Download
1 variant available
bf16 SafeTensor
ERA (Esthetic Retro Anime)_v2.1.safetensors
BF16, good balance (pruned) • 3.97 GB
Verified: 3 years ago



Сombined model of the 90s and 80s and now 00s
I restored my PATREON (or rather created a new one with the permission of patreon), if someone wants to support I posted there all my new models and LORAs, which were paid on BOOSTY in one archive. I will be glad if you even subscribe to patreon for free, I will know that you care about my work and you want to see updates.
About v5.0:
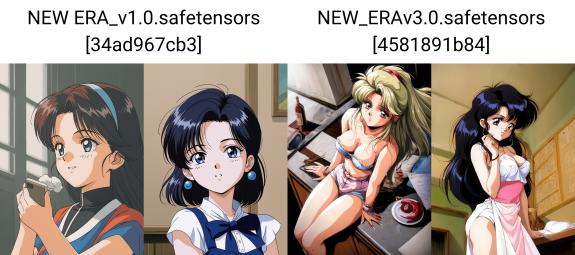
It was decided to implement the model based on NAI-XL, a crazy leap in quality compared to the latest LORA. Since the model is easy to fine-tune, it has improved detailing of the environment, eyes, improved anatomy, fingers, variety in clothing, and, importantly, reduced contrast, that is, if in version 3.0 the contrast was very high and it was difficult to use additional lora, it was necessary to use cfg scale 2.5, now cfg scale with the same contrast is about 4, which gives a reserve for using additional LORA.
When using Latent (nearest-exact) scaling, there are much fewer artifacts (sometimes they are absent altogether), which indicates a significant increase in quality and improvement of anatomy (when scaling, anatomy is much more often preserved within the correct limits)
workflow (just copy settings, everything except negative prompts, the best option is written below):
 link to image
link to image
About v6.3 & 6.69:
finally, it took a bit longer because I was redoing the fine tuning and training the lora to improve this model (and also all my webui broke after reinstalling python and I had to fix it all)
I want to say right away that this model is not made on epsilon, but on v-pred. V-pred (velocity prediction) and epsilon (ε-prediction) are different mathematical approaches to parameterizing noise in diffusion models. Without going into details, for anime, with the right settings, vpred is better. But it has wild problems with image frying and slightly worse convergence at zero SNR (and vpred should be used at 0 SNR). I solved the problems with strong contrast and color loss with the right settings for v-parameterization, completely disabling SNR, automatically adjusting the noise instead of the fixed values used in SDXL, etc. It was not easy, because there is no actual data on the Internet, through trial and error and clear reading of scientific papers on v-pred I was able to understand some of the subtleties. In fact, the original NOOBAI with civitai is incorrectly trained, which is quite funny, considering the number of people who helped with the setup and training.
In fact, v-pred is terribly picky and not perfect, hopefully the development of hybrid approaches will remove the current limitations, but will require fundamental changes in the architecture of diffusion models.
Back to the models, why two versions? I noticed some deterioration in the detail of the faces and eyes (not much, but still important), so I decided to create version 6.69, initially training specialized lore to improve the faces and further adjust the anatomy, which has already reached a new level. But version 6.3 visually works better with shadows by about 5% in 70-75% of cases, which is not significant for many, but for me it matters, so I just give you the choice. Version 6.69 is better in anatomy, 6.3 is slightly better with shadows. (first I'll post 6.3)
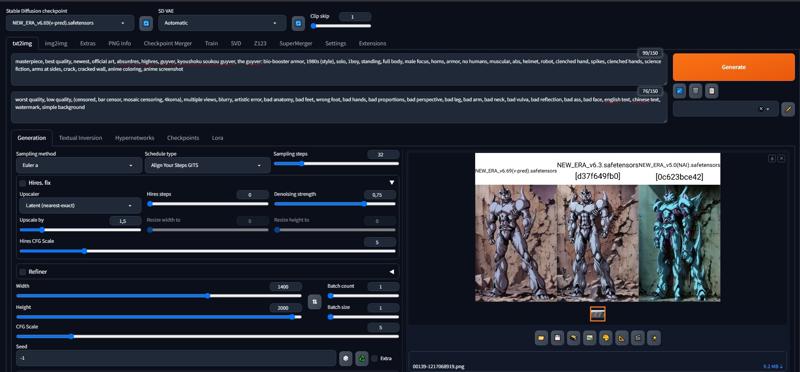
some comparisons of versions and 5.0 version (All art is made without upscaling at a resolution of 1024x1056):




 comparison of samplers:
comparison of samplers:

Now let's talk about how well this model copes with anatomy consistency at extreme resolutions, compared to older models, I achieved this by adding Rate of caption dropout and Network dropout 0.05, which increased the consistency several times. Resolution 1400x2000 (despite these results, this resolution is extreme and is not recommended, it is better to use Latent (nearest-exact) upscale)



My workflow
 Prompts in front: masterpiece, best quality, newest, official art, absurdres, highres
Prompts in front: masterpiece, best quality, newest, official art, absurdres, highres
Negative Prompts: worst quality, low quality, (censored, bar censor, mosaic censoring, 4koma), multiple views, blurry, artistic error, bad anatomy, bad feet, wrong foot, bad hands, bad proportions, bad perspective, bad leg, bad arm, bad neck, bad vulva, bad reflection, bad ass, bad face, english text, chinese text, watermark, simple background
The negative prompts are standard, using all the bad anatomical things from the danbooru site, except for one - simple background, I noticed that vpred models really like to simplify, this negative helps and improves the overall detailing.
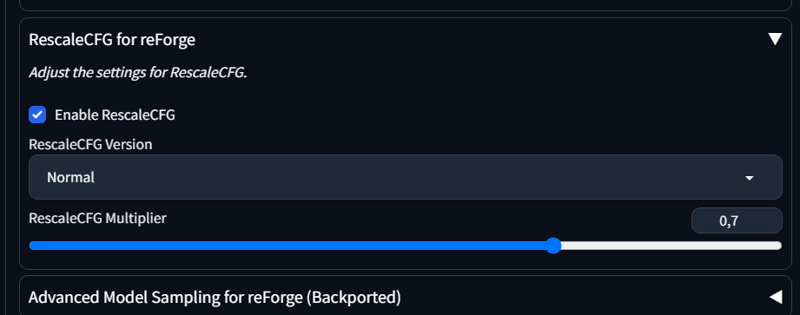
RescaleCFG is no longer needed. Now you can work calmly in comfi, forge, reforge and even standard automatic1111.
Remember, vpred models really like detailed descriptions, use booru tags from the danbooru website, regular 1girls work, but the picture is simplified and standardized as much as possible, this is inevitable in these models, epsilon models are more diverse in this regard, but lose in everything else (absolutely in everything).
If you haven't already, install the "sd-webui-tagcomplete" extension. It displays autocompletion hints for recognized tags from "image booru" boards such as Danbooru, which are primarily used for browsing Anime-style illustrations.
CFG Scale - any, no more problems with excessive contrast. You can set 5-7 (standard values)
oh yeah, almost forgot, i added quite a lot of full hd images from studio ghibli anime from the 80s 90s and 00s, so now you can create art in the style of this studio. Including widescreen images began to turn out with much better anatomy.
added anime:
hotaru no haka
tonari no totoro
sen to chihiro no kamikakushi
howl no ugoku shiro
tenkuu no shiro laputa
NEW_ERA_v7.1 (NAI V-PRED) or PATREON (new level of retro art, much better than versions 6.3 and 6.69, more stable, more beautiful, easier to implement)
















NEW ERA 4.0 (ILLUSTRIOUS-XL) / SDXL / LORA




 NEW ERA v1.0 (SDXL / PONY DIFFUSION version combining almost all my popular models with an emphasis on retro anime)
NEW ERA v1.0 (SDXL / PONY DIFFUSION version combining almost all my popular models with an emphasis on retro anime)
P.P.S. new model Anime Screencap / LORA / PONY DIFFUSION on Boosty


I made a video on how to achieve the same quality or just repeat my art
perfect negative prompts (i just used all the bad prompts from danbooru):
Negative prompt: worst quality, low quality, (censored, bar censor, mosaic censoring, 4koma), multiple views, blurry, artistic error, bad anatomy, bad feet, wrong foot, bad hands, bad proportions, bad perspective, bad leg, bad arm, bad neck, bad vulva, bad reflection, bad ass, bad face, english text, chinese text, watermark, simple background
retro artstyle - the main retro token, present in almost all trained images and gives different results in the 80s-90s
1990s \(style\) - a very strong marker that significantly changes the style of the model
1980s \(style\) - finally had a strong impact on the final result
2000s \(style\) - much better than before
anime screenshot, anime coloring - two strong tokens, works great, makes the image look like screenshots from anime, can be used both together for improvement and separately
photo background - makes the environment realistic, leaving the characters in anime style (modified for this model)
don't forget to write at the beginning of the hints: masterpiece, best quality
artists:
by urushihara satoshi
by danmakuman
by kitazume hiroyuki
by kawarajima kou
by kotobuki tsukasa
by hirano toshihiro
new
by mikimoto haruhiko
by kajishima masaki
by saotome nanda
by hakumai gen
P.S. 7.9V (based on 1.5)