_Noise_ComfyUI/wiki/Walkthrough
My English is not very good, but this issue can explain how the workflow works.
https://github.com/WASasquatch/was-node-suite-comfyui/issues/175
I believe this can bring some free quality improvements with almost no cost. Whether it gets better or not, you need to judge based on the images I generate. It takes me 120 seconds to generate a large image of 1024 pixels, so I need more people to experiment and find out which noise works best for the details in the image. That's why I keep releasing things
Thanks to @WAS
https://civitai.com/user/WAS/models
'WASasquatch on GitHub' for their contribution
old⬇
I heavily used my workflow for about a week and discovered many settings that affect the image. Previously, I was too lazy to write detailed instructions for the workflow. With the implementation of the mute switch, I have merged the two cores again, I will explain in detail how it works


It requires many nodes, so I recommend downloading the core and building it yourself
国人需要注意manager最近更新后拉取本地的节点列表时会报字符错,报错的那一行里”r“改成"rb"即可














Strongly recommend using the 2.1 model for low VRAM. There is no advantage to using 1.5 at the same resolution. The image above is from 1.5, and the one below is from 2.1


Some images have watermarks because I didn't even write prompts, and just generated them using WD14, so there are no negative prompts
This workflow allows a 1660 graphics card to generate a decent 1152*768 image with only 20 steps in one minute. I know this because I am using a 1660 graphics card. It takes at least 3 times longer for me to generate the same quality image in sdnext(Almost the same generation time, but facial repair, Hrfix and other operations are needed to achieve the image quality of Comfy).It is also not as controllable as my workflow
I believe the following things mentioned below are necessary settings for using this workflow. If you directly use my workflow, you need to set the 'neg_weight' of the 'pipeloader' node to 'down_weight,And I recommend using high clip strength for details Lora,Do not use the dpmpp-3m sampler, it broke eyes whan you have low VRAM. I have provided a sampler grid in the workflow file that can generate images better with low vram
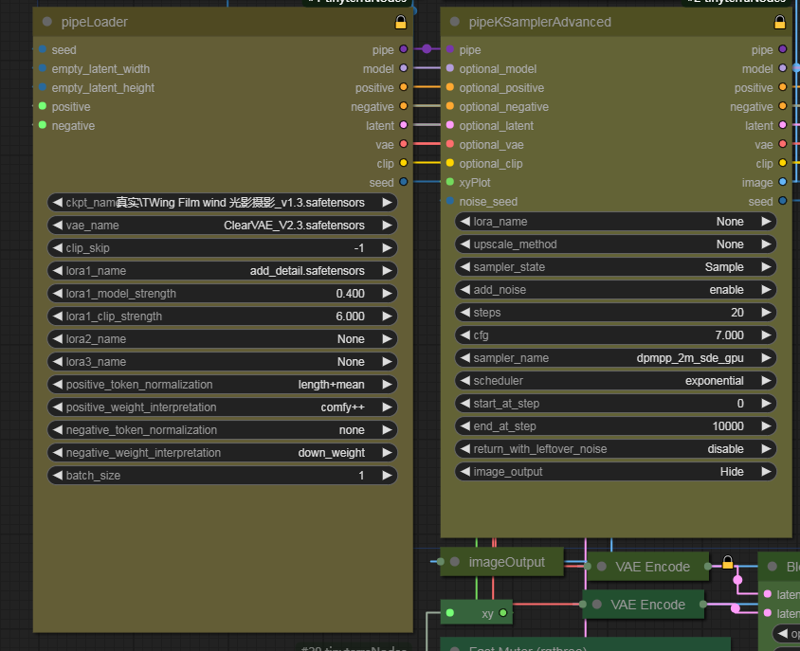
You need to expand this image output node and modify the path to save the image
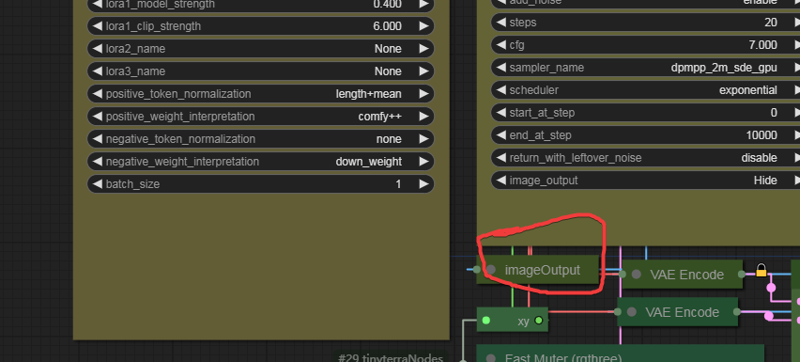
This switch controls the generation of all prompt words and some additional functionalities. I cannot use the wildcard __xxx*_ feature
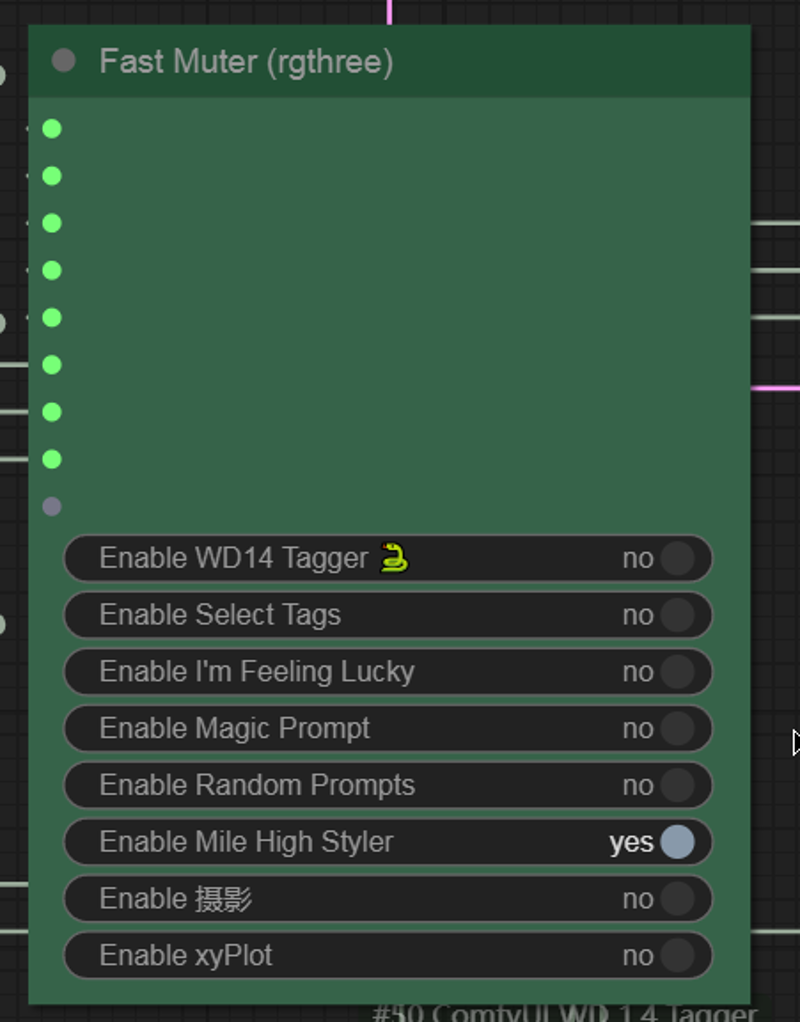
this noise node provides color to the image. When the v_max value is higher than 140, it results in an overly saturated green color. Additionally, this is where you can control the image's color. For example, if you want a redder image, you can increase the red_min parameter
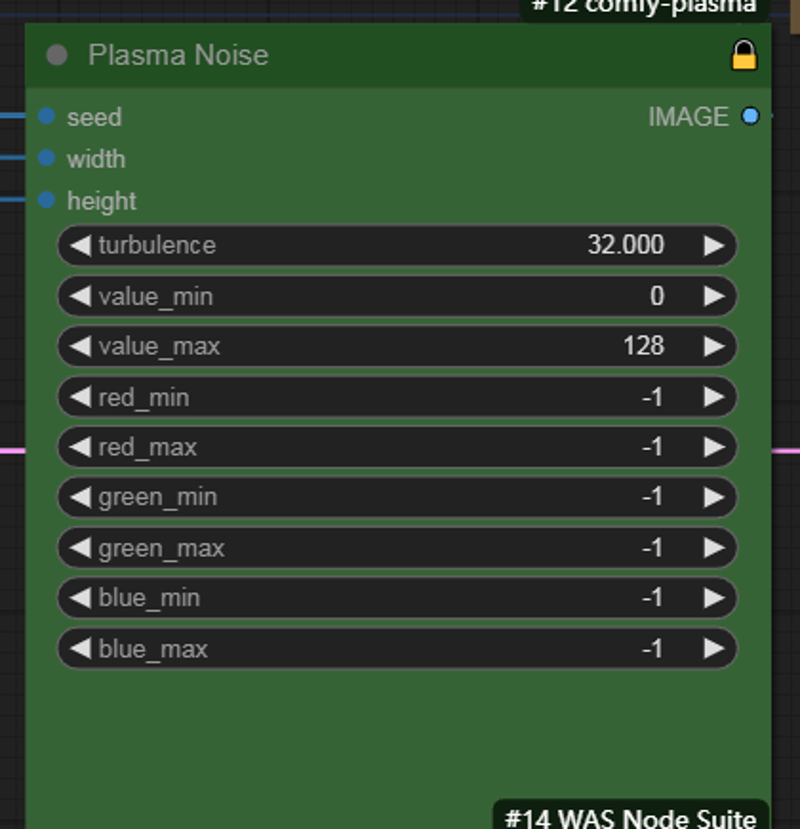
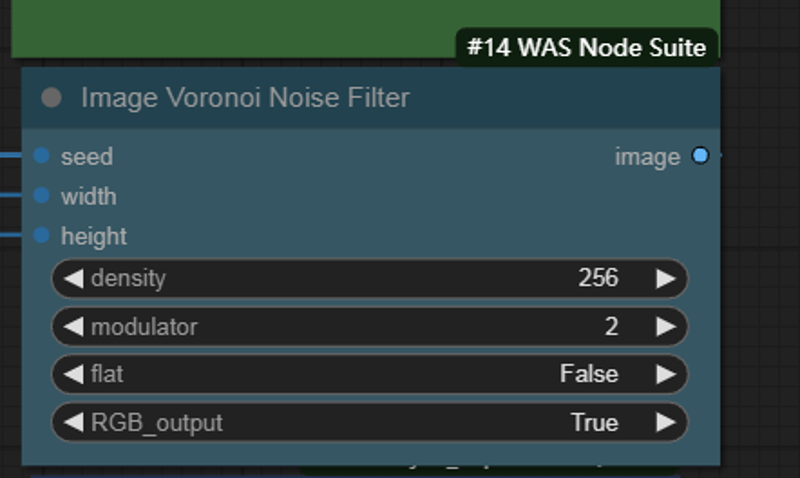
This noise node provides black and white,The modulator will create wrinkle details on the clothes . Keep the density at the highest level, and you can adjust the modulator according to your preference.You need to flip the width and height inputs. The input of this node is reversed


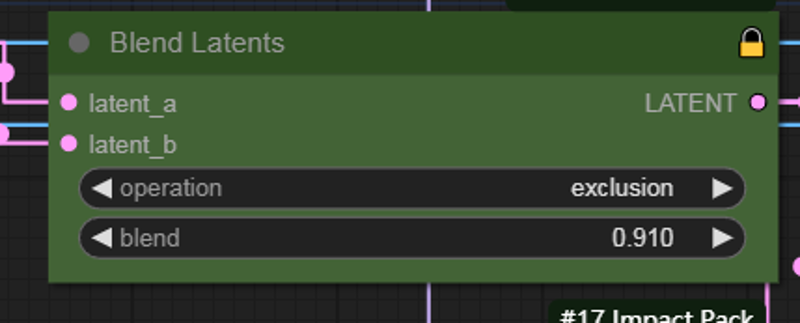
This node provides a blend mode for the two noise nodes, resulting in different images. By manually inputting the last digit X in the blend -0.00X, you can adjust the image details.can fix broken img some time ,Clicking the arrow generally generates a new image

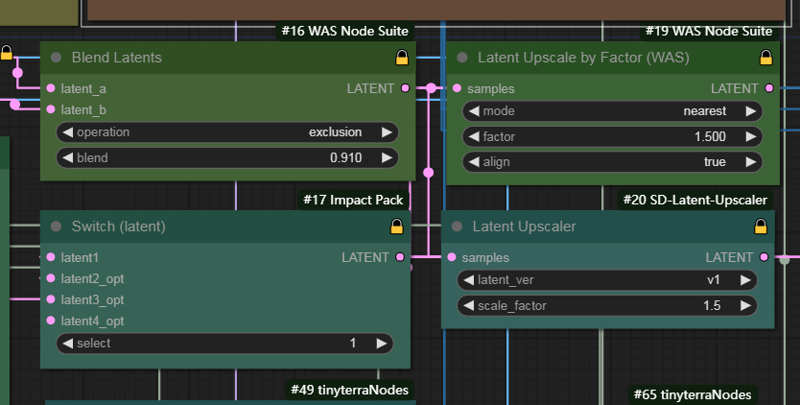
This switch, 1 is for original latent zoom, with 4 zooming modes that can provide a beautiful bokeh effect.2 is pixel upscal,3 is org latant no latent4

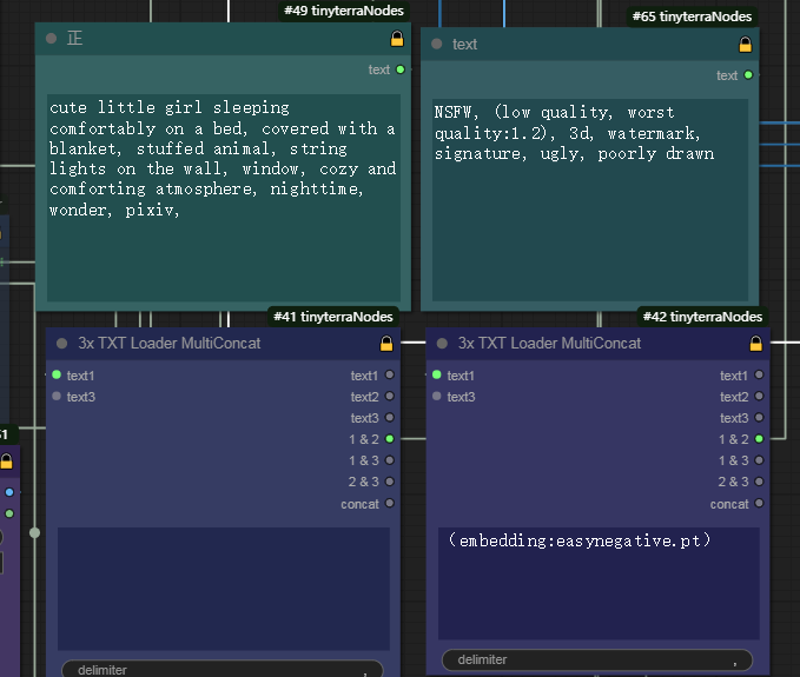
41 for pro 42 for neg embedding
49 for pro 65 for neg
nodes
It requires many nodes, so I recommend downloading the core and building it yourself
https://civitai.com/user/xww911/models
https://github.com/ltdrdata/ComfyUI-Impact-Pack
https://github.com/comfyanonymous/ComfyUI_experiments
https://github.com/WASasquatch/was-node-suite-comfyui
https://github.com/city96/SD-Latent-Upscaler
https://github.com/pythongosssss/ComfyUI-WD14-Tagger
https://github.com/tinyterra/ComfyUI_tinyterraNodes
https://github.com/Jordach/comfy-plasma
https://github.com/ssitu/ComfyUI_NestedNodeBuilder
https://github.com/pythongosssss/ComfyUI-Custom-Scripts
https://github.com/adieyal/comfyui-dynamicprompts
https://github.com/wsippel/comfyui_ws
https://github.com/rgthree/rgthree-comfy
终于写完了
old⬇
--The old workflow generated a 'RuntimeError: maximum recursion depth exceeded while calling a Python object' error, so I split the workflow.
旧版报错,不确定哪个节点,所以我拆开了翻译和潜空间控制。
翻译部分用到的节点---https://civitai.com/user/xww911/models
what this work flow can do(All images are generated by adjusting latent space parameters using Seed 1#):


1,Deeper-level HDR effect.


2,Adjusting parameters can achieve modifications in details

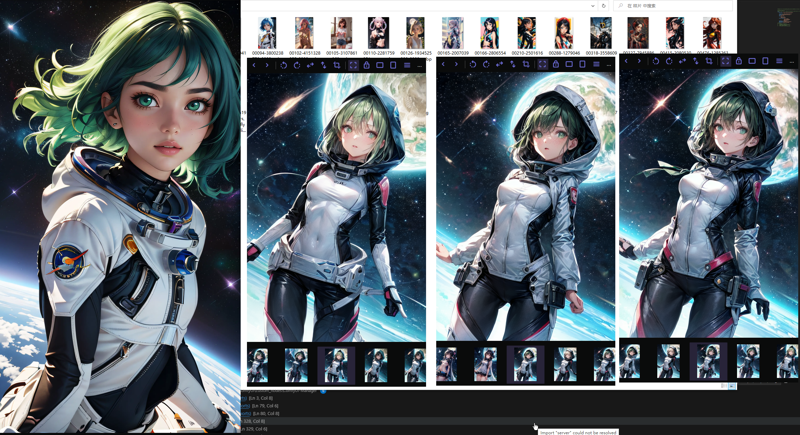

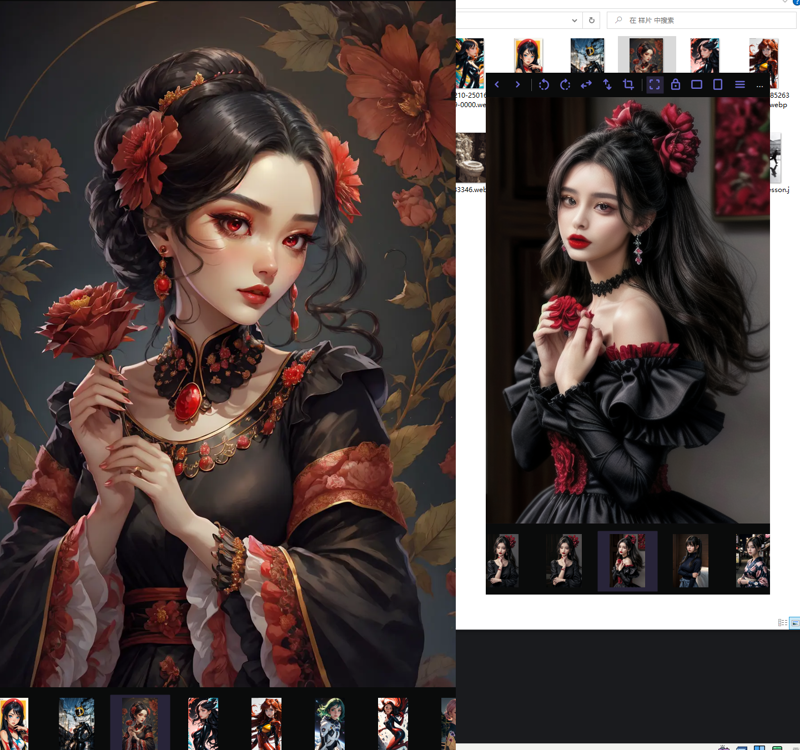
3,My proitive are mostly the results of WD1.4 inference, which can achieve results similar to the original image. It is easy to restore the desired image.


4,Change the color, change the details

5,More beautiful flares, blur, cleaner colors, and the ability to appear alongside black(This effect only occurs when using the original version of latent upscale)

6,we can fix bug now
I am trying to use this method on the 2.1 model, which allows me to generate larger images. However, my 1660S graphics card cannot test the XL model, so I hope someone can provide feedback
https://civitai.com/models/82098 --high clip strength 6-7
https://civitai.com/models/20793/was-node-suite-comfyui
https://civitai.com/models/87609/comfyroll-custom-nodes-for-comfyui
https://github.com/Jordach/comfy-plasma
old⬇
-工作流支持直接中文输入提示词自动翻译英语,两种图反推词,wildcard,自动补全和随机下mj图库的提示词,还有一个摄影的大包和风格的大包,都是别人的节点,让我合一个工作流了,提示词现在跟A4一样方便。
I discovered that noisy latent space can affect the generated images. So, with this workflow, I combined a colored noise latent space with Voronoi Diagram into one image, and then input it into the sampler to generate good images with stronger controllability. All of my samples were generated using the seed "1". This makes me love comfyui even more.
The images generated by this workflow on the sd2.1 model are not as good as those with 1.5. It might be an issue with the clip weights, but I'm not good at that. Since I have a 1660S graphics card, I cannot test the sdxl model. So, if you're interested, you can download my workflow and give it a try, or download the corresponding nodes to set it up yourself.The main working nodes require these three packages.
https://civitai.com/models/20793/was-node-suite-comfyui
https://civitai.com/models/87609/comfyroll-custom-nodes-for-comfyui
https://github.com/Jordach/comfy-plasma
I think we need an automatic mute function for unconnected nodes.