Updated: Apr 30, 2025
base modelDownload
1 variant available
fp16 SafeTensor
Illustrious-XL-v2.0.safetensors
Half precision, best balance (pruned) • 6.46 GB
Verified: a year ago


License:
Illustrious License
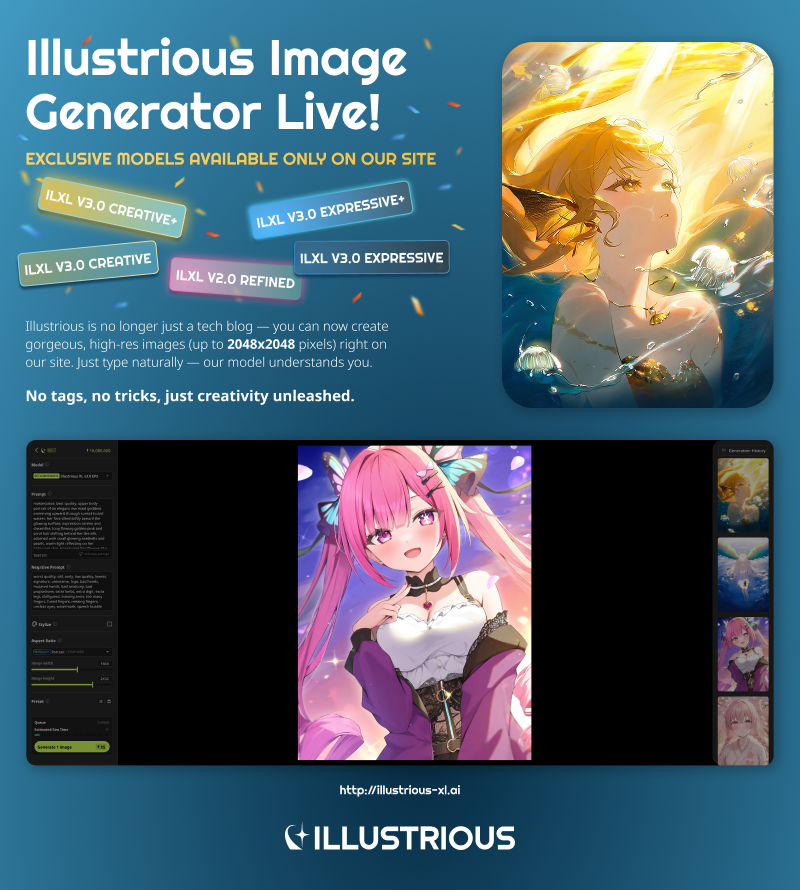 Check out our website to see what we’ve been working on and explore our latest model!
Check out our website to see what we’ve been working on and explore our latest model!
→ https://www.illustrious-xl.ai/
We’re excited to share that you can now generate images directly with our Illustrious XL models on our official site: [illustrious-xl.ai]. We’ve launched a full image generation platform featuring high-res outputs, natural language prompting, and custom presets — plus, several exclusive models you won’t find on any other hub. Explore our updated model tiers and naming here: [Model Series]. Need help getting started? Check out our generation user guide: [ILXL Image Generation User Guide].
Before we dive into the 2.0 model description, we owe you all an apology for the radio silence. We weren’t slacking off - we were cooking up something big. Over the past few weeks, we’ve been not only refining Illustrious but also building our very own site. Now, we have a home where you can get the latest insights on Illustrious, our training techniques, updates, and more.
From now on, all updates will be posted directly on our site!
For the v2.0 model’s technical details, check out: Illustrious XL Tech Blog
Stay in the loop with our latest releases and updates at: illustrious-xl.ai
Oh, and one more thing - we’re gearing up to showcase our models’ high-res capabilities and enhanced prompt applications soon, so keep an eye out in Q2 2025!
Illustrious XL 2.0: Increased robustness for better fine-tuning capabilities
In this version, the dataset has increased drastically, including major focus on animations & natural language focus – with updated dataset, until 2024-08. The model has performed best finetuning stability in our internal tests – with highest TrueSkill rating(among v1-v2) in external demo evaluation.
We want to note that we consider the compatibility & finetuning capability the most important feature of our baseline model. The model itself is not trained with aesthetic set / and we tried our best to debias the potential biases in model, for better overall performance.
Thus, we release ‘untuned’ base version, which should work as better merging / training bases. With release of the models, we also showcase example LoRA adapters, which is widely compatible across versions with recent character knowledges.
Natural Language Handling
The model itself is highly compatible with natural language sentences – it is far more
robust, it is less likely to generate multiple views or nonsense outputs.Generate a highly detailed anime-style illustration of a young man floating serenely
above a sprawling, futuristic cityscape. The boy has dark, messy hair and piercing blue
eyes. He's wearing a long, flowing white coat over dark, streamlined clothing – think a
mix of traditional Japanese garments and futuristic techwear. His expression is calm
and confident, almost detached. He is surrounded by a faint, glowing aura of light,
possibly blue or white.
Below him is a vast sci-fi city, filled with towering skyscrapers, holographic advertisements, and flying vehicles. The city should have a vibrant color palette – neon blues, purples, and pinks contrasting with darker metallic structures. There should be a sense of depth and scale, with buildings receding into the distance. The overall atmosphere should be epic and awe-inspiring, suggesting a powerful and mysterious character overlooking a technologically advanced world. Focus on dynamic lighting and detailed textures to create a visually stunning image. persona 3, masterpiece
High & Low Resolution supports
V2.0 supports 512~1536 resolutions. It is trained max 1:10 (or, 10:1) aspect ratio, with width / height multiples of 32.analogous colors, scenery, forest, masterpiece, black theme, dark, no lighting, night,
black background
Below is the 2x2 grid generation in 512x512 resolution:
1girl, solo, natsuiro matsuri, selfie, saturated, masterpiece, jirai kei, naughty smile,
dark, very dark, black theme, masterpiece, black, high contrast, sketch, monochrome
Negative prompt: worst quality, bad quality
Steps: 28, Sampler: DPM++ 2S Ancestral CFG++, Schedule type: Normal, CFG scale:
2.5, Seed: 1934035447, Size: 1824x1248 (NOTE CFG scale should be 6.5 in recent
implementations)
The models are capable for extreme high resolution generation more stably, with
higher denoising strength, which is important for stable detail generations. Below is an
example with 8MP img2img process:
We are also analyzing how to tweak the sampler schedule for better detail generations
– we will try our best to showcase the results.
Finally, we note the definite future plan for the model releases. We have decided to make model release sequentially, in three stage manner:
A. Exclusive
B. Early access
C. Open source
We will also continue to train & release the future model series, including DiT based
models.
Safety Guidelines
The model can be controlled by optional “rating” levels, described as explicit / questionable / sensitive / general
The alternative tokens, such as “adult content”, “r-18”, “nsfw”, “explicit material”, “sfw”, “safe for work” works for moderation.
Generative models can sometimes result biased, unintended outcomes. Users are required to generate and control the materials in responsible manner.
If you appreciate Illustrious’s evolution and are anticipating upcoming model releases, rlease consider leaving a like or comment. Your feedback is invaluable, and we deeply
appreciate your continued interest and support. Thanks!