Type | |
Stats | 149 0 |
Reviews | (24) |
Published | Mar 20, 2025 |
Base Model | |
Training | Steps: 1,100 Epochs: 7 |
Usage Tips | Strength: 1 |
Trigger Words | kxsr |
Hash | AutoV2 467232963A |


KXSR Cinematic Chase Concept LorA for WAN 2.1 14B and 1.3B T2V
In collaboration with @machinedelusions [https://civitai.com/user/machinedelusions]
KXSR Labs presents:
This LoRA enables the creation of cinematic sequences featuring characters and imaginative scenery with fast-paced high-octane 'vehicle' chase scene action. The typical view will be from a near-isometric perspective with dynamic movement in horizontal aspect ratio generation. Can still create fun results at other aspect ratios/resolutions.
Use the trigger word "kxsr" to activate the model's specialized training.
Prompt Format
kxsr, [describe the vehicle] [ACTION-VERB HERE: rides/drives/speeds/drifts/etc] quickly, [describe the driver/characters/scene/environment of the world and other actions happening around them]
Example Prompts
kxsr, A futuristic car, resembling a DeLorean with neon accents, drives quickly through a desert landscape with planets in the sky. The driver wears VR goggles. The car transitions to a convertible, passes a green screen, and eventually floats over a lake with neon rings, showcasing a blend of futuristic and surreal elements.
=======================================
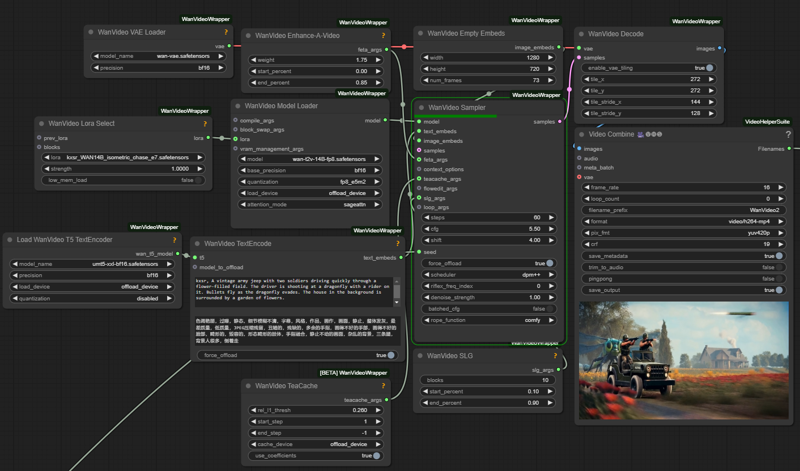
kxsr, A vintage army jeep with two soldiers driving quickly through a flower-filled field. The driver is shooting at a dragonfly with a rider on it. Bullets fly as the dragonfly evades. The house in the background is surrounded by a garden of flowers.
Recommended Settings
CFG: 5.0
Shift value: 4.0
LoRA strength: 1.0
~73 frames
720x1280 horizontal aspect ratio
Technical Details
Base model: WAN 2.1 14B + 1.3B Text2Video
Training dataset: 98 clips
Resolution: 1280 x 720 (horizontal format)
Frame count: 73 frames per clip
For optimal results, maintain these specifications during inference
This LoRA works best when you provide detailed descriptions of both the subject and the surrounding environment while following the prescribed format.
Screenshot shows my typical inference testing setup for lora evals: